This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional insight into HTTP monitor execution details For nearly two thousand Dynatrace customers, Dynatrace Synthetic HTTP monitors provide insights into the health of monitored endpoints worldwide and around the clock. It now fully supports not only Network Availability Monitors but also HTTP synthetic monitors.
That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines. Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. This customization ensures that only the relevant metrics are extracted, tailored to the users needs.
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
The Dynatrace platform has been recognized for seamlessly integrating with the Microsoft Sentinel cloud-native security information and event management ( SIEM ) solution. These reports are crucial for tracking changes, compliance, and security-relevant events. Runtime application protection.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
Davis is the causational AI from Dynatrace that processes billions of events and dependencies and constantly analyzes your IT infrastructure. Customize monitoring for a specific area of your IT infrastructure. Dynatrace metricevents offer the flexibility needed to customize your anomaly detection configuration.
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies.
In this blog post, we look at these enhancements, exploring methods for monitoring your Kubernetes environment and showcasing how modern dashboards can transform your data. Next, let’s use the Kubernetes app to investigate more metrics.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
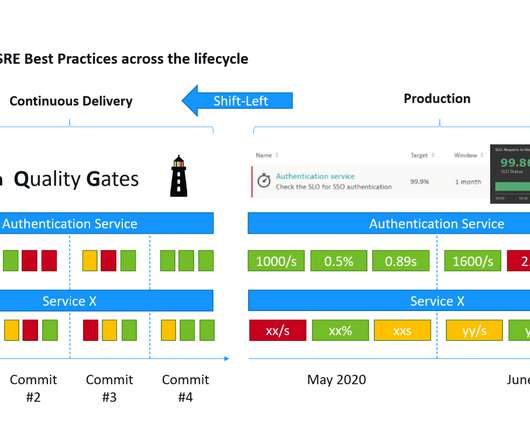
Breaking monolithic pipelines into event-driven Delivery Choreography. Embrace event-driven auto-remediation with an SLO-based safety net. It’s a free virtual event so I hope you join me. While an SLI is just a metric, an SLO just a threshold you expect your SLI to be in and SLA is just the business contract on top of an SLO.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. What is the difference between monitoring and observability? Is observability really monitoring by another name? What is observability? In short, no.
Traditional monitoring approaches often require manual scripting and integration to get alerted about production-threatening issues in pre-production environments. Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Recently, we’ve expanded our digital experience monitoring to cover the entire customer journey, from conversion to fulfillment.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Dynatrace users typically use extensions to pull technical monitoring data, such as device metrics, into Dynatrace.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all?
Dynatrace OneAgent allows teams to observe Google Kubernetes Engine pods , nodes, clusters, and workload metrics, events, and logs, in addition to automated distributed tracing for applications and microservices. The Dynatrace Clouds app provides a complete inventory of cross-cloud and cross-account resources. 2025 Dynatrace LLC.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. By analogy, envision an apple tree where an apple drops.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Carefully planning and integrating new processes and tools is critical to ensuring compliance without disrupting daily operations.
Dynatrace business events address these systemic problems, delivering real-time business observability to business and IT teams with the precision and context required to support data-driven decisions and improve business outcomes. However, in the real world, business-related data isn’t limited to metrics.
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
The volume of data and events grows in tandem with the rising complexity of IT infrastructure. Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. These can range from routine state transition events to critical problem reports.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? RUM gathers information on a variety of performance metrics.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
Monitoring Kubernetes is an important aspect of Day 2 o perations and is often perceived as a significant challenge. That’s another example where monitoring is of tremendous help as it provides the current resource consumption picture and help to continuously fine tune those settings. . Node and w orkload health .
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. First and foremost, it’s a data problem. Identify drops at each step.
Recent platform enhancements in the latest Dynatrace, including business events powered by Grail™, make accessing the goldmine of business data flowing through your IT systems easier than ever. Business events can come from many sources, including OneAgent®, external business systems, RUM sessions, or log files.
This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. This extension was built from scratch to take into account all we’ve learned and the special requirements for monitoring ephemeral, auto-scaling, micro VMs like AWS Lambda. A look under the hood of AWS Lambda.
Effortlessly analyze IBM i Performance with the new Dynatrace extension Dynatrace has created a new version of its popular extension that is faster, offers better interactive pages, and includes more metrics, metadata, and analytics without having to install anything on your mainframe infrastructure. It’s all monitored remotely !
Logging is integral to Kubernetes monitoring In the ever-changing and evolving software development landscape, logs have always been and continue to be – one of the most critical sources of insight. Easily derive metrics and events from logs for dashboarding and prediction.
While Fluentd solves the challenges of collecting and normalizing Kubernetes events and logs, Kubernetes performance and availability problems can rarely be solved by investigating logs in isolation. Precise, AI-powered anomaly root-cause determination based on automatic log analysis and custom user-defined events.
So, whenever your end users’ digital experience is bogged down by a problem, whether it’s the result of a synthetic test (browser and synthetic), mobile app monitoring, or web monitoring, your teams need to see the most pertinent information about the impact and the root cause at a glance.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. At Dynatrace we’re lucky to have Dynatrace monitor our workloads running on K8s. Not only do we have the detailed log, but we also know the API endpoint was the HTTP GET /event.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events.
AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. But increasing complexity and lacking visibility creates a problem: Enterprises invest more resources into monitoring and don’t get the data and answers they need.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. What is AWS observability?
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Stage 2: Service monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content