This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations are in search of improving network agility, but what exactly does this mean? Network agility is represented by the volume of change in the network over a period of time and is defined as the capability for software and hardware component’s to automatically configure and control itself in a complex networking ecosystem.
This is why our BYOC pricing is less than our Dedicated Hosting pricing, as the costs listed for BYOC are only what you pay for ScaleGrid and don’t include your hardware costs. A vast majority of the features are the same, outside of these advanced features available through the BYOC model: Virtual Private Clouds / Virtual Networks.
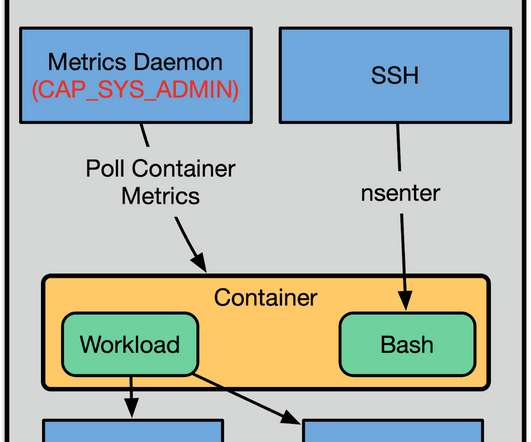
In addition to the default Docker namespaces (mount, network, UTS, IPC, and PID), we employ user namespaces for added layers of isolation. This, in turn, allows processes to exercise certain privileges without having any privileges in the init user namespace.
The early GPU systems were very vendor specific and mostly consisted of graphic operators implemented in hardware being able to operate on data streams in parallel. Programming the GPU evolved in a similar fashion; it started with the early APIs being mainly pass-through to the operations programmed in hardware. Where to go from here?
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
According to Dr. Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? The user environment defines the mapping of MPI ranks to hardware resources (cores, sockets, nodes). The MPI runtime library. in ways that are seldom transparent.
Pre-publication gates were valuable when better answers weren't available, but commentators should update their priors to account for hardware and software progress of the past 13 years. Fast forward a decade, and both the software and hardware situations have changed dramatically. Don't like the consequences?
Byte-addressable non-volatile memory,) NVM will fundamentally change the way hardware interacts, the way operating systems are designed, and the way applications operate on data. Traditionally one of the major costs when moving data in and out of memory (be it to persistent media or over the network) is serialisation.
Instead, focus on understanding what the workloads exercise to help us determine how to best use them to aid our performance assessment. As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. 4.22 %usr 38.40 0.42 %sys 9.52
degraded hardware, transient networking problem) or, more often, because of some change deployed by Netflix engineers that did not have the intended effect. In this type of environment, there are many potential sources of failure, stemming from the infrastructure itself (e.g.
There are many possible failure modes, and each exercises a different aspect of resilience. This discussion focuses on hardware, software and operational failure modes. Application Layer FMEA This first example FMEA models the application layer assuming it is implementing a web page or network accessed API.
There are many possible failure modes, and each exercises a different aspect of resilience. This discussion focuses on hardware, software and operational failure modes. Application Layer FMEA This first example FMEA models the application layer assuming it is implementing a web page or network accessed API.
It’s another networking paper to close out the week (and our coverage of SOSP’19), but whereas Snap looked at traffic routing within the datacenter, Taiji is concerned with routing traffic from the edge to a datacenter. For example, balance utilisation across all data centers, or optimise for network latency. SOSP’19.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content