This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Event-driven automation enables systems to react instantly to specific triggers or events, enhancing infrastructure resilience and efficiency. A simple and effective method for implementing event-driven automation is through webhooks, which can initiate specific actions in response to events.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
MySQL does not limit the number of slaves that you can connect to the master server in a replication topology. A classic solution for this problem is to deploy a binlog server – an intermediate proxy server that sits between the master and its slaves. Ripple is an open source binlog server developed by Pavel Ivanov.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
There are three high-level steps to set up the database business-event stream. Step-by-step: Set up a custom MySQL database extension Now we’ll show you step-by-step how to create a custom MySQL database extension for querying and pushing business data to the Dynatrace business events endpoint. Don’t rename the file.
In a MySQL master-slave high availability (HA) setup, it is important to continuously monitor the health of the master and slave servers so you can detect potential issues and take corrective actions. MySQL Master Server Health Checks. Important Health Checks for your MySQL Master-Slave Servers Click To Tweet.
They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions. These initial automation endeavors paved the way for greater advancements, leading to the next evolution of event-driven automation.
To avoid false-positive alerts, Dynatrace availability alerting for servers automatically detects the planned downscaling of AWS spot instances. To enable you to automatically detect the shutdown of spot instances and the scaling up or down of third-party autoscaling solutions, we’ve introduced a new event type.
The steps across devices, APIs, server-side service invocations, and information from the inner workings of services can be used to gain a complete understanding of omnichannel user journeys and their associated customer satisfaction and business success. Automate smarter using actual customer experience metrics, not just server-side data.
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
Dynatrace does this by automatically creating a dependency map of your IT ecosystem, pinpointing the technologies in your stack and how they interact with each other, including servers, processes, application services, and web applications across data centers and multicloud environments. Q: What was the cause of the outage?
What was once an onslaught of consumer traffic between Black Friday and Cyber Monday has turned into a weeklong event, with most retailers offering deals well ahead of Black Friday. By focusing on the server, digital performance has become much more consistent, even under the weight of massive amounts of consumer load.
Or maybe you want to correlate an event with other events in your system. Legacy servers pick up complexity and dependencies over time. Maybe you want to focus on a specific service, endpoint, user, or use case. Maybe you want to monitor performance under different system loads. The reasons for this are many.
Upon detecting a high CPU load, Davis AI generates a problem event and populates it with a direct link to Live Debugger. Using this data, developers can inspect local variables, server-process details, thread information, and trace data to identify the root cause of issues.
In this hands-on lab from ScyllaDB University, you will learn how to use the ScyllaDB CDC source connector to push the row-level changes events in the tables of a ScyllaDB cluster to a Kafka server. What Is ScyllaDB CDC?
If the primary server encounters issues, operations are smoothly transitioned to a standby server with minimal interruption. Key Takeaways PostgreSQL automatic failover enhances high availability by seamlessly switching to standby servers during primary server failures, minimizing downtime, and maintaining business continuity.
Firstly, it ensures optimized resource utilization by evenly distributing workloads across multiple servers or resources, preventing any single server from becoming a performance bottleneck. Load balancing is a critical component in cloud architectures for various reasons.
Serverless architecture shifts application hosting functions away from local servers onto those managed by providers. This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Enhancing event ingestion. Let’s get started. Application integration.
Easily track the health and performance of database servers with AI support. To simplify database monitoring and improve cross-team collaboration, Dynatrace released new extensions to leading databases, including Oracle and Microsoft SQL Server. Break down departmental silos and manage databases holistically.
Dynatrace provides server metrics monitoring in under five minutes, showing servers’ CPU, memory, and network health metrics all the way through to the process level, with no manual configuration necessary. AL2023 is supported by Dynatrace on day one and has been thoroughly tested by our installations team. How does Dynatrace help?
It allows service providers to run their networks on standard servers instead of proprietary ones. In a cloud service provider like IBM, a user can spin up these VNF images in a standard virtual server instead of proprietary hardware.
Load and DOMContentLoaded are internal browser events—your users have no idea what a Load time even is. TTFB is a good measure of your server response times and general back-end health, and issues here may have knock-on effects later down the line (namely with Largest Contentful Paint). I bet half of your colleagues don’t either.
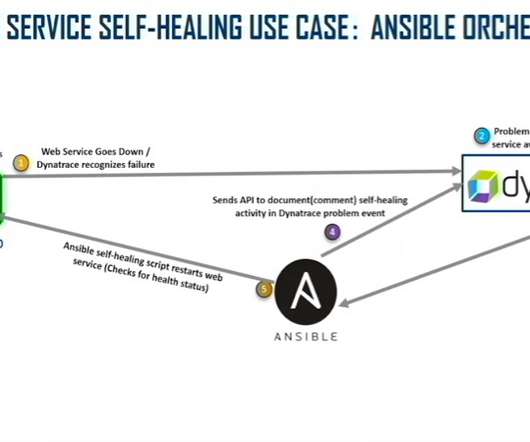
At Dynatrace Perform 2022 , David Walker, a Lockheed Martin Fellow, and William Swofford, a full-stack engineer at Lockheed Martin, discuss how to create a self-diagnosing and self-healing IT server environment using this AIOps combination for auto-baselining, auto-remediation, monitoring as code, and more. An example of the self-healing web.
Patroni also supports event notification with the help of callbacks, which are scripts triggered by certain actions. Supports event notifications via callbacks scripts triggered by certain actions. Standby Server Tests. Reboot the server. patronictl list did not display this server. Master/Primary Server Tests.
The market offers plenty of monitoring solutions that can link a specific monitored event with a specific scripted action. Because Dynatrace isn’t simply searching for “service is up, service is down” type of events, Dynatrace can actually proactively discover problems in the environment before they happen.
The Qualys Threat Research Unit (TRU) has discovered a Remote Unauthenticated Code Execution (RCE) vulnerability in OpenSSH server (sshd) in glibc-based Linux systems. Look for timeout events Exploitation attempts for this vulnerability can be identified by many lines of “Timeout before authentication” in the logs.
Microsoft recently released the first public preview of SQL Server 2022. This clause is now available in Azure SQL Database and SQL Server 2022, provided you use database compatibility level 160 or higher. Each row represents an event where one or more attribute values have changed. You can download this sample database here.
On Titus , our multi-tenant compute platform, a "noisy neighbor" refers to a container or system service that heavily utilizes the server's resources, causing performance degradation in adjacent containers. During this event, we generate a timestamp and store it in an eBPF hash map using the process ID as the key.
When all else failscheck Kubernetes events Kubernetes events provide detailed and chronological information about whats happening within various components of your cluster. inject-python: "true" spec: containers: - name: py-otel-server image: otel-python-lab:0.1.0-py-otel-server inject: "true" instrumentation.opentelemetry.io/inject-python:
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Luckily, we have Kafka events that are emitted each time a piece of data changes. The first step is to listen to those events and act accordingly.
Applications and services are often slowed down by under-performing DNS communications or misconfigured DNS servers, which can result in frustrated customers uninstalling your application. Identify under-performing DNS servers. Slower response times can be a sign of a stressed DNS server or network communication issues.
The time from browser request to the first byte of information from the server. Load event start. The time it takes to begin the page’s load event. Load event end. The time it takes to complete the page’s load event. The time taken to complete the page load. Time to first byte. Time to render.
Managing database servers involves different aspects, among which security is critical. However, we know having a “runaway” grant is always a possibility, especially in environments with a large number of servers. Audit Log Plugin One way to track these events is through auditing. The drop events are listed below.
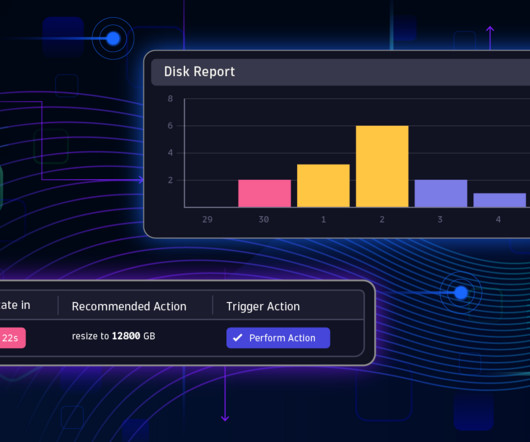
Figure 4: Custom dashboard analyzing cloud cost Improve cloud security posture by analyzing and auto-remediating security findings Public cloud providers offer automated tools that detect security-related events as they occur. These events require triage, analysis, and remediation by the owners of the affected resources.
Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. A single API team maintained both the Java implementation of the Falcor framework and the API Server. To launch Phase 1 safely, we used AB Testing.
Kubernetes observability Helps to understand and troubleshoot the health and performance of your MicroShift deployments and optimize resources by providing out-of-the-box alerting and anomaly detection, automated root cause analysis, as well as metrics, events, and topology in context.
Application servers use connection pools to maintain connections with the databases that they communicate with. You can even integrate Dynatrace into your CI/CD pipeline using the Events API. This allows you to create a deployment event that contains all important details each time a new version is released.
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL.
A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices.
Cloud-based AI enables organizations to run AI in the cloud without the hassle of managing, provisioning, or housing servers. Containerization enables organizations to package AI applications and dependencies into a single unit, which can be easily deployed on any server with the necessary dependencies. Use containerization.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content