This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A business process is a collection of related, usually structured tasks or steps, performed in sequence, that achieve a defined business goal. Tasks may be manual or automatic, and many business processes will include a combination of both. Make better decisions by providing managers with real-time data about the business.
This step-by-step guide outlines the process of creating a microservices-based system, complete with detailed examples. Microservices allow teams to deploy and scale parts of their application independently, improving agility and reducing the complexity of updates and scaling.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
Apache Kafka is a battle-tested distributed stream-processing platform popular in the financial industry to handle mission-critical transactional workloads. For example, the market data team may continuously update real-time quotes for a security to Kafka, and the trading team may consume that data to make buy/sell orders.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing.
Business processes support virtually all aspects of an organizations operations. Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance.
if you wanted to schedule a job, you could use the Cron binding component to implement recurring jobs on a regular defined schedule; for example, automating database backups, sending out recurring email notifications, running routine maintenance tasks, data processing, and ETL, running system updates and batch processing.
There are two major processes which gets executed when a user posts a photo on Instagram. Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity.
The risk of impact from an existing known vulnerability also depends on whether certain processes are using the vulnerable parts of a software component. Process group 1 doesn’t use the function that contains the vulnerability. The vulnerable function in the software package is highlighted in red.
And by “sample” we mean “an example”, like food samples in your local grocery store. Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) data processing purposes, e.g. Machine Learning model building and scoring. test_sparksql_write.py
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. With DQL, the workflow trigger to initiate a required automation and remediation process can be defined.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. This allows developers to easily access and process the file without handling the upload mechanics directly. Heres an example of what the action class should look like.
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit and Fluentd were created for the same purpose: collecting and processing logs, traces, and metrics. Ask yourself, how much data should Fluent Bit process? What is Fluent Bit?
How logs are ingested Dynatrace offers OpenPipeline to ingest, process, and persist any data from any source at any scale. OpenPipeline ensures data security and privacy—data is collected and processed securely and compliantly, with high-performance filtering, masking, routing, and encryption—and contextualizes incoming data in real time.
This level of protection is essential as it lays the foundation for the following testing processes: integration tests, acceptance testing, and finally manual testing, including exploratory testing. We'll also touch upon automation testing , which plays an important role in ensuring code reliability and quality.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Consolidate real-user monitoring, synthetic monitoring, session replay, observability, and business process analytics tools into a unified platform. Real-time customer experience remediation identifies and informs the organization about any issues and prevents them in the experience process sooner.
For example, optimizing resource utilization for greater scale and lower cost and driving insights to increase adoption of cloud-native serverless services. This process enables you to continuously evaluate software against predefined quality criteria and service level objectives (SLOs) in pre-production environments.
Anomaly detection is the process of identifying the data deviation from the expected results in a time-series data. Detecting outliers also helps in identifying the source of the deviations in processes. This deviation can have a huge impact on forecasting models if not identified before the model creation.
When organizations implement SLOs, they can improve software development processes and application performance. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. Instead, they can ensure that services comport with the pre-established benchmarks.
Dynatrace does this by automatically creating a dependency map of your IT ecosystem, pinpointing the technologies in your stack and how they interact with each other, including servers, processes, application services, and web applications across data centers and multicloud environments. asc | fields `Host`, `Recently Restarted?
Information related to user experience, transaction parameters, and business process parameters has been an unretrieved treasure, now accessible through new and unique AI-powered contextual analytics in Dynatrace. Lack of visibility into business processes to improve, optimize, and remediate issues and systems harms business success.
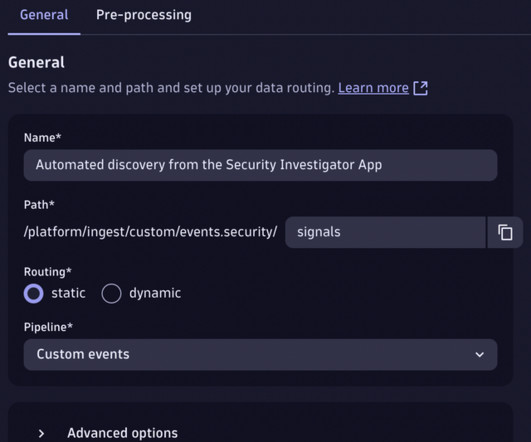
OpenPipeline allows you to create custom endpoints for data ingestion and process the events in the pipeline (for example, adding custom pipe-dependent fields to simplify data analysis in a later phase). Give your pipeline a name, for example, Automated discovery from Security Investigator. Ready to give this a shot yourself?
Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems. In this article, we will explore the differences between monitoring and observability, provide examples to illustrate their applications and highlight their respective benefits.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
This architectural style enables teams to develop and deploy services independently, offering flexibility and scalability to the software development process. Let's take the example of an online marketplace application.
This process, known as auto-adaptive thresholding, eliminates the need to define a static threshold upfront. For example, the team must establish specific thresholds for desired service performance behavior. For instance, if an objective is violated, they’re immediately notified, for example, through a Slack channel.
However, many teams struggle with knowing which ones to use and how to incorporate them into the processes. Below, several Dynatrace customers shared their SLO management journey and discussed the resulting dashboards they rely on daily to manage their mission-critical business processes and applications. What are SLOs?
The automated extraction of ownership information, for example, from Kubernetes annotations, is therefore essential. Secondly, knowing who is responsible is essential but not sufficient, especially if you want to automate your triage process. An example via Monaco can be found in this public GitHub repository.
By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes. Automating GitHub runner data ingestion with Dynatrace workflows Workflows within the Dynatrace SaaS platform are a robust tool for automating complex processes.
Quality gates examples in Dynatrace Quality gates hold much promise for organizations looking to release better software faster. The following are specific examples that demonstrate quality gates in action: Security gates Security gates ensure code meets key security requirements defined by development and security stakeholders.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. What is AIOps, and how does it work?
Dynatrace Simple Workflows make this process automatic and frictionlessthere is no additional cost for workflows. Why manual alerting falls short As your product and deployments scale horizontally and vertically, the sheer volume of data makes it impossible for teams to catch every error quickly using manual processes.
And while these examples were resolved by just asking a few questions, in many cases, the answers are more elusive, requiring real-time and historical drill-downs into the processes and dependencies specific to each host. A few examples: Reduce roundtrips between services (for example, the N+1 query pattern).
During that pause period, no customer transactions will be processed. Garbage collection throughput indicates what percentage of the application’s time is spent in processing customer transactions and what percentage of time is spent in the garbage collection activities.
Deploying software in Kubernetes is often viewed as a straightforward process—just use kubectl or a GitOps solution like ArgoCD to deploy a YAML file, and you’re all set, right? Unfortunately, Kubernetes deployments can be fraught with challenges beyond the surface level.
Gartner® predicts that by 2026, 40% of log telemetry will be processed through a telemetry pipeline product, up from less than 10% in 2022.* A best practice to avoid these problems is to store data in a single data lakehouse with massively parallel processing, such as Dynatrace Grail.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content