This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is RabbitMQ?
A more scalable option is to decouple these systems and build a pipe that connects these engines and feeds all change records from the source database to the data warehouse (e.g., Triggers are powerful mechanisms that react to events dynamically and in real time. Amazon Redshift) and Elasticsearch machines.
Many organizations also adopt an observability solution to help them detect and analyze the significance of events to their operations, software development life cycles, application security, and end-user experiences. Making observability actionable and scalable for IT teams.
Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. This combination helps you improve the parallelism, scalability, and predictive accuracy of your Greenplum machine learning deployment. At a glance – TLDR. The Greenplum Architecture. Greenplum Advantages.
This article expands on the most commonly used RabbitMQ use cases, from microservices to real-time notifications and IoT. Key Takeaways RabbitMQ is a versatile message broker that improves communication across various applications, including microservices, background jobs, and IoT devices.
AWS Lambda is a serverless compute service that can run code in response to predetermined events or conditions and automatically manage all the computing resources required for those processes. Many events can trigger a lambda function. What is AWS Lambda? The Amazon Web Services ecosystem. A new record entering a database table.
Logs – Structured or unstructured text that record discreet events that occurred at a specific time. Data silos – Multiple agents, disparate data sources, and siloed monitoring tools make it hard to understand interdependencies across applications, multiple clouds, and digital channels such as web, mobile, and IoT.
Scalability is a major feature of GCF. The Cloud Functions platform enables teams to craft functional, extensible applications that run code when triggered by preset conditions or events. GCF also has relevance in IoT and file processing tasks. How Google Cloud Functions works. Avoid lock-in with open-source technologies.
In the Device Management Platform, this is achieved by having device updates be event-sourced through the control plane to the cloud so that NTS will always have the most up-to-date information about the devices available for testing. Upstream event sourcing was fully enabled on the producer side at around 2021–07–15 15:00 PST.
It is only such vendor-neutral, 4-day, 5-track conference devoted completely to performance, capacity, scalability, and adjacent topics. The conference includes 80+ presentations on performance, capacity, cloud, IoT, security (and more) from best experts in these areas and several great panels. More information here. Full program.
It particularly stands out in several fields, such as: Telecommunications Healthcare Finance E-commerce IoT Within these domains, RabbitMQ harnesses its potential to process substantial data and manage real-time operations effectively. Components can operate independently, confident that messages will be delivered reliably.
The population of intelligent IoT devices is exploding, and they are generating more telemetry than ever. The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processing IoT telemetry, from its arrival in the cloud through its storage in databases and data lakes.
The council has deployed IoT Weather Stations in Schools across the City and is using the sensor information collated in a Data Lake to gain insights on whether the weather or pollution plays a part in learning outcomes. Real-time monitoring and evaluation of events have led to a positive impact on performance or operations.
Amazon ML is highly scalable and can generate billions of predictions, and serve those predictions in real-time and at high throughput. When we designed Amazon EFS we decided to build along the AWS principles: Elastic, scalable, highly available, consistent performance, secure, and cost-effective.
The Real-time File Processing reference architecture is a general-purpose, event-driven, parallel data processing architecture that uses AWS Lambda. This simple architecture is described in the "Fanout S3 Event Notifications to Multiple Endpoints" blog post on the AWS Compute Blog. IoT Backend Serverless Reference Architecture.
The Real-time File Processing reference architecture is a general-purpose, event-driven, parallel data processing architecture that uses AWS Lambda. This simple architecture is described in the "Fanout S3 Event Notifications to Multiple Endpoints" blog post on the AWS Compute Blog. IoT Backend Serverless Reference Architecture.
After the launch of the AWS APAC (Hong Kong) Region, there will be 19 Availability Zones in Asia Pacific for customers to build flexible, scalable, secure, and highly available applications. In 2010, we opened our first AWS Region in Singapore and since then have opened additional regions: Japan, Australia, China, Korea, and India.
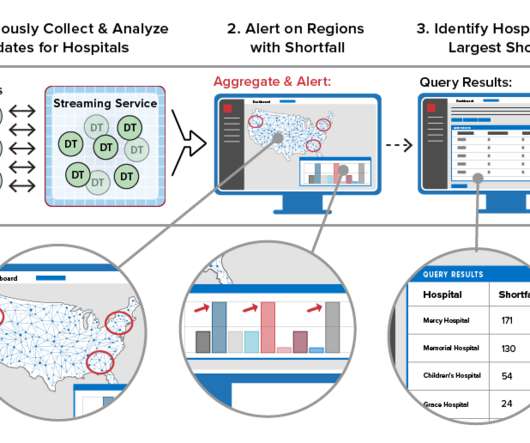
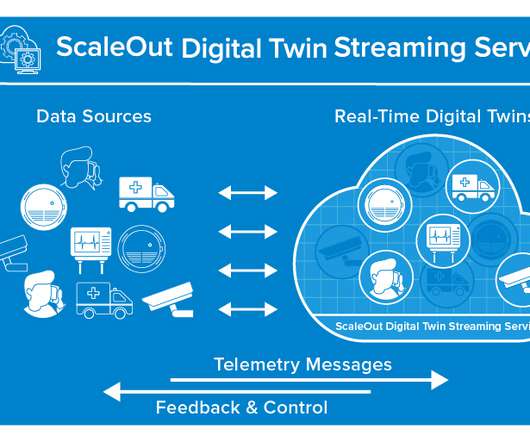
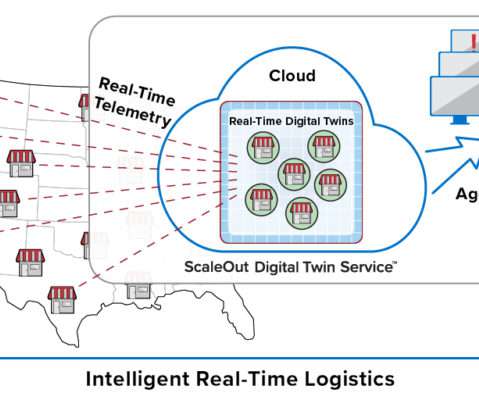
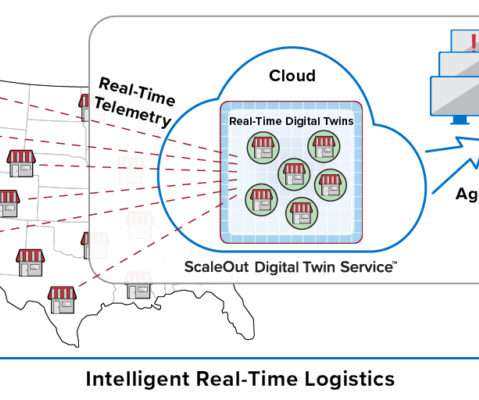
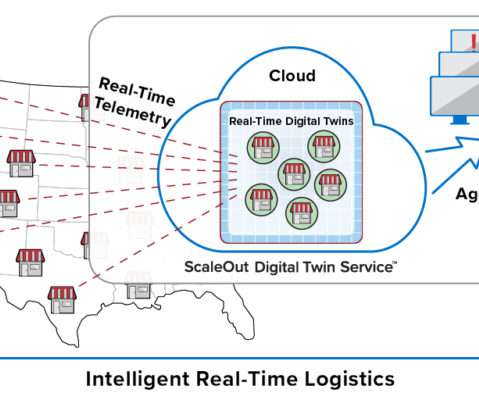
Digital twins are software abstractions that track the behavior of individual devices in IoT applications. They combine an event handling function with state information about each device. Also, the use of digital twins provides automatic correlation of incoming events for each device, thereby simplifying applications.
This model organizes key information about each data source (for example, an IoT device, e-commerce shopper, or medical patient) in a software component that tracks the data source’s evolving state and encapsulates algorithms, such as predictive analytics, for interpreting that state and generating real-time feedback.
We are increasingly surrounded by intelligent IoT devices, which have become an essential part of our lives and an integral component of business and industrial infrastructures. In-memory computing has the speed and scalability needed to generate responses within milliseconds, and it can evaluate and report aggregate trends every few seconds.
Digital twins are software abstractions that track the behavior of individual devices in IoT applications. They combine an event handling function with state information about each device. Also, the use of digital twins provides automatic correlation of incoming events for each device, thereby simplifying applications.
A second and equally daunting challenge for live systems is to maintain real-time situational awareness about the state of all data sources so that strategic responses can be implemented, especially when a rapid sequence of events is unfolding.
A second and equally daunting challenge for live systems is to maintain real-time situational awareness about the state of all data sources so that strategic responses can be implemented, especially when a rapid sequence of events is unfolding.
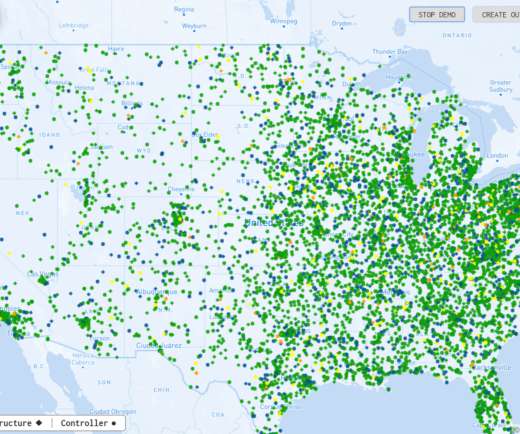
Event streams typically combine messages from many data sources, as shown below. For these reasons, most streaming applications only perform rudimentary analysis (often in the form of queries) on the incoming data stream and push most of the event messages into a data lake for offline examination. We invite you to check it out.
Event streams typically combine messages from many data sources, as shown below. For these reasons, most streaming applications only perform rudimentary analysis (often in the form of queries) on the incoming data stream and push most of the event messages into a data lake for offline examination. We invite you to check it out.
Coverage Deploying Wi-Fi in expansive areas like airports or event venues can be complex and costly due to the need for numerous access points. In IoT applications, devices generate massive amounts of data, and organizations must be able to process it rapidly to leverage it to its full potential.
This model organizes key information about each data source (for example, an IoT device, e-commerce shopper, or medical patient) in a software component that tracks the data source’s evolving state and encapsulates algorithms, such as predictive analytics, for interpreting that state and generating real-time feedback.
Event streams typically combine messages from many data sources, as shown below. For these reasons, most streaming applications only perform rudimentary analysis (often in the form of queries) on the incoming data stream and push most of the event messages into a data lake for offline examination. We invite you to check it out.
Traditional stream-processing and complex event processing systems, such as Apache Storm and Software AG’s Apama , have focused on extracting interesting patterns from incoming data with stateless applications. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report.
Traditional stream-processing and complex event processing systems, such as Apache Storm and Software AG’s Apama , have focused on extracting interesting patterns from incoming data with stateless applications. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report.
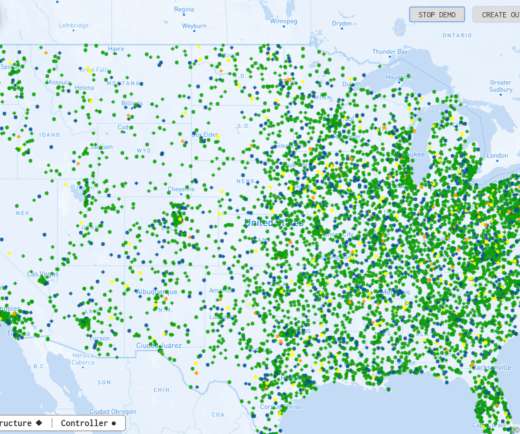
It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. What’s needed is the ability to easily track incoming telemetry from each individual store so that issues can be quickly analyzed, prioritized, and handled.
It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. What’s needed is the ability to easily track incoming telemetry from each individual store so that issues can be quickly analyzed, prioritized, and handled.
It’s not enough to just pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Traditional platforms for streaming analytics don’t offer the combination of granular data tracking and real-time aggregate analysis that logistics applications such as these require.
uses an event-driven and non-blocking I/O model, so it is practical and lightweight. IoT-based applications. Scalability: Applications developed with Node.js Developers are able to create scalable and fast apps suitable for all platforms due to its “learn once write anywhere” principle. Developing API. Where to Use React.
including iPhones/ mobile devices, set-top boxes, game stations, and IoT devices. Mega-scale load testing –load testing should scale up to millions of users within seconds to emulate the speed and scale of virtually any high-profile event worldwide.
To keep up with the testing demand there are a number of feature requirements needed in order to be called a modern performance testing platform: Mega-scale load testing — load testing should scale up to millions of users within seconds to emulate the speed and scale of virtually any high-profile event worldwide.
When your business involves millions of small, fleeting chances to influence an event in the customer’s favor, or, in the case of something like credit card fraud prevention, stop an event from happening altogether, time is ‘of the essence’, and you may need everything to be very fast to make up for how long your AI decisions take.
HOW VOLT SOLVES LATENCY VS THROUGHPUT, WITHOUT SACRIFICES Volt Active Data is the only real-time data processing platform that combines the immediacy of event stream processing with the state-based consistency of a blazingly fast in-memory database and the decisioning intelligence of a sophisticated rules engine.
Indeed, real-time decisioning has become a critical capability for automotive manufacturers looking to stay competitive in the age of AI and IoT. Respond to disruptions: Supply chain disruptions, such as natural disasters or geopolitical events, can have a significant impact on production.
Discover how their solution saves customers hours of manual effort by automating the analysis of tens of thousands of documents to better manage investor events, report internally to executive teams, and find new investors to target. After re:Invent, I will update this post with the videos from the event, as I did last year.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content