This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
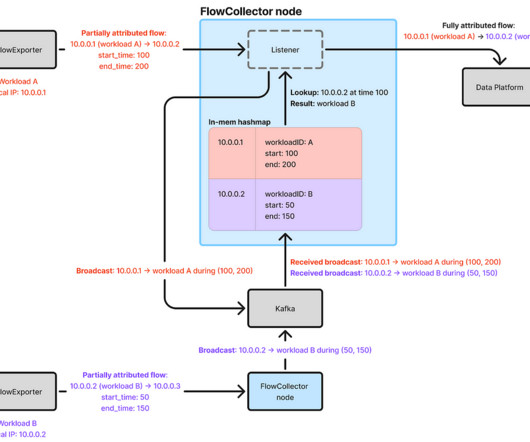
By Cheng Xie , Bryan Shultz , and Christine Xu In a previous blog post , we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. FlowCollector consumes a stream of IP address change events from Sonar and uses this information to attribute flow IP addresses in real-time.
To extend Dynatrace diagnostic visibility into network traffic, we’ve added out-of-the-box DNS request tracking to our infrastructure monitoring capabilities. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Slower response times can be a sign of a stressed DNS server or network communication issues.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is RabbitMQ? What is Apache Kafka?
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Some of the keys of understanding the user network are listed below.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events.
But there’s more than just a need for minimizing resource (CPU, memory, storage) and network (bandwidth) consumption for observability at the edge. Moreover, edge environments can be highly dynamic, with devices frequently joining and leaving the network. Remote management and automated alerting are, therefore, crucial.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum interconnect is the networking layer of the architecture, and manages communication between the Greenplum segments and master host network infrastructure. Polymorphic Data Storage. Major Use Cases.
Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking. Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult.
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and network traffic. SIEM Security information and event management (SIEM) tools are staples of enterprise security.
Performance monitoring Dynatrace can collect performance metrics from Nutanix clusters, including latency, IOPS (Input/Output Operations Per Second), and network throughput. Storage container metrics Track the usage and performance of storage containers to optimize resource allocation.
To remain compliant, such logs are typically subject to pseudonymization or anonymization procedures (masking), which makes sensitive data inaccessible while preserving the contextual information of the event, service, or host. As data volumes explode, teams have different prioritization for the data they want to acquire for observability.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. Problems have defined lifespans and are updated in real time with all incoming events and findings. Log Events.
It differentiates Dynatrace as an AWS Partner Network (APN) member with a fully tested product on AWS Outposts. “We As you can see in the following screenshots, EKS metrics flow into the Dynatrace Cluster and from there to the Dynatrace web UI, where you can view metrics, events, and logs for an Amazon EKS cluster running on AWS Outposts.
Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion. Quorum queues can still function during a network partition as long as most nodes communicate.
This code is then executed on remote servers in response to an event, such as users interacting with functional web elements. Infrastructure as a service (IaaS) handles compute, storage, and network resources. Many organizations use function as a service when migrating to the cloud or for RESTful and event-driven applications.
Networking. Large-scale, multicloud deployments can introduce challenges related to network visibility and interoperability. Traditional ways of operating networks using static IPs and ports simply don’t work in dynamic Kubernetes environments. Bad actors can use misconfigurations to gain access to sensitive data.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. For simpler use cases, it also represents flat key-value Maps (e.g.
Logs represent event data in plain-text, structured or binary format. By providing Dynatrace access to the Kubernetes API , many additional insights are possible, for example, event tracking and over-commitment rate (resource requests vs. r esources available). . Dynatrace Kubernetes documentation . Kubernetes integration.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Whereas log monitoring is the process of tracking ingested and recorded logs, log analytics evaluates those logs and their context for the significance of the events they represent.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. With Dynatrace, teams can seamlessly monitor the entire system, including network switches, database storage, and third-party dependencies.
Carbon Impact leverages business events , a special data type designed to support the real-time accuracy and long-term granularity demands common to business use cases. Carbon Impact uses host utilization metrics from OneAgents to report the estimated energy consumption for CPU, storage I/O, memory, and network.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center network traffic. Automatic recovery for outages for up to 72 hours.
This ensures that when a commit returns successfully, the data exists both in the master and the slave, so in the event a datacenter goes down, your MySQL master can failover to a slave without any data loss. Azure Virtual Networks.
But managing the deployment, modification, networking, and scaling of multiple containers can quickly outstrip the capabilities of development and operations teams. This orchestration includes provisioning, scheduling, networking, ensuring availability, and monitoring container lifecycles. How does container orchestration work?
Easier rollout thanks to log storage best practices. Easier rollout thanks to log storage best practices. As such, it’s quite often a network-shared mount point that multiple hosts use to store third party software and libraries. Advanced customization of OneAgent deployments made easy.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Additionally, they manage applications and services deployed on the network and provide secure access to authorized users. How to modernize ITOps with AIOps.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. Tie latency issues to host and virtualization infrastructure network quality.
While traditional AI relies on finding correlations in data, causal AI aims to determine the precise underlying mechanisms that drive events and outcomes. Therefore, causal AI is a useful deterministic AI technique that provides concrete answers about the source of events, not probabilistic outputs.
When a new leader is elected it loads all data from external storage. The path over which data travels from Titus Job Coordinator to a Titus Gateway cache can be described as a sequence of event queues with different processing speeds: A message generated by the event source may be buffered at any stage. it will read version E?
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. Logs can also be used to represent event data.
As the entire application shares the same computing environment, it collects all logs in the same location, and developers can gain insight from a single storage area. The components of partitioned applications generally communicate over a network call. The last aspect is the centralization of compute.
Dynatrace AutomationEngine workflows automate release validation using AWS Well-Architected pillars With Dynatrace, you can create workflows that automate various tasks based on events, schedules or Davis problem triggers. Workflows are powered by a core platform technology of Dynatrace called the AutomationEngine.
To address potentially high numbers of requests during online shopping events like Singles Day or Black Friday, it’s crucial that this online shop have a memory storage strategy that allows for speed, scaling, and resilience of all microservices, especially the shopping cart service.
There are certain situations when an agent based approach isn’t possible, such as with network or storage devices, or a very old OS. Dynatrace OneAgent is great for monitoring the full stack. However, you can’t install OneAgents on every single type of device. Platform extensions.
Logs complement out-of-the-box metrics and enable automated actions for responding to availability, security, and other service events. Many AWS services and third party solutions use AWS S3 for log storage. Because data context is missing for logs, it’s slow or even impossible to build causal relationships in your observability data.
Whether it’s cloud applications, infrastructure, or even security events, this capability accelerates time to value by surfacing logs that provide the crucial context of what occurred just before an error line was logged. With Dynatrace, there is no need to think about schema and indexes, re-hydration, or hot/cold storage concepts.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content