This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. Fitness app : The fitness app should offer a response time of less than 500 milliseconds for exercise tracking and data recording. This SLO enables a smooth and uninterrupted exercise-tracking experience. The Apdex score of 0.85
However, it’s essential to exercise caution: Limit the quantity of SLOs while ensuring they are well-defined and aligned with business and functional objectives. When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection.
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Real user monitoring limitations.
To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries. After some consultation with our backend teams, we determined the most effective way to group these metrics were by UI screen. Replay Testing Enter replay testing.
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This can result in significant cost savings for high traffic applications. No problem.
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Fitness app : The fitness app should offer a response time of less than 500 milliseconds for exercise tracking and data recording. This SLO enables a smooth and uninterrupted exercise-tracking experience.
Once Dynatrace sees the incoming traffic it will also show up in Dynatrace, under Transaction & Services. These tags will allow us to create dashboards, request attributes or calculate service metrics specifically for our application under test. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
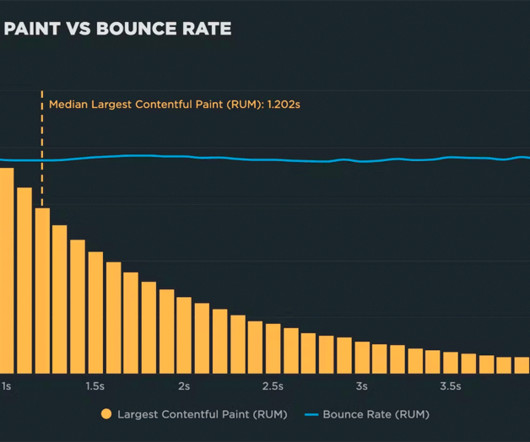
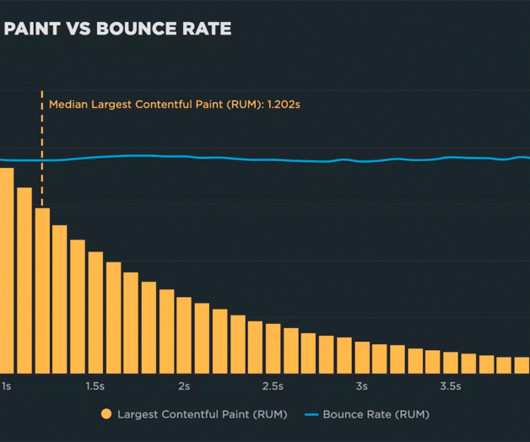
"I made my pages faster, but my business and user engagement metrics didn't change. The performance poverty line is the plateau at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. But we can discuss common bottlenecks, how to assess them, and have a better understanding as to why proactive monitoring is so important when it comes to responding to traffic growth.
Moreover, just like an A/B test, we’ll be collecting metrics while the experiment is underway and performing statistical analysis at the end to interpret the results. In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. Defining and running experiments.
"I made my pages faster, but my business and user engagement metrics didn't change. The performance plateau is the point at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
Where other systems may take over ten minutes to process metrics accurately, Mantis reduces that from tens of minutes down to seconds, effectively reducing our Mean-Time-To-Detect. Mantis Makes It Easy to Answer New Questions The traditional way of working with metrics and logs alone is not sufficient for large-scale and growing systems.
Where other systems may take over ten minutes to process metrics accurately, Mantis reduces that from tens of minutes down to seconds, effectively reducing our Mean-Time-To-Detect. Mantis Makes It Easy to Answer New Questions The traditional way of working with metrics and logs alone is not sufficient for large-scale and growing systems.
Where other systems may take over ten minutes to process metrics accurately, Mantis reduces that from tens of minutes down to seconds, effectively reducing our Mean-Time-To-Detect. Mantis Makes It Easy to Answer New Questions The traditional way of working with metrics and logs alone is not sufficient for large-scale and growing systems.
” The charts below show the improvements over time in the key offline metric, normalised discounted cumulative gain (NDCG), and in gains in bookings achieved online with the deployed models. Overall, the transition was “ one of the most impactful applications of machine learning at Airbnb.” Don’t be a hero, in the beginning.
There are many possible failure modes, and each exercises a different aspect of resilience. Collecting some critical metrics at one second intervals, with a total observability latency of ten seconds or less matches the human attention span much better. A resilient system continues to operate successfully in the presence of failures.
There are many possible failure modes, and each exercises a different aspect of resilience. Collecting some critical metrics at one second intervals, with a total observability latency of ten seconds or less matches the human attention span much better. A resilient system continues to operate successfully in the presence of failures.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content