This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
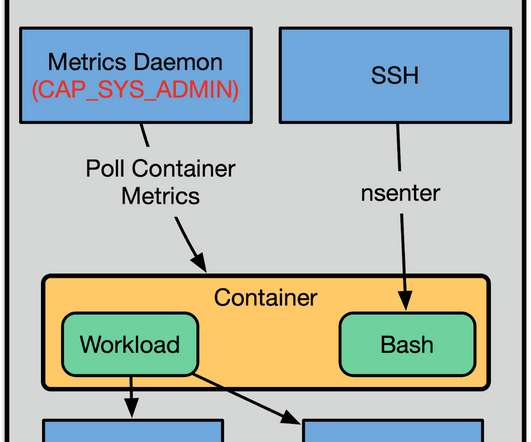
By Fabio Kung , Sargun Dhillon , Andrew Spyker , Kyle , Rob Gulewich, Nabil Schear , Andrew Leung , Daniel Muino, and Manas Alekar As previously discussed on the Netflix Tech Blog, Titus is the Netflix container orchestration system. It runs a wide variety of workloads from various parts of the company?—?everything
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. The availability of a computer system is the percentage of time its services are up during a period of time. Where to host your cloud database? Expert Tip.
In fact, he noted, unlimited priors or experience can produce systems with little-to-no generalization power (or intelligence) that exhibit high skill at any number of tasks. That is, the future belongs to t hose who are exercising the intelligence and insight that AI itself does not have. Their creations, not so much.
For the rest of us, if you really need that extra performance (maybe what you get out-of-the-box or with minimal tuning is good enough for your use case) then you can upgrade hardware and/or pay for a commercial license of a tuned distributed (RHEL). A second takeaway is this: security has a cost! Measuring the kernel. Headline results.
Werner Vogels weblog on building scalable and robust distributed systems. Now that our ability to generate higher and higher clock rates has stalled and CPU architectural improvements have shifted focus towards multiple cores, we see that it is becoming harder to efficiently use these computer systems. All Things Distributed.
As such, one of the more common questions I get from my clients is whether or not their system will be able to endure an anticipated load increase. Hardware considerations The first thing we have to consider here is the resources that the underlying host provides to the database. Let’s take a look at each common resource.
At the start of November I was privileged to attend HPTS (the High Performance Transaction Systems) conference in Asilomar. Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. PLOS’19.
Pre-publication gates were valuable when better answers weren't available, but commentators should update their priors to account for hardware and software progress of the past 13 years. Fast forward a decade, and both the software and hardware situations have changed dramatically. Don't like the consequences?
Are you ready to take your system assurance programme to the next level? In all cases we need to be able to carefully monitor the impact on the system, and back out if things start going badly wrong. Netflix’s system is deployed on the public cloud as complex set of interacting microservices.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
Picture taken by Adrian March 17, 2020 A resilient system continues to operate successfully in the presence of failures. There are many possible failure modes, and each exercises a different aspect of resilience. Hence, one way to reduce risk is to make systems more observable. The first technique is the most generally useful.
A resilient system continues to operate successfully in the presence of failures. There are many possible failure modes, and each exercises a different aspect of resilience. Hence, one way to reduce risk is to make systems more observable. This discussion focuses on hardware, software and operational failure modes.
A resilient system continues to operate successfully in the presence of failures. There are many possible failure modes, and each exercises a different aspect of resilience. Hence, one way to reduce risk is to make systems more observable. This discussion focuses on hardware, software and operational failure modes.
Instead, focus on understanding what the workloads exercise to help us determine how to best use them to aid our performance assessment. Therefore, before we attempt to measure our database performance, we should know the system or cloud instance to be tested in detail. Operating System: Ubuntu 22.04 Operating System: Ubuntu 22.04
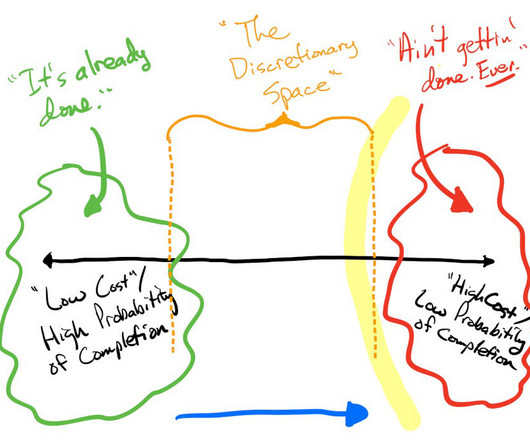
Even though that remediation task was pretty minor — tweaking some low-level hardware settings on each physical server and rebooting — and could have been done quickly enough, there was intense debate on whether it should be done. In practice (and I’ve done this exercise with teams), this spectrum can provide useful insight.
Because it utilizes multi-factor authentication, multi-layered hardware, and software encryption, the application offers its users a high degree of protection. The application is easily compatible with all the devices that use the Android operating system. Intuit, which is its parent business, oversees its operations. Expense Manager.
In some sense it's a confidence-management exercise. In both cases, the OS will task the browser team to heavily prioritise integrations with the latest OS and hardware features at the expense of more broadly useful capabilities — e.g. shipping "notch" CSS and "force touch" events while neglecting Push.
As the chart shows because we know that both HammerDB and the implementation of the TPC-C workload scales then we can determine that with this particular database engine both the software and hardware scales as well. If you only test your own application (and if you have more than one application which one will you use for benchmarking?)
Within a few years, we saw significant expansion of contract labor firms (or "services", or "consulting", whichever you prefer): firms like Accenture and Infosys grew rapidly, while firms like IBM ditched hardware for services. Selling became a race to the bottom in pricing. This is the economics of "worth".
The ability of a datacenter to handle traffic changes over time as capacity is added or removed, and hardware upgraded The routing needs to be able to tolerate failures without making the situation worse. This safety guard ensures larger changes happen in stages, giving caching systems etc. Sharing is caring caching.
The exercise seemed simple enough — just fix one item in the Colfax code and we should be finished. This is an uninspiring fraction of peak performance that would normally suggest significant inefficiencies in either the hardware or software. There was no deep goal — just a desire to see the maximum GFLOPS in action.
There was no deep goal — just a desire to see the maximum GFLOPS in action. The exercise seemed simple enough — just fix one item in the Colfax code and we should be finished. This is an uninspiring fraction of peak performance that would normally suggest significant inefficiencies in either the hardware or software.
Recall that Cupertino manages the actual work of Safari engineers through Apple-internal systems (previously named "Radar" ), making public bug reports a sort of parallel track; once an issue is imported from a public bug to a private tracker, it's more likely to get developer attention. But what if developers see behind the veil?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content