This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
System Backup now requires the backup of privacy-related system documentation. 5 control family that more comprehensively addresses the risks associated with acquiring, developing, and maintaining information systems and components associated with third-party and vendor services, products, and supply chains. FedRAMP Rev.5
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This is particularly important for complex APIs that have many high cardinality inputs.
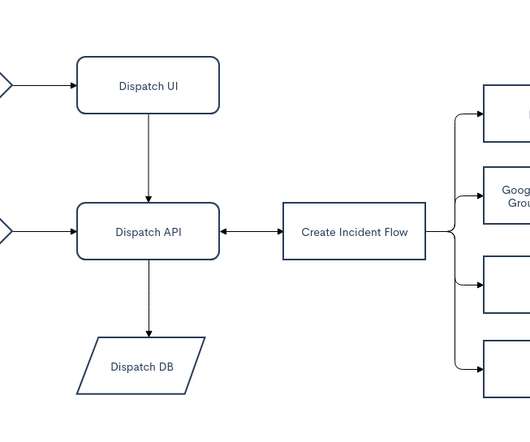
Here’s what we discussed so far: In Part 1 we explored how DevOps teams can prevent a process crash from taking down services across an organization. In doing so, they automate build processes to speed up delivery, and minimize human involvement to prevent error. Step 3 — xMatters alerts all the relevant resources.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. What is AIOps, and how does it work?
By virtue of the incredible volume, quality, scope (we actually go far beyond just application monitoring) and granularity of the data the platform provides, our customers have at their fingertips unparalleled insights about their systems, users, and so much more. Challenge: Monitoring processes for anomalous behavior.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This SLO enables a smooth and uninterrupted exercise-tracking experience.
It’s much better to build your process around quality checks than retrofit these checks into the existent process. NIST did classic research to show that catching bugs at the beginning of the development process could be more than ten times cheaper than if a bug reaches production. However, it’s not a unit test.
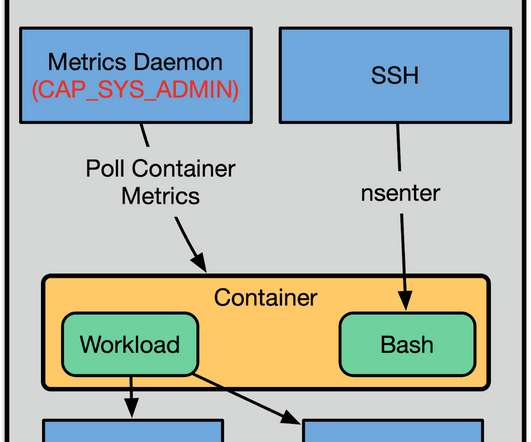
By Fabio Kung , Sargun Dhillon , Andrew Spyker , Kyle , Rob Gulewich, Nabil Schear , Andrew Leung , Daniel Muino, and Manas Alekar As previously discussed on the Netflix Tech Blog, Titus is the Netflix container orchestration system. It runs a wide variety of workloads from various parts of the company?—?everything
During the recent pandemic, organizations that lack processes and systems to scale and adapt to remote workforces and increased online shopping are feeling the pressure even more. Rethinking the process means digital transformation. What do you see as the biggest challenge for performance and reliability?
You apply for multiple roles at the same company and proceed through the interview process with each hiring team separately, despite the fact that there is tremendous overlap in the roles. Interviewing can be a daunting endeavor and how companies, and teams, approach the process varies greatly.
Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever. As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do.
The SEC cybersecurity mandate states that starting December 15 th , all public organizations are required to annually describe their processes for assessing, identifying, and managing material risks from any cybersecurity threats on a Form 10-K. Do material incidents on “third-party systems” require disclosure?
How does that apply when you need to debug AI-generated code, generated by a system that has seen everything on GitHub, Stack Overflow, and more? OReilly author Andrew Stellman recommends several exercises for learning to use AI effectively. So if you write code that is as clever as you can be, youre not smart enough to debug it.
Getting the information and processes in place to ensure alerts like this example can be organizationally difficult. However, Dynatrace can often miss crucial pieces of the puzzle because humans haven’t told it about whole processes occurring on the “human” side of the environment. Offline processes.
Migrating a message-based system from on-premises to the cloud is a colossal undertaking. If you search for “how to migrate to the cloud”, there are reams of articles that encourage you to understand your system, evaluate cloud providers, choose the right messaging service, and manage security and compliance.
Understanding, detecting and localizing partial failures in large system software , Lou et al., Partial failures ( gray failures ) occur when some but not all of the functionalities of a system are broken. Here are the key findings: Partial failures appear throughout the release history of each system, 54% within the last three years.
However, not all user monitoring systems are created equal. Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. Complex transaction and process monitoring that might have deeper dependencies. What is real user monitoring? The bottom line?
In software we use the concept of Service Level Objectives (SLOs) to enable us to keep track of our system versus our goals, often shown in a dashboard – like below –, to help us to reach an objective or provide an excellent service for users. Usual exceptions raised by our system that is now considered to be normal by Davis.
It represents the percentage of time a system or service is expected to be accessible and functioning correctly. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This SLO enables a smooth and uninterrupted exercise-tracking experience.
Figure 1 – Individual Host pages show performance metrics, problem history, event history, and related processes for each host. Right-sizing is an iterative process where you adjust the size of your resource to optimize for cost. To do that, organizations must evolve their DevOps and IT Service Management (ITSM) processes.
Review how the incident process was performed, tracking actions to be performed after the incident, and driving learning through structuring informal knowledge. Each of these steps has the incident commander and incident participants moving through various systems and interfaces. Perform Post Incident Review (PIR)? —?Review
The voice service then constructs a message for the device and places it on the message queue, which is then processed and sent to Pushy to deliver to the device. Sample system diagram for an Alexa voice command. Where aws ends and the internet begins is an exercise left to the reader.
Hosted and moderated by Amazon, AWS GameDay is a hands-on, collaborative, gamified learning exercise for applying AWS services and cloud skills to real-world scenarios. If your company is pursuing AWS certification for a team, AWS Certification Exam Vouchers make the process easier. Then this one’s for you. Machine learning.
Functional Testing Functional testing was the most straightforward of them all: a set of tests alongside each path exercised it against the old and new endpoints. The Not-so-good In the arduous process of breaking a monolith, you might get a sharp shard or two flung at you.
Werner Vogels weblog on building scalable and robust distributed systems. From financial processing and traditional oil & gas exploration HPC applications to integrating complex 3D graphics into online and mobile applications, the applications of GPU processing appear to be limitless. All Things Distributed. Comments ().
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Who did what and when?
Reliability, formally speaking, is the ability of a system to function under stated conditions for a period of time. Put simply, reliability means a system should work and continue working. assisting the responding service owners with understanding what systems are contributing to the incident Liaison?—?communicating
Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Even a conflict with the operating system or the specific device being used to access the app can degrade an application’s performance. APM’s many forms.
The process of gathering data will take some time, but we plan to periodically share statistics that we collect, like breakdowns of versions of database software being used or popular operating systems and architectures. The upcoming documentation release will explain this process in more detail.
Governance is not a “once and done” exercise. And we should define current best practices in the management of AI systems and make them mandatory , subject to regular, consistent disclosures and auditing, much as we require public companies to regularly disclose their financials.
The authors selected a set of diverse application workloads, as shown in the table below, and analysed their execution to find out the system call frequency and total execution time. A micro-benchmark suite, LEBench was then built around tee system calls responsible for most of the time spent in the kernel.
This ruling in itself raises many questions: how much creativity is needed, and is that the same kind of creativity that an artist exercises with a paintbrush? But reading texts has been part of the human learning process as long as reading has existed; and, while we pay to buy books, we don’t pay to learn from them.
The traditional EA role of documenting business processes and capabilities serves a purposes. It helps people to understand the complex systems they are working with. However, if nobody reads the documentation and it gets out of date quickly, it’s a tick-box exercise rather than a value creating one.
Ethics are an important part of human-computer interaction because they keep people at the heart of the design process. For example, try and recall the last time your team’s processes were audited for compliance against the company’s ethical standards. As UX practitioners, we know empathy is an important part of the design process.
This can be changed later using the pg_checksums utility, but that will be a painful exercise on a big database. cat /usr/lib/systemd/system/postgresql-14.service. That is where all “ALTER SYSTEM SET/RESET” commands keep the information. But another database might be an OLAP system.
While working as a DBA, we perform many regular tasks, and one of them is upgrading our database systems. The process using pg_upgrade is well documented , and you can easily find the instructions with little googling. When working with the upgrade exercise, the goal was to move from PostgreSQL 11 to PostgreSQL 12. Example case.
Teaching rigorous distributed systems with efficient model checking Michael et al., It describes the labs environment, DSLabs , developed at the University of Washington to accompany a course in distributed systems. Enabling students to build running performant versions of all of those systems in the time available is one challenge.
With these requirements in mind, and a willingness to question the status quo, a small group of distributed systems experts came together and designed a horizontally scalable distributed database that would scale out for both reads and writes to meet the long-term needs of our business. This was the genesis of the Amazon Dynamo database.
You might say that the outcome of this exercise is a performant predictive model. Second, this exercise in model-building was … rather tedious? You need to coordinate with stakeholders and product managers to suss out what kinds of models you need and how to embed them into the company’s processes. Your Job Has Changed.
Can an AI system be creative and, if so, what would that creativity look like? I’m skeptical about AI creativity, though recently I hypothesized that an AI system optimized for “hallucinations” might be the start of “artificial creativity.” We don’t know; a number of cases are in the legal system now. Or just derivative?
When a person clicked “submit,” the website would pass that form data through some backend code to process it—thereby sending an e-mail, creating an order, or storing a record in a database. Because most of those have been deployed in such a way that they are only communicating with trusted internal systems.
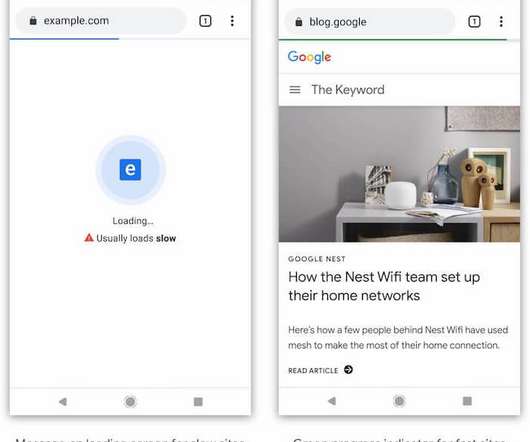
Google has announced plans for a new badging system that would let users know whether a website typically loads slowly. In a post detailing the thought process behind the planned feature, the Chrome team explains that “In the future, Chrome may identify sites that typically load fast or slow for users with clear badging ”.
Adrian Cockcroft outlines the architectural principles of chaos engineering and shares methods engineers can use to exercise failure modes in safety and business-critical systems. Kevin Stewart explores the people, processes, and cultural aspects that complement the cloud-native computing stack. Going (cloud) native.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content