This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. I can see from the screenshot above that TTFB is my most stable metrics—no one page appears to have particularly expensive database queries or API calls on the back-end.
We informed our engineering and business partners, including customer support, about the experiment and ramped up traffic incrementally while monitoring the success and error metrics through Lumen dashboards. We continued ramping up and eventually reached 100% replay. At this point we felt confident to run the replay traffic 24/7.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. The batch job creates a high-level summary that captures some key comparison metrics.
Across the two days, there were sixteen new sessions – delivered for the first time – based on content derived from lab exercises developed and delivered by working with Dynatrace experts and our Partner communicate to showcase Dynatrace’s newest features. Dynatrace AWS monitoring with CloudWatch metrics and metadata.
We have two types of time series data: metrics and vulnerability events. Metrics represent application events, and a subset of those that involve security issues are vulnerability events. Vulnerability events can also have an event sample that contains detailed information about the request that exercised a security vulnerability.
Attendees will have the same great Dynatrace experts teaching the sessions live via webcam (and we’d highly encourage you to turn on your webcam as well), the same virtual classroom to join and complete the hands-on exercises, and the same great content.
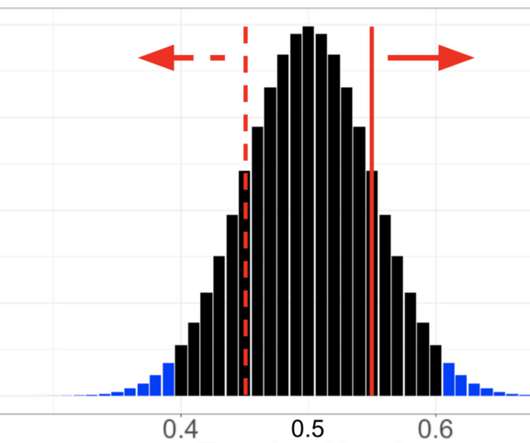
We then used simple thought exercises based on flipping coins to build intuition around false positives and related concepts such as statistical significance, p-values, and confidence intervals. the difference in metric values between Groups A and B?—?the The variability of the metric in the underlying population. Sample size.
They are rerun(in the best case) and thus defeating the whole purpose of this exercise while spending tons and tons of time/money/energy on this).nn> Metrics abstract you away from all details. Metrics abstract you away from all details. As soon as some process (like gathering metrics) becomes a goal (vs. A side note.
You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis. Metric 2: number of requests in error. Let’s start by creating a dashboard to follow our metrics.
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. Fitness app : The fitness app should offer a response time of less than 500 milliseconds for exercise tracking and data recording. This SLO enables a smooth and uninterrupted exercise-tracking experience.
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Real user monitoring limitations.
In Part 2: What is an A/B Test we talked about testing the Top 10 lists on Netflix, and how the primary decision metric for this test was a measure of member satisfaction with Netflix. To build intuition, let’s run through a thought exercise. But how do we know if we’ve made the right decision, given the results of the test?
As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do. Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever.
But AIOps also improves metrics that matter to the bottom line. With better data intelligence across the software development lifecycle, individuals in every role can exercise more autonomy and experience greater job satisfaction. Of all the AIOps benefits, however, the ultimate advantage is its business value.
In Dynatrace, tagging also allows you to control access rights (via Management Zones), filter data on dashboards or via the API as well as allowing you to control calculation of custom service metrics or extraction of request attributes. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. Using a data-driven approach to size Azure resources, Dynatrace OneAgent captures host metrics out-of-the-box to assess CPU, memory, and network utilization on a VM host.
To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries. After some consultation with our backend teams, we determined the most effective way to group these metrics were by UI screen.
All this complexity raises the bar for the end-user and application monitoring, and for many organizations, their existing tooling poses challenges such as: A disconnect from actual end-user experience and typical IT metric sources of logs, metrics, and traces. Different teams have their own siloed monitoring solution.
However, it’s essential to exercise caution: Limit the quantity of SLOs while ensuring they are well-defined and aligned with business and functional objectives. Data Explorer “test your Metric Expression” for info result coming from the above metric. In other words, where the application code resides.
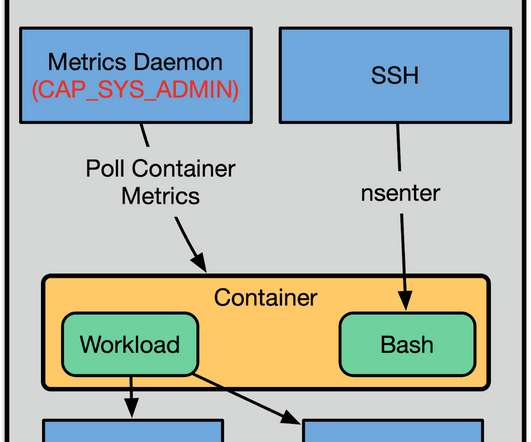
This, in turn, allows processes to exercise certain privileges without having any privileges in the init user namespace. We had a shared metrics daemon on the machine that reached in and polled metrics from the container. In addition to that, we could use our standard metrics daemons on the host.
While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer. Create a new VM for this exercise and install a Dynatrace OneAgent. Tag your host with demo: cpu_stress.
Network metrics have been around for decades, but rendering metrics are newer. These are a few of the rendering metrics that currently exist. A brief history of performance metrics. Metrics quantify behavior. Metrics quantify behavior. Gaps in today's performance metrics. Speed Index. Start Render.
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Fitness app : The fitness app should offer a response time of less than 500 milliseconds for exercise tracking and data recording. This SLO enables a smooth and uninterrupted exercise-tracking experience.
The Juniper plugin is an ActiveGate Plugin written in Python, it consists of a script that connects to a Juniper Networks device and collects some facts and metrics about it. After I call device.open , every service with “ metrics ” on its name should be executing at the same time, but they were not. Part 1 – The code as it stood.
This is especially apparent in the enterprise space, as these organizations have teams of database administrators managing their deployments and require the freedom to exercise their internal expertise over their clusters. Interested in BYOC, but don’t want SSH access? No problem. Learn more. Database Trends. Learn more.
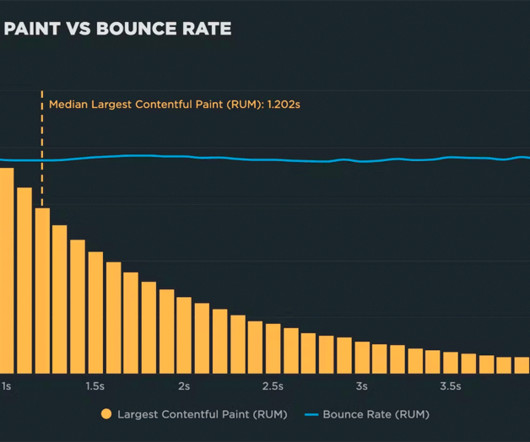
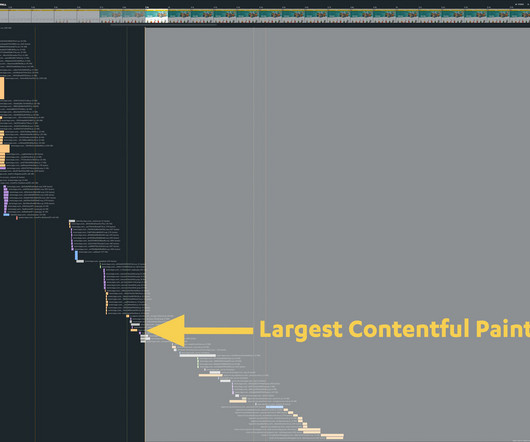
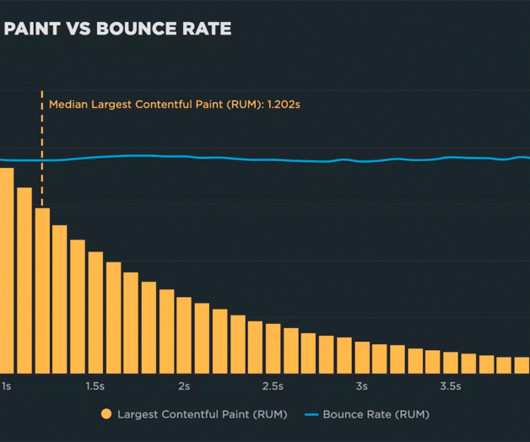
"I made my pages faster, but my business and user engagement metrics didn't change. The performance poverty line is the plateau at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
We decided to track the number of uses of each component, the number of installs of the packages themselves, and how many applications were using Hawkins in production as metrics to determine success. There is a definitive cost that comes with building out a design system no matter the route you take.
Where aws ends and the internet begins is an exercise left to the reader. The DeviceToDeviceManager is also responsible for observability, with metrics around cache hits, calls to the data store, message delivery rates, and latency percentile measurements. Sample system diagram for an Alexa voice command.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. This may result in unnecessary troubleshooting exercises and finger-pointing, not to mention wasted time and money. Dynatrace news. Application performance management.
MezzFS collects metrics on data throughput, download efficiency, resource usage, etc. We parallelize rerun jobs with Titus , Netflix’s container management platform, which allows us to exercise many hundreds of replay files in minutes. in Atlas , Netflix’s in-memory dimensional time series database.
or higher for a client, metrics will accumulate on the client automatically up to 1GB before any gaps in metrics appear once complete. or higher for a client, metrics will accumulate on the client automatically up to 1GB before any gaps in metrics appear once complete. If you’re running PMM 2.32.0
These articles will also help you understand how to opt out from the telemetry, how it is being sent to Percona, and how you can exercise your data owners’ rights. Future releases may add additional metrics. All the details about what we collect will be found in the help documents structure for involved Percona products.
The solution is proactive monitoring using time-lapse metrics monitoring like what you would get with Percona Monitoring and Management (PMM). Using time-lapse metrics monitoring, we can monitor overall disk consumption and the rate at which consumption occurs and then predict how much time we have left before we run out of space.
You might say that the outcome of this exercise is a performant predictive model. Second, this exercise in model-building was … rather tedious? That’s sort of true. But like the question about the role of the software developer, there’s more to see here.
Moreover, just like an A/B test, we’ll be collecting metrics while the experiment is underway and performing statistical analysis at the end to interpret the results. In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong.
A Value Stream Architecture (VSA) diagram can provide that visual cue: A Value Stream Architecture exercise maps the flow of value-creating and -protecting software delivery work across your toolchain that underpins your product value stream. Flow Metrics, from the Flow Framework®, define the spectrum of value creation in software delivery.
Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues. I wont lie: This is going to be a metric ton of work. And its work that I think some people dont expect C++ to ever be able to do.
The end result is the first major update to BetterTLS since its first release : a new suite of tests to exercise TLS implementations’ certificate path building. And passing all of the tests in the BetterTLS test suite is a useful metric for establishing that confidence.
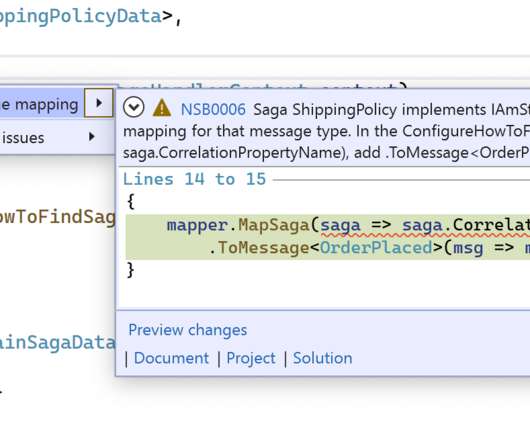
Unit tests have to call the saga’s Handle methods directly, without exercising any mapping expressions inside the ConfigureHowToFindSaga method, so you just had to hope really hard that your mappings were all correct. Critical time metric In NServiceBus version 7.7, There was also no way to test the ConfigureHowToFindSaga method.
It was easy - and very satisfying - to nerd out on the management metrics, creating forecasts of scope expansion and capacity and so forth. But one thing that distinguishes the Agile manager from the traditional manager is that the team drives the metrics. The metrics are only very rarely used to drive the team.
That’s a bit alarming, because the Flow Metrics of several Fortune 100 companies now practicing value stream management (VSM ) in their software portfolios have revealed an acute resource scarcity in QA. Get together once a year for a value stream mapping exercise, and you’ll emerge with a list of potential improvement hypotheses. .
A couple of things worth noting: All of the sites in the leaderboard sites are pretty speedy, so this is NOT a name-and-shame exercise. It shows how key metrics align with the rendering timeline (the filmstrip view at the top of the chart). The LEGO page actually starts to load visual content FASTER than most of the other pages.
There are many possible failure modes, and each exercises a different aspect of resilience. Is the model of the controlled process looking at the right metrics and behaving safely? Memorial at Hawaiian native burial ground, Kapalua, Maui.
"I made my pages faster, but my business and user engagement metrics didn't change. The performance plateau is the point at which changes to your website’s rendering metrics (such as Start Render and Largest Contentful Paint) cease to matter because you’ve bottomed out in terms of business and user engagement metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content