This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. To close these critical gaps, Dynatrace has defined a new class of events called business events.
Davis is the causational AI from Dynatrace that processes billions of events and dependencies and constantly analyzes your IT infrastructure. Dynatrace metricevents offer the flexibility needed to customize your anomaly detection configuration. Let’s configure anomaly detection on a metric.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
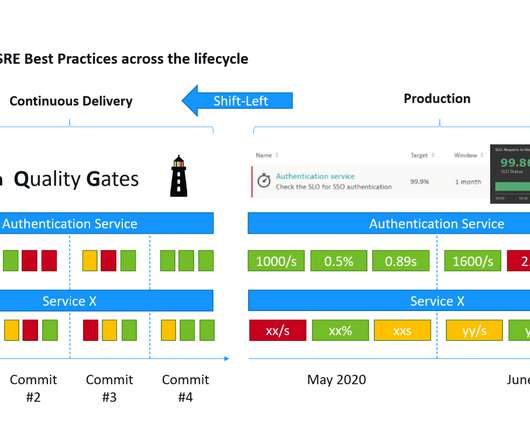
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
Breaking monolithic pipelines into event-driven Delivery Choreography. Embrace event-driven auto-remediation with an SLO-based safety net. It’s a free virtual event so I hope you join me. While an SLI is just a metric, an SLO just a threshold you expect your SLI to be in and SLA is just the business contract on top of an SLO.
Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. All metrics and events storing information about execution details are available for further exploratory analytics utilizing Dashboards, Notebooks, or Davis CoPilot.
The Dynatrace platform has been recognized for seamlessly integrating with the Microsoft Sentinel cloud-native security information and event management ( SIEM ) solution. These reports are crucial for tracking changes, compliance, and security-relevant events.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. See the following example with BurnRate formula for Failure rate event.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Dynatrace users typically use extensions to pull technical monitoring data, such as device metrics, into Dynatrace.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. If you’ve read about observability, you likely know that collecting the measurements of logs, metrics, and distributed traces are the three key pillars to achieving success.
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines. This data covers all aspects of CI/CD activity, from workflow executions to runner performance and cost metrics. Workflow overview The workflow, though simple, is highly effective.
Dynatrace business events address these systemic problems, delivering real-time business observability to business and IT teams with the precision and context required to support data-driven decisions and improve business outcomes. However, in the real world, business-related data isn’t limited to metrics.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. Its as simple as that!
While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer. The problem report below shows Dynatrace correctly detecting a CPU saturation event on an Ubuntu node.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
The volume of data and events grows in tandem with the rising complexity of IT infrastructure. While SNMP allows you to query monitored devices for performance information, SNMP traps are used to proactively report certain types of events. These can range from routine state transition events to critical problem reports.
It should also be possible to analyze data in context to proactively address events, optimize performance, and remediate issues in real time. It also helps to have access to OpenTelemetry, a collection of tools for examining applications that export metrics, logs, and traces for analysis.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Seasonal Baseline: Ideal for metrics with predictable seasonal patterns, this option leverages Davis AI to create a confidence band based on historical data, accounting for expected variations.
Business events are a special class of events, new to Business Analytics; together with Grail, our data lakehouse, they provide the precision and advanced analytics capabilities required by your most important business use cases. What are business events? This diagram shows a few examples of business events.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. User experiences go into many dimensions: business events, dashboards, session replay, synthetic checks which help with performance, reliability, and experience of digital interactions.
While Fluentd solves the challenges of collecting and normalizing Kubernetes events and logs, Kubernetes performance and availability problems can rarely be solved by investigating logs in isolation. Precise, AI-powered anomaly root-cause determination based on automatic log analysis and custom user-defined events.
They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions. These initial automation endeavors paved the way for greater advancements, leading to the next evolution of event-driven automation.
Traditional debugging methods, including manual inspection of logs, event streams, configurations, and system metrics, can be painstakingly slow and prone to human error, particularly under pressure.
We also explore how to improve user experiences within the Zero Trust framework and how to develop security metrics that eliminate DevSecOps bottlenecks. Episode 39 – Improving the User Experience in a Zero Trust World: Event Recap with Willie Hicks. Tune in for Mark and Willie’s highlights and takeaways from the event.
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all?
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Often, raised problems are the result of custom settings with fixed thresholds or the creation of custom events for alerting. The root cause analysis section now contains links to custom events for alerting and manual performance thresholds. Leverage AI assistance to deliver better customer experience.
Define custom events that can either trigger deeper analysis or contribute additional contextual information to Davis. The improved configuration workflow for custom event alerting offers a lot of power in terms of defining additional metric-based events for your Dynatrace environment. We opened up the Davis 2.0
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…? That’s late!
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
For example, you might be using: any of the 60+ StatsD compliant client libraries to send metrics from various programming languages directly to Dynatrace; any of the 200+ Telegraf plugins to gather metrics from different areas of your environment; Prometheus, as the dominant metric provider and sink in your Kubernetes space.
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. During this event, we generate a timestamp and store it in an eBPF hash map using the process ID as the key. ' They let us identify when a process is ready to run and is waiting for CPU time.
Incomplete view of the ordering process due to older systems Get business process observability across data silos with Dynatrace OpenPipeline Traditional observability platforms often focus on technical metrics and logs, which are essential for troubleshooting, but they don’t take business value into consideration.
Red Hat and Dynatrace integration overview The strategic partnership and integration between Red Hat and Dynatrace are game changers that solve each mentioned pain point: Easily ingest (and gain precise insights into) your logs, metrics, traces, and business data. In-context topology identification.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Using the source of truth: Logs serve as a reliable source of truth by providing a comprehensive record of system events.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. A pipeline can be the parent of multiple tasks to group the resulting events logically.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Load event start. Load event end.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content