This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
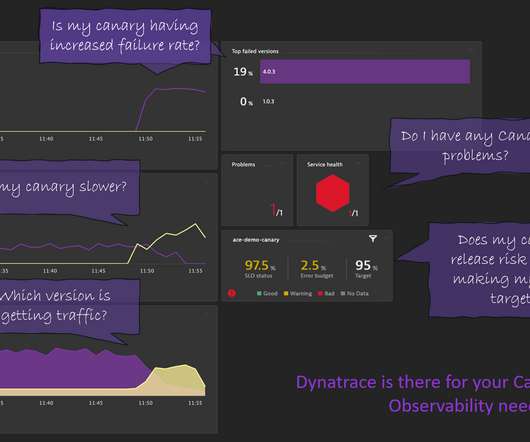
Our latest enhancements to the Dynatrace Dashboards and Notebooks apps make learning DQL optional in your day-to-day work, speeding up your troubleshooting and optimization tasks. Next, let’s use the Kubernetes app to investigate more metrics.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Dynatrace unifies all the different data types at scale and in context.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all? The result?
The volume of data and events grows in tandem with the rising complexity of IT infrastructure. While SNMP allows you to query monitored devices for performance information, SNMP traps are used to proactively report certain types of events. These can range from routine state transition events to critical problem reports.
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
Recently introduced improvements to Visually complete and new web performance metrics for Real User Monitoring are now available for Synthetic Monitoring as well. Ensure better user experience with paint-focused performance metrics. These metrics are tightly connected to the perceived load speed of your application.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
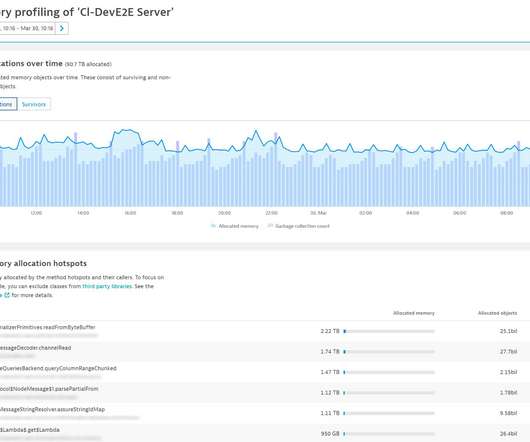
Any significant reduction in allocations will inevitably speed up your code. To see why, navigate to the Suspension chart on the JVM metrics tab. . By reducing the number of allocated objects, you can both speed up your code and reduce object churn and garbage collection events. Speed up application code itself.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Speed index. Load event start. Load event end.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
Table name Default bucket logs default_logs events default_events metrics default_metrics bizevents default_bizevents dt.system.events dt_system_events entities spans (in the future) The default buckets let you ingest data immediately, but you can also create additional custom buckets to make the most of Grail.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. A pipeline can be the parent of multiple tasks to group the resulting events logically.
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
Annie leads the Chrome SpeedMetrics team at Google, which has arguably had the most significant impact on web performance of the past decade. We've gotten to know Annie through frequent discussions, feedback sessions, and hallway talks at various events. What is the charter of the Chrome SpeedMetrics team?
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. This is why precisely showing the root cause ultimately helps to speed up problem resolution.
Achieving the ideal state with aggregated, centralized log data, metrics, traces , and other metadata is challenging—particularly for multicloud environments. Lining up traces, logs, and metrics based on user events and timestamps provides the most complete picture of full-stack dependencies.
Spring also introduced Micrometer, a vendor-agnostic metric API with rich instrumentation options. Soon after, Dynatrace built a registry for exporting Micrometer metrics. Our data APIs, which ingest millions of metrics, traces, and logs per second, are reconciled using Micrometer-based metrics.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed. Thus, Grail was born.
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. Enable the Davis AI causation engine to automatically analyze every metric.
The only way to address these challenges is through observability data — logs, metrics, and traces. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Your key business objectives will drive your strategy and metrics. Event severity. But it doesn’t stop there.
One particular use case for Austrian banking software developer Raiffeisen involves using Keptn to automate the production release and readiness validation of all its products using scoring metrics. Developers also need to automate the release process to speed up deployment and reliability. Why is automated orchestration critical?
Here are some common questions I’m asked when I talk with people about performance: Which metrics should I care about? Page Speed Benchmarks is an interactive dashboard that lets you explore and compare web performance data for leading websites across several industries – from retail to media. How fast should I be?
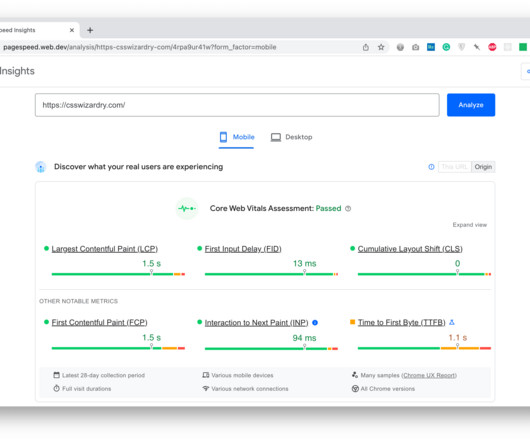
Google do strongly encourage you to focus on site speed for better performance in Search, but, if you don’t pass all relevant Core Web Vitals (and the applicable factors from the Page Experience report) they will not push you down the rankings. While Core Web Vitals can help with SEO, there’s so much more to site-speed than that.
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
Web Performance is important for user experience and business metrics. Look, there are many case studies proving a correlation between loading time and business metrics!” ?-?I Plotting Business Metrics vs Performance Metrics Think about what you are trying to drive on your existing site. I would repeat over and over.
Amplify PowerUP, our half-yearly global event to update our partner community, covered a lot of ground including key Partner Program announcements, Q2 earnings and partner contribution, market growth and momentum, Dynatrace platform capabilities, and the partner services offering the platform powers. It’s a different concept from monitoring.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. As teams try to gain insight into this data deluge, they have to balance the need for speed, data fidelity, and scale with capacity constraints and cost. Logs on Grail Log data is foundational for any IT analytics.
As I see it, there are two main issues when it comes to measuring performance changes (note, not improvements , but changes) in the lab: Site-speed is nondeterministic 1. As noted above, it’s not actually possible to improve certain metrics in their own right. There are myriad reasons for this that I won’t cover here. duration ).
Gartner defines AIOps as the combination of “big data and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” Typically, only the aggregated events will be accessible to ML and will often exclude additional details. What is AIOps?
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed).
These sets of tools are acquiring one or more different types of raw data (metrics, logs, traces, events, code-level details…) at various granularity, process them and create alerts (a threshold or learned baseline was breached, a certain log pattern occurred and so forth). Another huge advantage of that approach is speed.
Challenges to exploratory data analytics Among the challenges analysts face are multiple heterogeneous data sources, noisy or incomplete data, insufficient causal reasoning (faulty connections between event cause and effect), and untrustworthy AI , according to an article from the Columbia University Data Science Institute.
Progressive Delivery enables speeding up while managing the risk of software deployments and configuration changes. Optionally you can also pass the build version and can send a deployment event from your deployment automation tool. Having metrics with version information, e.g, Dynatrace news. Step 3: SLOs. So – go ahead!
While the benefits of AIOps are plentiful — including increased automation, improved event prioritization and incident response, and accelerated digital transformation — applying AIOps use cases to an organization’s real-world operations issues can be challenging. CloudOps includes processes such as incident management and event management.
You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data.
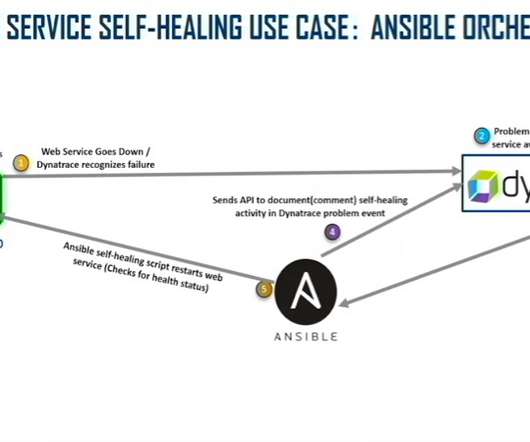
Each piece of the AIOps triumvirate plays a crucial role in the automation process to speed innovation. In the event of an outage or slowdown, Dynatrace generates a ticket in ServiceNow, which manages the workflow. Dynatrace Synthetic Monitoring and RUM simulate real-life events, such as reports and database queries.
Effective application development requires speed and specificity. This code is then executed on remote servers in response to an event, such as users interacting with functional web elements. Many organizations use function as a service when migrating to the cloud or for RESTful and event-driven applications. Dynatrace news.
Effortlessly analyze IBM i Performance with the new Dynatrace extension Dynatrace has created a new version of its popular extension that is faster, offers better interactive pages, and includes more metrics, metadata, and analytics without having to install anything on your mainframe infrastructure. It’s all monitored remotely !
The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs. Furthermore, OneAgent observes and gathers all remaining workload logs, metrics, traces, and events.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
Telemetry data — such as metrics, logs, and traces — gives IT teams crucial context to understand how all entities are connected. Without appropriate context, the so-called pillars of observability — metrics, logs, and traces — are simply sources of data, not insights. These are not only numerous but also dynamic.
To measure service quality, IT teams monitor infrastructure, applications, and user experience metrics, which in turn often support service level objectives (SLO)s. But these metrics and SLOs are only indirectly connected to business KPIs, which often leads to misplaced priorities, ineffective collaboration, and lost business opportunities.
Provide self-service platform services with dedicated UI for development teams to improve developer experience and increase speed of delivery. This includes out-of-the-box health alerts, health indicators, identification of problematic workload and node conditions, and warning events for various Kubernetes components.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content