This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Despite having to reboot Perform 2022 from onsite in Vegas to virtual, due to changing circumstances, we’re still set to offer just the same high-quality training. This means that despite not being in Vegas, our hands-on training (HOT) session attendees will see very minimal changes as we migrate to a virtual Perform 2022.
Well, that’s exactly what the Dynatrace University team did to support Dynatrace’s hands-on training (HoT) days at Dynatrace’s annual user conference Perform in Las Vegas. For the sessions, each student needed to have their own Dynatrace SaaS tenant to monitor and perform the hands-on exercises. Quite impressive! Automation.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Step-by-step guide: SRE-driven performance analysis with Dynatrace. Dynatrace news. Keptn uses SLO definitions to automatically configure Dynatrace or Prometheus alerting rules. This is what this blog is all about.
A couple of years ago, my first few days on a new web performance project were always slow going. Unless a client hires you to specifically improve the performance of one page, you’ll need a broad view of the whole site or application. Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. These include Quality-of-Experience(QoE) measurements at the customer device level, Service-Level-Agreements (SLAs), and business-level Key-Performance-Indicators(KPIs).
I recently joined two industry veterans and Dynatrace partners, Syed Husain of Orasi and Paul Bruce of Neotys as panelists to discuss how performance engineering and test strategies have evolved as it pertains to customer experience. What do you see as the biggest challenge for performance and reliability? Dynatrace news.
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. What is real user monitoring?
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Certain SLOs can help organizations get started on measuring and delivering metrics that matter. This SLO enables a smooth and uninterrupted exercise-tracking experience.
This post was co-authored by Jean-Louis Lormeau, Digital Performance Architect at Dynatrace. . You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Analyzing user experience to ensure uniform performance after migration. Performance efficiency. Understanding resource utilization for cost management. Reliability.
Many companies combine second-generation application performance management (APM) solutions to collect and aggregate data with machine-learning-based AIOps tools that add analysis and execution. These teams need to know how services and software are performing, whether new features or functions are required, and if applications are secure.
We then used simple thought exercises based on flipping coins to build intuition around false positives and related concepts such as statistical significance, p-values, and confidence intervals. the difference in metric values between Groups A and B?—?the The variability of the metric in the underlying population. Sample size.
For a more proactive approach and to gain further visibility, other SLOs focusing on performance can be implemented. However, it’s essential to exercise caution: Limit the quantity of SLOs while ensuring they are well-defined and aligned with business and functional objectives. In other words, where the application code resides.
As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do. Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever.
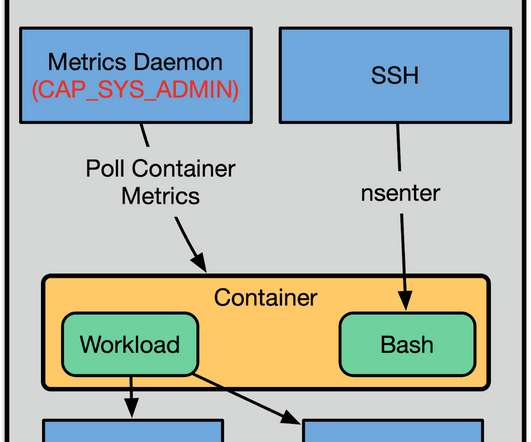
Titus is a multi-tenant system, allowing multiple teams and users to run workloads on the system, and ensuring they can all co-exist while still providing guarantees about security and performance. Various pieces of software used elevated capabilities for FUSE, low-level packet monitoring, and performance tracing amongst other use cases.
To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries. After some consultation with our backend teams, we determined the most effective way to group these metrics were by UI screen.
"I made my pages faster, but my business and user engagement metrics didn't change. How can I demonstrate the business value of performance to people in my organization?" If you've ever asked yourself any of these questions, then you could find the answers in identifying and understanding the performance poverty line for your site.
While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer. Who performed it? Create a new VM for this exercise and install a Dynatrace OneAgent.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Fitness apps : During the pandemic, fitness apps boomed.
Network metrics have been around for decades, but rendering metrics are newer. These are a few of the rendering metrics that currently exist. A brief history of performancemetrics. Metrics quantify behavior. Metrics quantify behavior. Gaps in today's performancemetrics. Speed Index.
While working on the integration with Juniper I managed to resolve several bugs and achieve a major performance improvement. The Juniper plugin is an ActiveGate Plugin written in Python, it consists of a script that connects to a Juniper Networks device and collects some facts and metrics about it. Part 1 – The code as it stood.
While this is a good way to get a rough estimate, your monthly cloud costs will indeed vary based on the amount of backups performed and your data transfer activity. This allows you to leverage external plugins and tools to better support your deployment and improve performance. ScaleGrid BYOC Pricing: $232/month. Reserved Instances.
Application performance monitoring (APM) is the practice of tracking key software application performancemetrics using monitoring software and telemetry data. Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Performance monitoring.
This greatly reduces the number of bugs and improves the overall health and performance of every application that uses the design system. We decided to track the number of uses of each component, the number of installs of the packages themselves, and how many applications were using Hawkins in production as metrics to determine success.
Finally, the device receives the message, and the action, such as “Show me Stranger Things on Netflix”, is performed. Where aws ends and the internet begins is an exercise left to the reader. Dynomite had great performance, but it required manual scaling as the system grew. Sample system diagram for an Alexa voice command.
So I thought it would be fun to spend some time poking around behind the scenes and give the site a holiday performance audit. Background For this performance audit, I looked at this synthetic test for the LEGO.com home page. (We The performance team is clearly doing a good job of fighting page bloat. Are images optimized?
or higher for a client, metrics will accumulate on the client automatically up to 1GB before any gaps in metrics appear once complete. or higher for a client, metrics will accumulate on the client automatically up to 1GB before any gaps in metrics appear once complete. If you’re running PMM 2.32.0
.”) So now you tweak the classifier’s parameters and try again, in search of improved performance. You might say that the outcome of this exercise is a performant predictive model. Second, this exercise in model-building was … rather tedious? How well did it perform? That’s sort of true.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. Unfortunately, this topic is more of an art than a science, given that there is really no foolproof algorithm or approach that can tell you exactly where you might hit a bottleneck with server performance.
Reading time 9 min When it comes to managing web performance, it’s vital to be proactive rather than reactive. To accomplish this goal, an organization needs to build internal processes and procedures that can operationalize a performance-first culture. The first step is to establish and implement web performance budgets.
Predicting application performance is a difficult art, but an important one when choosing the target deployment environment. In this blog, we aim to call out some key considerations when trying to assess MySQL performance for your application. We will not concern ourselves with the raw throughput of workload.
Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues. They reported a performance impact as low as 0.3% I wont lie: This is going to be a metric ton of work. and finding over 1000 bugs, including security-critical ones.
"I made my pages faster, but my business and user engagement metrics didn't change. How can I demonstrate the business value of performance to people in my organization?" If you've ever asked yourself any of these questions, then you could find the answers in identifying and understanding the performance plateau for your site.
The end result is the first major update to BetterTLS since its first release : a new suite of tests to exercise TLS implementations’ certificate path building. Java I didn’t evaluate JDKs other than OpenJDK, but the latest version of OpenJDK 11 actually performed quite well. BoringSSL BoringSSL performed similarly to OpenSSL.
Moreover, just like an A/B test, we’ll be collecting metrics while the experiment is underway and performing statistical analysis at the end to interpret the results. In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong.
A Value Stream Architecture (VSA) diagram can provide that visual cue: A Value Stream Architecture exercise maps the flow of value-creating and -protecting software delivery work across your toolchain that underpins your product value stream. Flow Metrics, from the Flow Framework®, define the spectrum of value creation in software delivery.
Site performance is potentially the most important metric. The better the performance, the better chance that users stay on a page, read content, make purchases, or just about whatever they need to do. Having a slow site might leave you on page 452 of search results, regardless of any other metric. Lighthouse.
Each person is responsible for the outcome because team performance is measured on collective output (specifically, stories in production) as opposed to the sum of individual output (tasks completed by individuals). One person who does a substandard job affects the performance of the entire team.
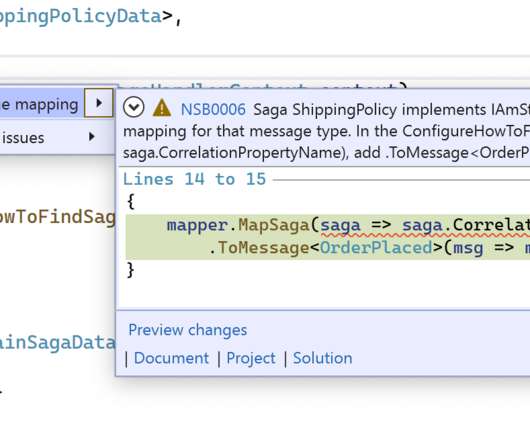
So the newest version of our testing framework now includes tools to perform saga scenario testing , which are more expressive than testing sagas with standard unit tests. Critical time metric In NServiceBus version 7.7, the performancemetrics in ServicePulse will reflect the new method of calculating critical time information.
as an (eventual) exercise of monopolistic power that held the web back for more than a decade? In early 2020, after months of background conversations and research, Mason Freed posted a new set of design alternatives , which included extensive performance research. But what if developers see behind the veil? But needs must.
That’s a bit alarming, because the Flow Metrics of several Fortune 100 companies now practicing value stream management (VSM ) in their software portfolios have revealed an acute resource scarcity in QA. Get together once a year for a value stream mapping exercise, and you’ll emerge with a list of potential improvement hypotheses. .
There are many possible failure modes, and each exercises a different aspect of resilience. Consider how controls could degrade over time, including change management, performance audits and how incident reviews could surface anomalies and problems with the system design. Memorial at Hawaiian native burial ground, Kapalua, Maui.
Traditional IT projects are mass economy-of-scale exercises: once development begins, armies of developers are unleashed. One solution often attempted is phased delivery of use cases: the traditional IT steps are still performed, only we make interim deliveries of code to a QA environment and execute functional tests against them.
Talking to users” is like exercising or eating healthy — everyone knows they should do more of it, but few actually do it. What would probably be more useful is having separate graphs for key metrics with clear labels, i.e. to introduce “extra complexity”. On top of “stealing” (ahem. People ignore design that ignores people”.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























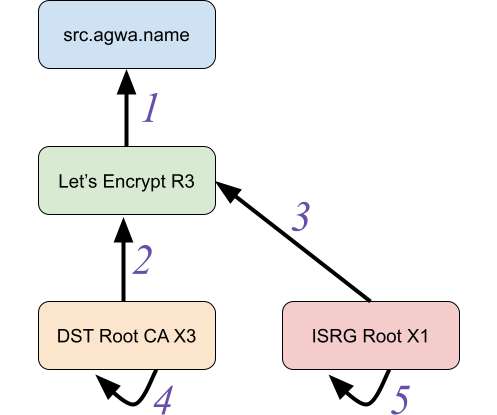












Let's personalize your content