This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cloud-native technology has been changing the way payment services are architected. In 2020, I presented a series with insights from real implementations adopting open-source and cloud-native technology to modernize payment services.
This step-by-step guide outlines the process of creating a microservices-based system, complete with detailed examples. Microservices allow teams to deploy and scale parts of their application independently, improving agility and reducing the complexity of updates and scaling.
As one of the most popular open-source Kubernetes monitoring solutions, Prometheus leverages a multidimensional data model of time-stamped metric data and labels. The platform uses a pull-based architecture to collect metrics from various targets.
For example, if you need information about VM memory consumption, which AWS does not provide out of the box, you can configure the CloudWatch agent to collect this data. However, it’s worth noting that Memory and Disk metrics are not included in the default metric collection.
Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. HTTP monitor execution details Your analysis might require comparing the details of two executions, for example, a current failing execution and a historical one when the test passed.
In this article, we will explore how AI can assist in these areas, providing code examples to tackle complex queries. Leveraging AI can revolutionize query optimization and predictive maintenance, ensuring the database remains efficient, secure, and responsive.
In this article, we will discuss an example based on the client-side scenario. Client and Server Side Load Balancing We talk about client-side load balancing when one microservice calls another service deployed with multiple instances and distributes the load on those instances without relying on external servers to do the job.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. For example, if you have an SLA guaranteeing 95% uptime, you can set a static threshold to alert you whenever uptime drops below this value, ensuring you meet your service commitments.
In the example below, we demonstrate how to use workflows to ingest data from the GitHub API, capturing detailed information about runners and integrating it seamlessly into Dynatrace business events for actionable insights. However, these use cases are just the beginning.
The reason HDR10+, with its dynamic metadata, shines in this example is that the scenes preceding and following the scene with this frame have markedly different luminance statistics. While this is a simple example, the dynamic metadata in HDR10+ demonstrates such value across any set of scenes.
Heres an example of what the action class should look like. Consider the following example, where a couple of objects are stored in the value stack. An example depicting how identically named values for different objects are retrieved from a value stack. For example, using a parameter named fileFileName[0].
For example, user behavior helps identify attacks or fraud. Another example is when anomaly detection identifies services impacted by ransomware. For example, for companies with over 1,000 DevOps engineers, the potential savings are between $3.4
So, for example, if you need to seamlessly integrate metrics with logs for your workloads , you can create a customized view based on the pre-configured dashboard that consolidates all critical signals in one place, which is particularly essential for troubleshooting. Next, let’s use the Kubernetes app to investigate more metrics.
For your reference, the complete working example is available on GitHub. By leveraging tools like Spring Boot Actuator , Micrometer with InfluxDB , and Grafana , you can gather meaningful insights easily and quickly. In this article, we'll walk through setting up this stack using a simple "Card-Playing" app/game as our use case.
Below are some of the best practices with coding examples to optimize performance in Azure Cosmos DB. Likewise, in Azure Cosmos DB, optimization is crucial for maximizing efficiency, minimizing costs, and ensuring that your application scales effectively.
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant. You can even walk through the same example above. This is just the beginning.
I used to work at another Observability vendor, and many of the OpenTelemetry examples that I played with and blogged about in the last 2 years or so featured sending OTel data to that backend. A great way to learn is to try to run my go-to examples using Dynatrace as the Observability backend. Then check out my example repo.
As an example, you can specify a Config that reads a pleasantly human-readable configuration file, formatted as TOML. Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs.
Improve software delivery by observing customer success on a subset of customers first before going broad (for example, progressive delivery, dark launches, and A/B testing) with Dynatrace support for feature flags and software delivery observability. Automate smarter using actual customer experience metrics, not just server-side data.
Examples include: A stalled connection between two services delays the process of validating food orders, resulting in dissatisfied customers, idle delivery drivers, and canceled orders. For example, average loan amount, service response time, or close rate.) Examples include revenue, order quantity, loan amount, and approval rate.
No problem—out-of-the-box templates simplify the setup of time series data based on service requests, and templates can quickly be adapted for more fine-grain needs, for example, to consider only single endpoints. Are you defining SLOs based on the four golden signals of a critical service?
In my previous article on Pydantic, I introduced you to Logfire in one of the code examples as an observability platform designed to provide developers with insights into Python applications.
Segments can implement variables to dynamically provide, for example, a list of entities to users, such as available Kubernetes clusters, for unmatched flexibility and dynamic segmentation. For example, a segment for Service Errors in Azure Region can be applied instantly by selecting it from the dropdown. What are Dynatrace Segments?
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. All other default policies on the service level, for example, “AutomationEngine – User” access, are now marked as Legacy.
For this example, we go to Simple Workflows and select Trigger > Davis event trigger to find these out-of-memory errors. They trigger a single, out-of-the-box action: for example, Sending a Slack Notification, Creating a Jira Issue, Sending an Email, or Executing an HTTP Request. Theyre free and unlimited.
Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft. As an example, imagine an analyst wanting to create a Total Streaming Hours metric. For example, LORE provides human-readable reasoning on how it arrived at the answer that users can cross-verify.
For a detailed explanation of this example and walkthrough, visit our blog post, Debug complex performance issues in production. Tailor-made entry points can be achieved using the aforementioned IDE plugins or by extending the Backstage developer portal with the Dynatrace plugin.
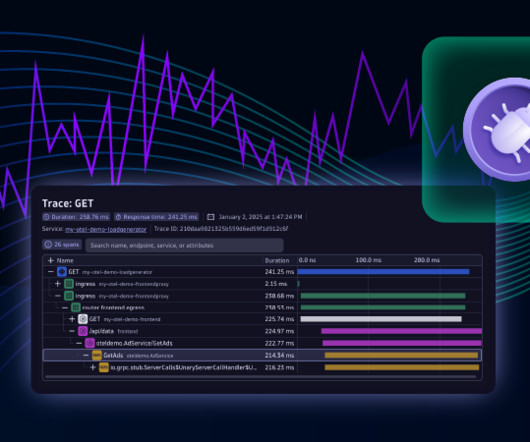
In this example use case, we’re investigating a high CPU load issue in an application using OpenTelemetry. Dynatrace OpenPipeline is configured to ingest logs from our environment, including the AdService example service. Live Debugger allows you to set non-breaking breakpoints, capturing critical data snapshots in real time.
No complex jargon, just simple steps to get you started with real-world examples. In this article, well walk through setting up observability in 10 minutes using OpenSearch Observability.
You can even walk through the same example above. As soon as the new Distributed Tracing Experience is available for your environment, you’ll see a teaser banner in your classic Distributed Traces app. If you’re not yet a DPS customer, you can use the Dynatrace playground instead. This is just the beginning.
This comprehensive guide explores advanced techniques and best practices for maximizing Snowflake performance, backed by practical examples and implementation strategies. As organizations scale their data operations in the cloud, optimizing Snowflake performance on AWS becomes crucial for maintaining efficiency and controlling costs.
For example, timestamps need additional processing to capture both absolute and relative notions of time, with absolute time being particularly important for understanding time-sensitive behaviors. For example, we can derive genres from the items in the original sequence and use this genre sequence as an auxiliary target.
In this guide, Ill share battle-tested strategies to optimize React apps , sprinkled with real-world war stories and practical examples. Ive been in that exact spot debugging performance issues at 2 AM, fueled by coffee and frustration. No jargon, no fluff just actionable advice.
Step-by-step setup The log ingestion wizard guides you through the prerequisites and provides ready-to-use command examples to start the installation process. The pre-defined monitoring mode settings, for example, Full-Stack, are pre-selected following your platform administrators guidelines.
Let's explore the key features of these platforms and examine some code examples to illustrate their practical applications. These platforms provide developers with powerful tools to monitor, debug, and optimize AI agents, ensuring their reliability, efficiency, and scalability.
For example, it supports string and numerical values, enabling a multitude of different use cases. For example, set the value range for CPU consumption from 0% to 100%. They have become a quasi-standard in the industry, especially for infrastructure monitoring visualizations. Min and max limits.
Please see the sample queries appendix for an example query to get started. You can find an example query in the sample queries appendix. Example of suspicious and regular access pattern by the service account. A ClusterRole called ingress-nginx is configured along with other components.
As an example, for a trading application, it is of paramount importance to show changing stock prices for several stocks in a single instance with high performance and accuracy. Modern web and mobile applications require showing information from large and changing datasets in an actionable manner to end users.
Because it includes examples of 10 programming languages that OpenTelemetry supports with SDKs, the application makes a good reference for developers on how to use OpenTelemetry. In this example, we’ll use Dynatrace. This example illustrates how to pass the token most easily using the terminal.
Example: Exception analysis Understanding patterns, especially regarding exceptions, is no easy feat. For example, you can filter to understand endpoint performance where exception messages contain the string, access denied. These powerful insights can easily be transformed into interactive dashboards.
How it works Dynatrace seamlessly instruments your LLM-based workloads using Traceloop OpenLLMetry, which augments standard OpenTelemetry data with AI-specific KPIs (for example, token usage, prompt length, and model version). The specific foundation model version (for example, anthropic.claude-v1 or amazon.nova).
Note that EC2 is an example; this guide can be made to work generically for tag changes on any AWS resource. For example, set a delay of 600 seconds (10 minutes). Example timeline: 06:59: Tag changed on EC2 instance. Configure the event type as `bizevent` and set the filter query to: ` ` `sql event.type == “ec2.tag.change”
For example, Dynatrace completely reinvented its platform in 2015 into a cloud-native, multi-tenant software-as-a-service (SaaS). As the company has grown to more than 4,700 employees, Greifeneder’s team has designed an agile and autonomous approach to innovation at scale. The company also introduced its proprietary Davis® AI engine.
We'll walk through step-by-step examples, demonstrating how to integrate RxJS into your React applications. RxJS operators simplify handling complex asynchronous data flows, making your React components more manageable and efficient. In this article, we'll explore RxJS operators within the context of ReactJS.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content