This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? Real-time monitoring of user application and service interactions.
Fitness app : The fitness app should offer a response time of less than 500 milliseconds for exercise tracking and data recording. This SLO enables a smooth and uninterrupted exercise-tracking experience. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand.
From my experience, a month of monitoring is the optimal duration to gain statistically significant insights into “how my entity behaves with the configured SLO.” However, it’s essential to exercise caution: Limit the quantity of SLOs while ensuring they are well-defined and aligned with business and functional objectives.
Fitness app : The fitness app should offer a response time of less than 500 milliseconds for exercise tracking and data recording. This SLO enables a smooth and uninterrupted exercise-tracking experience. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand.
One is the currently-running production environment receiving all user traffic (let’s say the “blue” one), the other is a clone of it (“green”), but idle. Once the testing results are successful, application traffic is routed from blue to green. Response time for blue/green environment traffic.
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This can result in significant cost savings for high traffic applications. No problem.
Now, while we’ve been pushing these concepts in Keptn we haven’t explained well enough how to level-up your existing load testing scripts for better SLI monitoring and how to integrate them with Dynatrace in order to reap all the benefits of SLI-based Performance Analysis. A key concept in monitoring is proper tagging.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. But we can discuss common bottlenecks, how to assess them, and have a better understanding as to why proactive monitoring is so important when it comes to responding to traffic growth.
VPC Endpoints give you the ability to control whether network traffic between your application and DynamoDB traverses the public Internet or stays within your virtual private cloud. Integration with AWS CloudWatch, AWS CloudTrail, and AWS Config enables support for monitoring, audit, and configuration management.
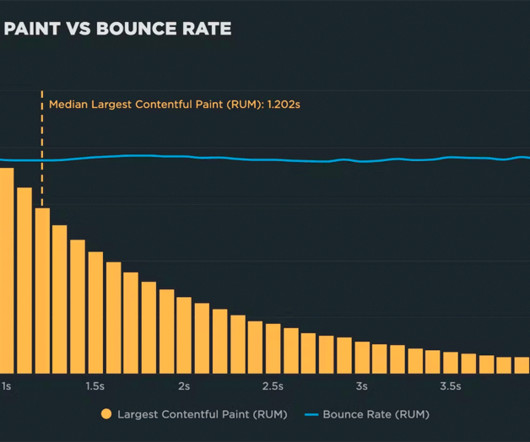
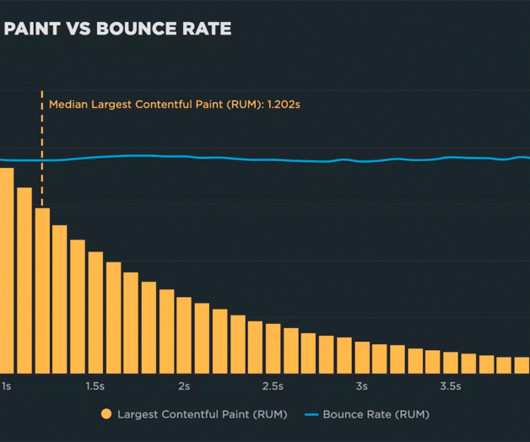
Background For this new investigation, I selected four sites that experience a significant amount of user traffic. For each site, I used a month's worth of RUM (real user monitoring) data to generate correlation charts. If you're new to performance, you might be interested in this synthetic and real user monitoring explainer.)
Each app was then executed on a physical mobile phone equipped with a custom OS and network monitor. The apps are driven using Android’s Application Exerciser Monkey which injects a pseudo-random stream of simulated user input events into the app (a UI fuzzer). most apps). most apps). Finding out how those apps leak data.
In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. Maybe that sounds scary, but one of the interesting perspectives this paper brings is to make you realise that it’s really not so different from any other change you might be rolling out into production (e.g.
Background For this new investigation, I selected four sites that experience a significant amount of user traffic. For each site, I used a month's worth of RUM (real user monitoring) data to generate correlation charts. If you're new to performance, you might be interested in this synthetic and real user monitoring explainer.)
A few noteworthy examples include: Realtime monitoring of Netflix streaming health which examines all of Netflix’s streaming video traffic in realtime and accurately identifies negative impact on the viewing experience with fine-grained granularity.
A few noteworthy examples include: Realtime monitoring of Netflix streaming health which examines all of Netflix’s streaming video traffic in realtime and accurately identifies negative impact on the viewing experience with fine-grained granularity.
A few noteworthy examples include: Realtime monitoring of Netflix streaming health which examines all of Netflix’s streaming video traffic in realtime and accurately identifies negative impact on the viewing experience with fine-grained granularity.
There are many possible failure modes, and each exercises a different aspect of resilience. It would take 5–10 minutes after the problem occurred to appear as a problem, then people have to notice and respond to emails or pager text messages, dial into a conference call, and log in to monitoring dashboards before any human response can start.
There are many possible failure modes, and each exercises a different aspect of resilience. It would take 5–10 minutes after the problem occurred to appear as a problem, then people have to notice and respond to emails or pager text messages, dial into a conference call, and log in to monitoring dashboards before any human response can start.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content