This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. For example, organizations typically utilize only 60% of their security tools. No delays and overhead of reindexing and rehydration.
Using existing storage resources optimally is key to being able to capture the right data over time. Dynatrace stores transaction data (for example, PurePaths and code-level traces) on disk for 10 days by default. Increased storage space availability. Improvements to Adaptive Data Retention.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
For example, user behavior helps identify attacks or fraud. Another example is when anomaly detection identifies services impacted by ransomware. For example, for companies with over 1,000 DevOps engineers, the potential savings are between $3.4 Were challenging these preconceptions.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Our object storage service splits objects into many parts and stores them in S3.
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Teams can build on these SLO examples to improve application performance and reliability. In this post, I’ll lay out five SLO examples that every DevOps and SRE team should consider. or 99.99% of the time.
Use cases Identifying misconfigurations: Continuously scanning cloud environments to detect misconfigurations (such as open network ports, missing security patches, and exposed storage buckets) to help maintain a secure, stable infrastructure.
Say hello to advanced trace an alytics and new data storage and capture options. Example: Exception analysis Understanding patterns, especially regarding exceptions, is no easy feat. For example, you can filter to understand endpoint performance where exception messages contain the string, access denied. But why stop there?
For example: An airline’s reporting and analytics dashboard includes data showing flights, passengers, available seats, passenger load, revenue per passenger, flight crew staffing, arrival delays, and customer satisfaction metrics. Reduced storage and query overhead for business use cases. Improved data management.
The challenge along the path Well-understood within IT are the coarse reduction levers used to reduce emissions; shifting workloads to the cloud and choosing green energy sources are two prime examples. Storage calculations assume that one terabyte consumes 1.2 A CPU operating at 100% utilization consumes power equal to its TDP.
Besides the need for robust cloud storage for their media, artists need access to powerful workstations and real-time playback. As an example, if a show is shot on various camera formats all framed and recorded at different resolutions, with different lenses and different safeties on each frame.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Let’s examine some of the drawbacks of this approach: Lack of Idempotency : There is no idempotency key baked into the storage data-model preventing users from safely retrying requests.
Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft. As an example, imagine an analyst wanting to create a Total Streaming Hours metric. For example, LORE provides human-readable reasoning on how it arrived at the answer that users can cross-verify.
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Today along with their team, we will see how pvc-autoresizer can automate storage scaling for MongoDB clusters on Kubernetes. Our goal is to automate storage scaling when our disk reaches a certain threshold of use and simultaneously reduce the amount of alert noise related to that. kubectl annotate pvc --all resize.topolvm.io/storage_limit="100Gi"
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Polymorphic Data Storage. Greenplum’s polymorphic data storage allows you to control the configuration for your table and partition storage with the freedom to execute and compress files within it at any time.
If you store each of the keys as columns, it will result in frequent DML operations – this can be difficult when your data set is large - for example, event tracking, analytics, tags, etc. For example, Stripe transactions. JSONB storage results in a larger storage footprint. Syncing with external data sources.
Consider the following example of two different Netflix Homepages: Sample HomepageA Sample HomepageB To a basic recommendation system, the two sample pages might appear equivalent as long as the viewer watches the top title. Some examples: Why is title X not showing on the Coming Soon row for a particular member?
Analyzing impression history, for example, might help determine how well a specific row on the home page is functioning or assess the effectiveness of a merchandising strategy. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
While Atlas is architected around compute & storage separation, and we could theoretically just scale the query layer to meet the increased query demand, every query, regardless of its type, has a data component that needs to be pushed down to the storage layer.
At first, data tiering was a tactic used by storage systems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Even though they are quite costly, SSDs and flash can be categorized as high-performance storage classes.
Masking at storage: Data is persistently masked upon ingestion into Dynatrace. Leverage three masking layers Masking at capture and masking at storage operations exclude targeted sensitive data points. See the process-group settings example in the screengrab below. Read more about these options in Log Monitoring documentation.
The click-to-filter features allow you to swiftly drill down to view logs in the context of cost centers, products, custom tags, or, as in the example above, filtered to the Kubernetes daemon service. Dynatrace Grail lets you focus on extracting insights rather than managing complex schemas or index and storage concepts.
Famous examples include Redis , PostgreSQL , MySQL, and MongoDB. For example, let’s say you have an idea for a new social network and decide to use Kubernetes as your container management platform. You quickly realize that it will take ages to fill up the overprovisioned database storage.
Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. This feature store is equipped with a data replication system that enables copying data to different storage solutions depending on the required access patterns.
New processors: Introducing new processors, including Metric Selector and Content Modifier, for selective data processing and metadata adjustment, improving data relevance and storage efficiency. See the example below. By default, you have a storage type memory, but you may exceed this buffer limit if you have a lot of data.
Streamline privacy requirements with flexible retention periods Data retention is a critical aspect of data handling, and it’s not just about privacy compliance—it’s about having the flexibility to optimize data storage times in Grail for your Dynatrace use cases. Other data types will be available soon).
Managing storage and performance efficiently in your MySQL database is crucial, and general tablespaces offer flexibility in achieving this. This blog discusses general tablespaces and explores their functionalities, benefits, and practical usage, along with illustrative examples. What are MySQL general tablespaces?
As an example, cloud-based post-production editing and collaboration pipelines demand a complex set of functionalities, including the generation and hosting of high quality proxy content. The following table gives us an example of file sizes for 4K ProRes 422 HQ proxies.
By the end of the tutorial, you’ll have a running Spring Boot app that serves as an HTTP API server with ScyllaDB as the underlying data storage. For example: You’ll be able to create stocks with prices and dates and get a list of stock items. And you’ll learn how ScyllaDB can be used to store time series data.
Buckets are similar to folders, a physical storage location. For example, a separate bucket could be used for detailed logs from Dynatrace Synthetic nodes. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage.
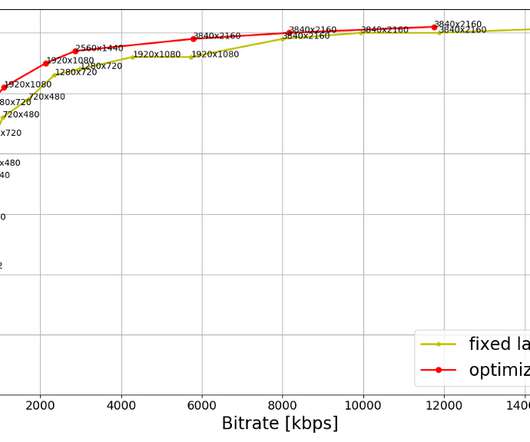
1: Example of a thriller-drama episode showing new highest bitrate of 11.8 2: Example of a sitcom episode with some action showing new highest bitrate of 8.5 3: Example of a sitcom episode with less action showing new highest bitrate of 6.6 4: Example of a 4K animation episode showing new highest bitrate of 1.8
Customers must comply with internal and external policies and regulations that might demand them to keep specific data stored for a minimum period of time (for example, audit logs). For example, suppose data has to be retained for a longer period because of legal or business reasons.
As an example, many retailers already leverage containerized workloads in-store to enhance customer experiences using video analytics or streamline inventory management using RFID tracking for improved security. These challenges stem from the distributed and often resource-constrained nature of edge computing. Try it out with a free trial.
This way, it‘s possible to flexibly select what confidential or sensitive information (for example, PII) is hashed or completely removed before it leaves the enterprise premises. If a more granular rule is present on the host level, that rule will precede any blanket rule on, for example, the tenant level. Try it out yourself.
They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. It also allows for logic statements to handle situations such as mount this storage in this environment only or only run this script if this file does not exist. Artists need many components to be customized.
Log analytics can determine whether the same service or function is consistently causing an application to not meet SLOs during peak season — for example, when a retailer offers an end-of-season sale, or a financial application is critical for closing out the year. Cold storage and rehydration. Cold storage and rehydration.
Rising compliance demands Businesses today are under immense pressure to keep up with stringent regulations surrounding data storage, processing, and access. Addressing these challenges proactively is critical to maintaining a secure and efficient cloud infrastructure. Leverage tailored workflows to ensure quick resolution.
Log analytics can determine whether the same service or function is consistently causing an application to not meet SLOs during peak season — for example, when a retailer offers an end-of-season sale, or a financial application is critical for closing out the year. Cold storage and rehydration. Cold storage and rehydration.
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). This decoupling ensures the openness of data and storage formats, while also preserving data in context. Grail is built for such analytics, not storage.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content