This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. I can see from the screenshot above that TTFB is my most stable metrics—no one page appears to have particularly expensive database queries or API calls on the back-end.
Next, we launched a Mantis job that processed all requests in the stream and replayed them in a duplicate production environment created for replay traffic. The Mantis query language allowed us to set the percentage of replay traffic to process. We continued ramping up and eventually reached 100% replay.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. This approach has a handful of benefits.
Across the two days, there were sixteen new sessions – delivered for the first time – based on content derived from lab exercises developed and delivered by working with Dynatrace experts and our Partner communicate to showcase Dynatrace’s newest features. You can see a similar automation process on this GitHub repo.
It’s much better to build your process around quality checks than retrofit these checks into the existent process. NIST did classic research to show that catching bugs at the beginning of the development process could be more than ten times cheaper than if a bug reaches production. Metrics abstract you away from all details.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. What is AIOps, and how does it work?
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This SLO enables a smooth and uninterrupted exercise-tracking experience. or above for the checkout process.
Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. RUM gathers information on a variety of performance metrics. RUM is ideally suited to provide real metrics from real users navigating a site or application. What is real user monitoring?
Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever. As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do.
During the recent pandemic, organizations that lack processes and systems to scale and adapt to remote workforces and increased online shopping are feeling the pressure even more. Rethinking the process means digital transformation. Different teams have their own siloed monitoring solution.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
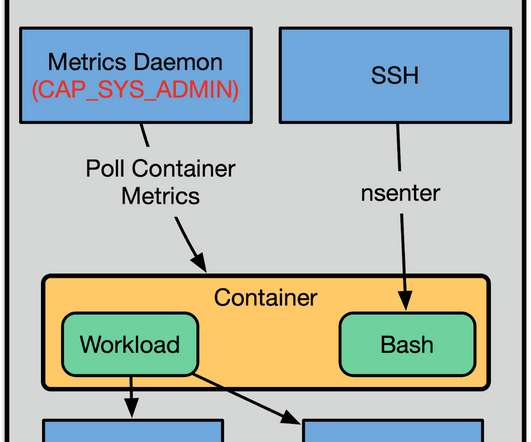
For example, the PID namespace makes it so that a process can only see PIDs in its own namespace, and therefore cannot send kill signals to random processes on the host. There are also more common capabilities that are granted to users like CAP_NET_RAW, which allows a process the ability to open raw sockets. User Namespaces.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis. Metric 2: number of requests in error. Let’s start by creating a dashboard to follow our metrics.
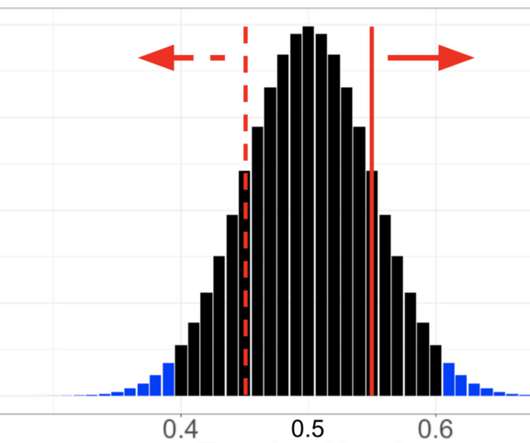
In Part 2: What is an A/B Test we talked about testing the Top 10 lists on Netflix, and how the primary decision metric for this test was a measure of member satisfaction with Netflix. This process generally starts by fixing the acceptable false positive rate. To build intuition, let’s run through a thought exercise.
Getting the information and processes in place to ensure alerts like this example can be organizationally difficult. While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer.
To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries. After some consultation with our backend teams, we determined the most effective way to group these metrics were by UI screen.
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Response time Response time refers to the total time it takes for a system to process a request or complete an operation. This SLO enables a smooth and uninterrupted exercise-tracking experience.
The voice service then constructs a message for the device and places it on the message queue, which is then processed and sent to Pushy to deliver to the device. Where aws ends and the internet begins is an exercise left to the reader. This initial functionality was built out for FireTVs and was expanded from there.
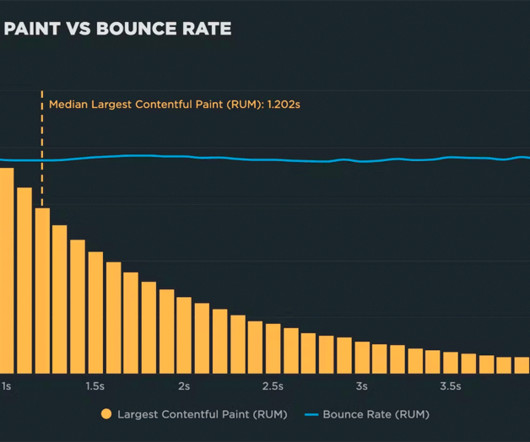
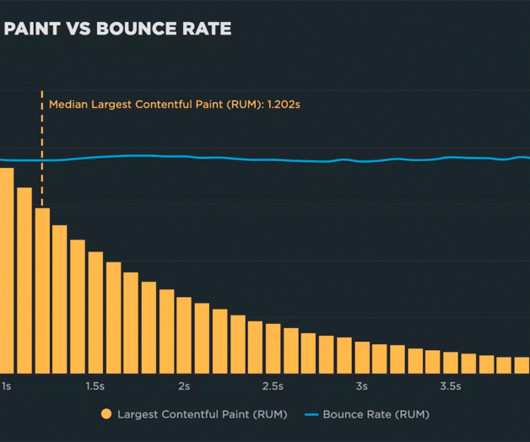
"I made my pages faster, but my business and user engagement metrics didn't change. The performance poverty line is the plateau at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. This may result in unnecessary troubleshooting exercises and finger-pointing, not to mention wasted time and money. Dynatrace news. What does APM stand for?
The process of gathering data will take some time, but we plan to periodically share statistics that we collect, like breakdowns of versions of database software being used or popular operating systems and architectures. Future releases may add additional metrics. Open-sourcing of the data We believe in open source at Percona.
The solution is proactive monitoring using time-lapse metrics monitoring like what you would get with Percona Monitoring and Management (PMM). Using time-lapse metrics monitoring, we can monitor overall disk consumption and the rate at which consumption occurs and then predict how much time we have left before we run out of space.
You might say that the outcome of this exercise is a performant predictive model. Second, this exercise in model-building was … rather tedious? You need to coordinate with stakeholders and product managers to suss out what kinds of models you need and how to embed them into the company’s processes.
Across the industry, this includes work being done by individual vendors, that they are then contributing to the standardization process so C++ programmers can use it portably. Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues.
Moreover, just like an A/B test, we’ll be collecting metrics while the experiment is underway and performing statistical analysis at the end to interpret the results. In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. On error rates.
In a project organization, this flow is spread across teams, functions, tools, processes and even external parties like vendors. Carving out the relevant pieces for each product is an iterative process. The more this process encroaches on the status quo, the more resistance you will encounter. . Measuring the Flow.
is astonishingly dense with delayed features, inadvertantly emphasising just how far behind WebKit has remained for many years and how effective the Blink Launch Process has been in allowing Chromium to ship responsibly while consensus was witheld in standards by Apple. Regardless, Safari 16.4 31st : Web Share changes Feb. Safari 16.4
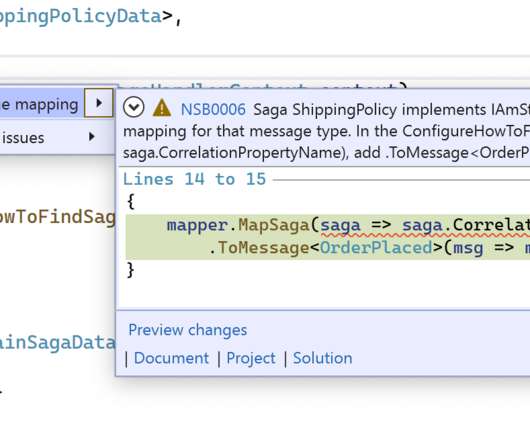
With a saga, a business process that would otherwise have been implemented as a clunky batch job 1 can be built in a much more elegant and real-time manner. Critical time metric In NServiceBus version 7.7, So if you had saga timeouts from a year ago (which is a normal part of some business processes!),
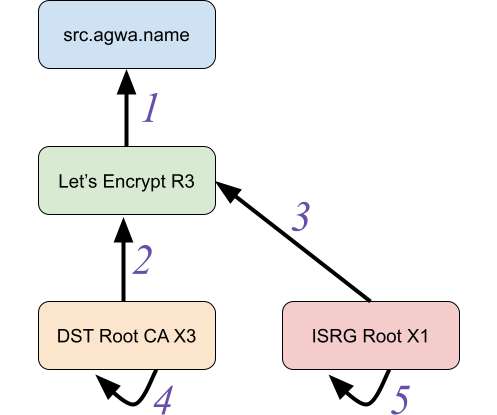
The end result is the first major update to BetterTLS since its first release : a new suite of tests to exercise TLS implementations’ certificate path building. And passing all of the tests in the BetterTLS test suite is a useful metric for establishing that confidence. What is Certificate Path Building?
There are many possible failure modes, and each exercises a different aspect of resilience. Staff should be familiar with recovery processes and the behavior of the system when it’s working hard to mitigate failures. Is the model of the controlled process looking at the right metrics and behaving safely?
If we accept the fact that Agile is a value system and not a set of mechanical processes, it stands to reason that there must be something different about the norms and behaviors of Agile managers vis-a-vis traditional managers. The metrics are only very rarely used to drive the team.
Site performance is potentially the most important metric. Having a slow site might leave you on page 452 of search results, regardless of any other metric. With all of this in mind, I thought improving the speed of my own version of a slow site would be a fun exercise. billion if the site slowed down by just one second.
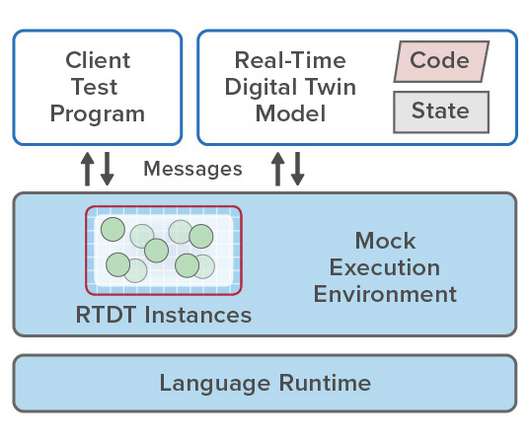
Simplifying the Development Process with Mock Environments. The key to meeting these challenges is to process incoming telemetry in the context of unique state information maintained for each individual data source. In contrast, real-time digital twins analyze incoming telemetry from each data source and track changes in its state.
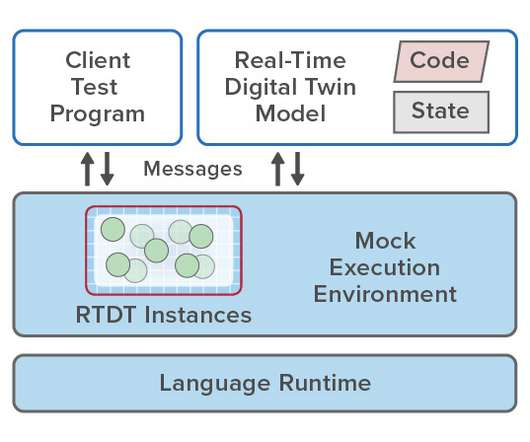
Simplifying the Development Process with Mock Environments. The key to meeting these challenges is to process incoming telemetry in the context of unique state information maintained for each individual data source. In contrast, real-time digital twins analyze incoming telemetry from each data source and track changes in its state.
The difference between “mediocre” and “great”, I believe, lies in the process. Rarely can you find inspiration accompanied by a thorough analysis of the process, research, and decision-making involved. That’s not to say that a “proper” design process is foolproof. Mediocre vs Great Dashboard Design. On top of “stealing” (ahem.
There are many possible failure modes, and each exercises a different aspect of resilience. Staff should be familiar with recovery processes and the behavior of the system when it’s working hard to mitigate failures. A resilient system continues to operate successfully in the presence of failures.
"I made my pages faster, but my business and user engagement metrics didn't change. The performance plateau is the point at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
To accomplish this goal, an organization needs to build internal processes and procedures that can operationalize a performance-first culture. According to Tim Kadlec : A performance budget is a clearly defined limit on one or more performance metrics that the team agrees not to exceed and that is used to guide design and development.
There are many possible failure modes, and each exercises a different aspect of resilience. Staff should be familiar with recovery processes and the behavior of the system when it’s working hard to mitigate failures. A resilient system continues to operate successfully in the presence of failures.
Instead, focus on understanding what the workloads exercise to help us determine how to best use them to aid our performance assessment. In the context of MySQL performance evaluation, it simulates a typical online transaction processing (OLTP) workload on your MySQL database. DISK METRICS sysstat_io_nvme0n1_avg_wait_ms 8.32
Tracking the processes to plan better. During a testing process, you need to track and plan the testing activities such as: Test planning Test scripts writing Test data creation and management Test versioning, review, and approvals Test case scheduling Test reporting. helps in having a clear picture of the testing process.
If you’re interested, I wrote a post a while back with some T-SQL code that scans the buffer pool and gives some metrics, using the DMV sys.dm_os_buffer_descriptors. Index_A has 200,000 pages at its leaf level, and Index_B has 1 million pages at its leaf level, so a complete scan of Index_B requires processing five times more pages.
They go on to report that 70% of the cases of these 7 chronic illnesses are preventable through lifestyle change: diet, exercise, avoiding cigarettes and what not. We are more tolerant to external risk factors because we don’t accumulate process debt or technical debt that makes it difficult for us to absorb risk.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content