This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Stranger Things imagery showcasing the inspiration for the Hawkins Design System by Hawkins team member Joshua Godi ; with art contributions by Wiki Chaves Hawkins may be the name of a fictional town in Indiana, most widely known as the backdrop for one of Netflix’s most popular TV series “Stranger Things,” but the name is so much more.
System Backup now requires the backup of privacy-related system documentation. 5 control family that more comprehensively addresses the risks associated with acquiring, developing, and maintaining information systems and components associated with third-party and vendor services, products, and supply chains. FedRAMP Rev.5
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This approach has a handful of benefits.
The Australian Cyber Security Center (ACSC) created the ISM framework to provide practical guidance and principles to protect organizations IT and operational technology systems, applications, and data from cyber threats. Deliver high-quality, cloud-native applications to accelerate innovation. Continuous compliance.
I recently joined two industry veterans and Dynatrace partners, Syed Husain of Orasi and Paul Bruce of Neotys as panelists to discuss how performance engineering and test strategies have evolved as it pertains to customer experience. What do you see as the biggest challenge for performance and reliability? Dynatrace news.
The new version of the application is deployed in the green environment and tested for functionality and performance. The alert comes with the full context of the issue, including errors caused, impacted systems, and level of severity. Both use the same database back-end and app configuration. Green then becomes the new production.
Many companies combine second-generation application performance management (APM) solutions to collect and aggregate data with machine-learning-based AIOps tools that add analysis and execution. These teams need to know how services and software are performing, whether new features or functions are required, and if applications are secure.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. SLOs are a valuable tool for organizations to ensure the health and performance of their applications. But how do you get started, and what are some service level objective examples?
Dynatrace is the leading Software Intelligence Platform, focused on web-scale cloud monitoring, delivering the richest, most complete data sets in the Application Performance Management market. These insights are critical to ensuring proactive application monitoring and optimal systemperformance.
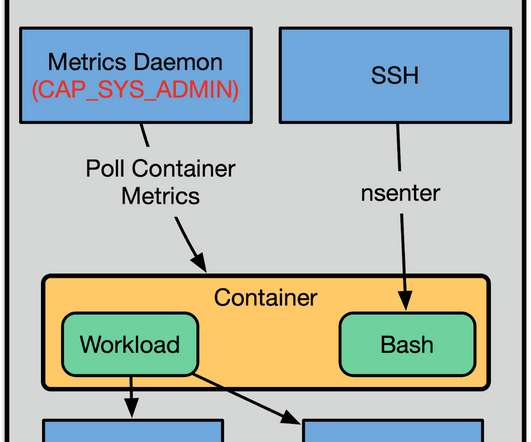
By Fabio Kung , Sargun Dhillon , Andrew Spyker , Kyle , Rob Gulewich, Nabil Schear , Andrew Leung , Daniel Muino, and Manas Alekar As previously discussed on the Netflix Tech Blog, Titus is the Netflix container orchestration system. It runs a wide variety of workloads from various parts of the company?—?everything
This post was co-authored by Jean-Louis Lormeau, Digital Performance Architect at Dynatrace. . In software we use the concept of Service Level Objectives (SLOs) to enable us to keep track of our system versus our goals, often shown in a dashboard – like below –, to help us to reach an objective or provide an excellent service for users.
How does that apply when you need to debug AI-generated code, generated by a system that has seen everything on GitHub, Stack Overflow, and more? OReilly author Andrew Stellman recommends several exercises for learning to use AI effectively. So if you write code that is as clever as you can be, youre not smart enough to debug it.
As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do. Vitality had to respond quickly to this change by signing up new partners and developing new ways of incorporating rewards.
As patient care continues to evolve, IT teams have accelerated this shift from legacy, on-premises systems to cloud technology to more build, test, and deploy software, and fuel healthcare innovation. That includes failures in parts of a system that occur at similar times and have a common root cause.
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. However, not all user monitoring systems are created equal. RUM gathers information on a variety of performance metrics. Performance testing based on variable metrics (i.e.,
Who performed it? The build system sends an automated notification to Dynatrace just before initiating a deployment on this VM. The build system adds valuable information, such as: The approver of this deployment and their contact details. Create a new VM for this exercise and install a Dynatrace OneAgent.
We then used simple thought exercises based on flipping coins to build intuition around false positives and related concepts such as statistical significance, p-values, and confidence intervals. In this post, we’ll do the same for false negatives and the related concept of statistical power.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Teams can build on these SLO examples to improve application performance and reliability. In this post, I’ll lay out five SLO examples that every DevOps and SRE team should consider.
Analyzing user experience to ensure uniform performance after migration. Performance efficiency. Some principles Microsoft provides across this area include: Choosing the right resources aligned with business goals that can handle the workload’s performance. Performance Efficiency. Operational excellence.
While this is a good way to get a rough estimate, your monthly cloud costs will indeed vary based on the amount of backups performed and your data transfer activity. This allows you to leverage external plugins and tools to better support your deployment and improve performance. ScaleGrid BYOC Pricing: $232/month. Reserved Instances.
Hosted and moderated by Amazon, AWS GameDay is a hands-on, collaborative, gamified learning exercise for applying AWS services and cloud skills to real-world scenarios. It also ensures your team shares common fluency in cloud best practices, which improves collaboration and helps your company achieve a higher standard of performance.
An analysis of performance evolution of Linux’s core operations Ren et al., For example: “Red Hat and Suse normally required 6-18 months to optimise the performance an an upstream Linux kernel before it can be released as an enterprise distribution”, and. Google’s data center kernel is carefully performance tuned for their workloads.
Perform Post Incident Review (PIR)? —?Review Review how the incident process was performed, tracking actions to be performed after the incident, and driving learning through structuring informal knowledge. Each of these steps has the incident commander and incident participants moving through various systems and interfaces.
For a more proactive approach and to gain further visibility, other SLOs focusing on performance can be implemented. However, it’s essential to exercise caution: Limit the quantity of SLOs while ensuring they are well-defined and aligned with business and functional objectives. In other words, where the application code resides.
We were pushing the limits of what was a leading commercial database at the time and were unable to sustain the availability, scalability and performance needs that our growing Amazon business demanded. Performant – The service would need to be able to maintain consistent performance in the face of diverse customer workloads.
Functional Testing Functional testing was the most straightforward of them all: a set of tests alongside each path exercised it against the old and new endpoints. Our responsibilities include extensive A/B testing on a wide variety of devices by building highly performant and often custom UI experiences.
Finally, the device receives the message, and the action, such as “Show me Stranger Things on Netflix”, is performed. Sample system diagram for an Alexa voice command. Where aws ends and the internet begins is an exercise left to the reader. The other main use case was RENO, the Rapid Event Notification System mentioned above.
As they move into the workforce, they need to deepen their knowledge and become part of a team writing a software system for a paying customer. Sorting is important, but not for the reasons a junior developer might think; almost nobody will need to implement a sorting algorithm, except as an exercise.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Performance monitoring.
When humans have the ability to perform magical feats of recall or calculation but not to create something profoundly new out of what they have learned, we dont call them geniuses. That is, the future belongs to t hose who are exercising the intelligence and insight that AI itself does not have. We call them idiot savants.
“That’s what the data says” is a variation—“the data” doesn’t say much if you don’t know how it was collected and how the data analysis was performed. That’s what GPS says”—well, GPS is usually right, but I have seen GPS systems tell me to go the wrong way down a one-way street. After all, who will ever need to implement sort() ?
Reliability, formally speaking, is the ability of a system to function under stated conditions for a period of time. Put simply, reliability means a system should work and continue working. CORE is a team consisting of Site Reliability Engineers, Applied Resilience Engineers, and Performance Engineers. Technical Sleuthing?—?assisting
Werner Vogels weblog on building scalable and robust distributed systems. This incredible power is available for anyone to use in the usual pay-as-you-go model, removing the investment barrier that has kept many organizations from adopting GPUs for their workloads even though they knew there would be significant performance benefit.
.”) So now you tweak the classifier’s parameters and try again, in search of improved performance. You might say that the outcome of this exercise is a performant predictive model. Second, this exercise in model-building was … rather tedious? How well did it perform? That’s sort of true.
Governance is not a “once and done” exercise. And we should define current best practices in the management of AI systems and make them mandatory , subject to regular, consistent disclosures and auditing, much as we require public companies to regularly disclose their financials.
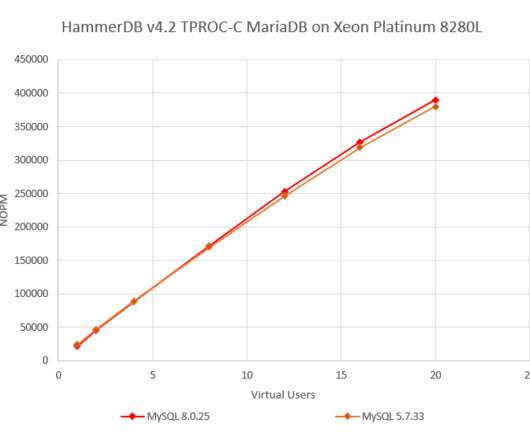
Predicting application performance is a difficult art, but an important one when choosing the target deployment environment. In this blog, we aim to call out some key considerations when trying to assess MySQL performance for your application. We will not concern ourselves with the raw throughput of workload.
High-performing technology organisations are characterised by decentralisation: autonomous teams, masters of the problem space, who own products or features. It helps people to understand the complex systems they are working with. designing systems that document themselves. Enterprise Architects are smart people.
One of the most important concepts in analysing database performance is that of understanding scalability. When a system ‘scales’ it is able to deliver higher levels of performance proportional to the system resources available to it. In this example, we will compare MySQL 5.7.33 and MySQL 8.0.25
While working as a DBA, we perform many regular tasks, and one of them is upgrading our database systems. There are some techniques to perform a PostgreSQL database upgrade, such as data dump and import, logical replication, or in-site upgrade using pg_upgrade. If all is good, perform the upgrade removing the –check flag.
Teaching rigorous distributed systems with efficient model checking Michael et al., It describes the labs environment, DSLabs , developed at the University of Washington to accompany a course in distributed systems. Enabling students to build running performant versions of all of those systems in the time available is one challenge.
The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner. but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. Why did something break? Who did what and when?
Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues. They reported a performance impact as low as 0.3% and finding over 1000 bugs, including security-critical ones. Making a choice was not optional, as the sage pointed out.
As such, one of the more common questions I get from my clients is whether or not their system will be able to endure an anticipated load increase. Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization.
With Enterprise Linux 7 nearing its end-of-life date, the Percona Monitoring and Management (PMM) team has done a significant update to the base operating system we build our images on top of. we’re making PMM publicly available on a newer base operating system based on Enterprise Linux 9 (EL9), specifically Oracle Linux 9.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content