This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
Fine-tune Session Replay for your business purposes—examples. Cost and traffic control. The following settings can be applied: Cost and traffic control : 100%. The following settings can be applied: Cost and traffic control : 25%. The following settings can be applied: Cost and traffic control : 100%.
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Teams can build on these SLO examples to improve application performance and reliability. In this post, I’ll lay out five SLO examples that every DevOps and SRE team should consider. or 99.99% of the time.
The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. This helped us successfully migrate 100% of the traffic on the mobile homepage canvas to GraphQL in 6 months. Correctness: The idea of correctness can be confusing too.
While most government agencies and commercial enterprises have digital services in place, the current volume of usage — including traffic to critical employment, health and retail/eCommerce services — has reached levels that many organizations have never seen before or tested against. So how do you know what to prepare for?
In my last blog , I’ve provided an example of this happening, whereby the traffic spiked and quadrupled the usual incoming traffic. These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system.
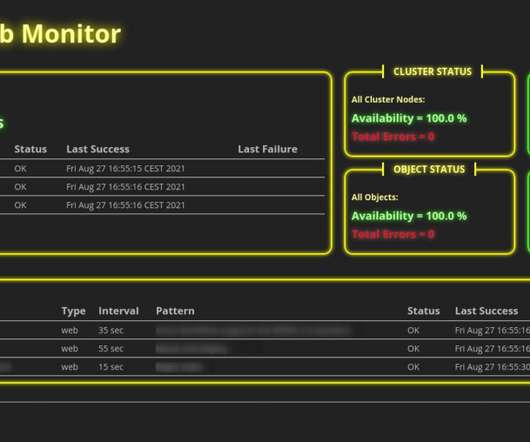
For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers. For that reason, we use monitoring tools. And there are a lot of monitoring tools available providing all kinds of features and concepts.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
For example, a member-triggered event such as “ change in a profile’s maturity level” should have a much higher priority than a “ system diagnostic signal”. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
This becomes even more challenging when the application receives heavy traffic, because a single microservice might become overwhelmed if it receives too many requests too quickly. How service meshes work: The Istio example. The Envoy proxies also collect and report telemetry on all traffic among the services in the mesh.
Next, a pragmatic approach involves examining the backend, focusing on Service type entities prominently exposed to the frontend (for example, Apache Tomcat in a Linux environment). In today’s landscape, we lack a clear understanding of properly creating frontend SLOs (for example, RUM application type entities) based on key user actions.
Aside from the huge surge in internal application usage, businesses are also witnessing increased levels of user traffic to their applications. Facilitating an understanding of traffic patterns and potential traffic spikes helps maintain customer experience. One example of these surges was from an unemployment application.
A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Here are some examples. Networking.
For example, to address challenges like asynchronous communications or security and isolation in microservice architectures, organizations often introduce third-party libraries and frameworks like Hazelcast IMDG. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control. Dynatrace news.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Detect and respond to security threats like DDoS attacks or web application attacks by monitoring application traffic and logs.
Over the last two month s, w e’ve monito red key sites and applications across industries that have been receiving surges in traffic , including government, health insurance, retail, banking, and media. The following day, a normally mundane Wednesday , traffic soared to 128,000 sessions. Media p erformance .
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. Thread 0’s cache in this example. Resolving coherency across private caches takes time and causes CPU stalls.
Quality gates examples in Dynatrace Quality gates hold much promise for organizations looking to release better software faster. The following are specific examples that demonstrate quality gates in action: Security gates Security gates ensure code meets key security requirements defined by development and security stakeholders.
But how do you get started, and what are some service level objective examples? In this post, I’ll lay out five foundational service level objective examples that every DevOps and SRE team should consider. Five example SLOs for faster, more reliable apps 1. For example, a user might expect a response time of one second or less.
For example, by measuring deployment frequency daily or weekly, you can determine how efficiently your team is responding to process changes. Application usage and traffic. Application usage and traffic monitors the number of users accessing your system and informs many other metrics, including system uptime.
For today’s highly dynamic and exceedingly complex production environments, performance problems that are evident at the service level (for example, slow response times or failed requests) are often the result of underlying (cloud) infrastructure issues. An observability framework alone is not enough. – Sergey Kanzhelev (Google).
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. For example, the gaming app has to present definite actions to bring the right experience. An app is built with some expectations and is supposed to provide firm results.
These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success. An excellent way to establish an SLO based on latency is to have a certain percentage of all service requests returned within a selected time frame of, for example, 300 ms.
In case of a spike in traffic, you can automatically spin up more resources, often in a matter of seconds. Likewise, you can scale down when your application experiences decreased traffic. For example, as traffic increases, costs will too. Analyze your resource consumption and traffic patterns.
For example, in a three-node cluster, one node can go down; in a cluster with five or more nodes, two nodes can go down. Minimized cross-data center network traffic. By utilizing embedded smart routing capabilities, Dynatrace minimizes cross-region network traffic—OneAgent traffic stays within the same network region.
Most applications communicate with databases to, for example, pull a catalog entry or submit a new record when an order is placed. For example, what happens if there is a bug that prevents an app from letting go of a database connection once a transaction is completed? Dynatrace news. Automatically detect undersized connection pools.
Read on for an example and description of our new baselining functionality. This means that Dynatrace alerts more quickly when an error spike occurs in a high-traffic service (compared to a low-traffic service where statistical confidence is lower). What do stock markets and monitoring alerts have in common?
The challenge along the path Well-understood within IT are the coarse reduction levers used to reduce emissions; shifting workloads to the cloud and choosing green energy sources are two prime examples. Network traffic power calculations rely on static power estimations for both public and private networks.
Finally, adding additional components on the edge to filter and transform syslog messages (for example, Dynatrace OpenTelemetry distribution ) isn’t always possible due to architectural reasons or because it adds unnecessary complexity and cost of ownership when scaling your business.
How Dynatrace uses Site Reliability Guardian In each of these Dynatrace examples, insight is made in a production-like environment. These examples can help you define your starting point for establishing DevOps and SRE best practices in your organization. The functionality is implemented via an automated workflow.
In the event of an isolated failure we first pre-scale microservices in the healthy regions after which we can shift traffic away from the failing one. For example, player logging, authorization, licensing, and bookmarks were initially handled by a single monolithic service whose demand correlated highly with SPS.
Typically, organizations might experience abnormal scanning activity or an unexpected traffic influx that is coming from one specific client. Examples of zero-day vulnerabilities. For example, within a week of the discovery of the Log4Shell vulnerability, Microsoft reported more than 1.8 million attack attempts , against?
A page with low traffic and failing CWV compliance does not hold the same weight as a failing page with high traffic. For example: Largest Contentful Paint can be improved by faster server response times, deferring render-blocking JavaScript and CSS, reducing resource load times, and optimizing any client-side rendering.
From the below screenshot you can see that the traffic picked up not only slightly but quadrupled! Despite the increased traffic, the other KPIs for the campaign didn’t display any increases or benefits to the campaign which wasn’t a great result for the company. Below is an example of a customer using campaign tracking with Dynatrace.
Today we’re proud to announce the new Dynatrace Operator, designed from the ground up to handle the lifecycle of OneAgent, Kubernetes API monitoring, OneAgent traffic routing, and all future containerized componentry such as the forthcoming extension framework. A great example of this push towards autonomy is SAP.
Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). RUM, however, has some limitations, including the following: RUM requires traffic to be useful.
For example, an attacker could exploit a misconfigured firewall rule to gain access to servers on your network. Scanning the runtime environment of your services can help to identify unusual network traffic patterns.
What was once an onslaught of consumer traffic between Black Friday and Cyber Monday has turned into a weeklong event, with most retailers offering deals well ahead of Black Friday. For example, this year I was doing comparisons of headphones to purchase. Below is an example of session replay. From click to fulfillment.
For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first. Examples include successful checkouts, newsletter signups, or demo requests. The problem card helped them identify the affected application and actions, as well as the expected traffic during that period.
WAFs protect the network perimeter and monitor, filter, or block HTTP traffic. Compared to intrusion detection systems (IDS/IPS), WAFs are focused on the application traffic. RASP solutions sit in or near applications and analyze application behavior and traffic.
Take the example of Amazon Virtual Private Cloud (VPC) flow logs, which provide insights into the IP traffic of your network interfaces. For example, open the Clouds app with integrated logs in the context of your Lambda functions observability for one-click access to error logs. Now, you can view your cloud logs in Dynatrace!
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content