This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Membership in MISA is nomination-only and reserved for independent software vendors who develop security solutions that effectively integrate with MISA-qualifying Microsoft Security products. These reports are crucial for tracking changes, compliance, and security-relevant events.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. It should also be possible to analyze data in context to proactively address events, optimize performance, and remediate issues in real time.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
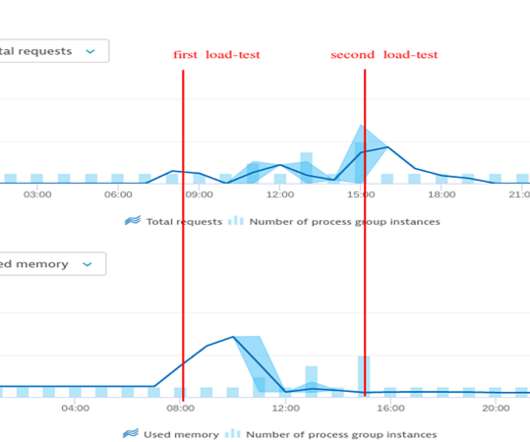
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing.
Unify tools to eliminate redundancies, rein in costs, and ease compliance : This not only lowers the total cost of ownership but also simplifies regulatory audits and improves software quality and security. Standardizing platforms minimizes inconsistencies, eases regulatory compliance, and enhances software quality and security.
That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines. Everyone involved in the software delivery lifecycle can work together more effectively with a single source of truth and a shared understanding of pipeline performance and health.
Infrastructure complexity is costing enterprises money. AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. As 69% of CIOs surveyed said, it’s time for a “radically different approach” to infrastructure monitoring.
This leads to frustrating bottlenecks for developers attempting to build and deliver software. A central element of platform engineering teams is a robust Internal Developer Platform (IDP), which encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications.
Carbon Impact leverages business events , a special data type designed to support the real-time accuracy and long-term granularity demands common to business use cases. The app automatically builds baselines, important reference points for analyzing the environmental impact of individual hardware or software instances.
AWS Security Hub findings AWS Security Hub provides a great way of aggregating security findings, especially those related to cloud infrastructure. Findings from various stages of the Software Development Lifecycle (SDLC) are mixed in: code scans, build scans, and runtime. This increases the number of findings to prioritize.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
If you’re doing it right, cloud represents a fundamental change in how you build, deliver and operate your applications and infrastructure. And that includes infrastructure monitoring. This also implies a fundamental change to the role of infrastructure and operations teams. Able to provide answers, not just data.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Easily diagnose possible security breaches or software malfunctions. Identify under-performing DNS servers.
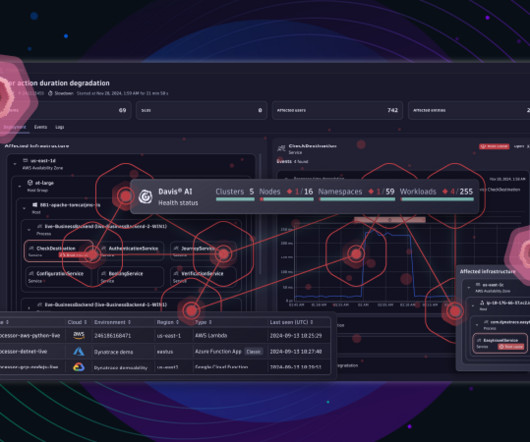
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all?
Infrastructure and operations teams must maintain infrastructure health for IT environments. Any problem, such as a simple software update overburdening a critical database, can cause a ripple effect that degrades the performance of dependent services or applications.
They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions. These initial automation endeavors paved the way for greater advancements, leading to the next evolution of event-driven automation.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice?
For organizations running their own on-premises infrastructure, these costs can be prohibitive. Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. What is always-on infrastructure?
When organizations implement SLOs, they can improve software development processes and application performance. SLOs improve software quality. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time.
Software and data are a company’s competitive advantage. That’s because every company is now a software company. As a result, organizations need software to work perfectly to create customer experiences, deliver innovation, and generate operational efficiency. That’s exactly what a software intelligence platform does.
Data sources typically include common infrastructure monitoring tools and second-generation APM solutions as well as other solutions. Typically, only the alert (potentially with some metadata) would be then handed over to the AIOps solution meaning only the aggregated event will be accessible to ML without many additional details.
A utomatic detection of software service and application availability (including microservices and containers) . Application and infrastructure data collection . Automatic detection of service health and performance incidences, which are synchronized into the Event Management Dashboard. . Prioritize event entries .
Why organizations are turning to software development to deliver business value. Digital immunity has emerged as a strategic priority for organizations striving to create secure software development that delivers business value. Software development success no longer means just meeting project deadlines. Autonomous testing.
Host extensions enable you to add additional metrics, events, and properties to hosts. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. Looking for ways to solve some of your infrastructure-related problems? What’s next.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
In an era dominated by automated, code-driven software deployments through Kubernetes and cloud services, human operators simply can’t keep up without intelligent observability and root cause analysis tools. This approach ensures that your operation teams have all the tools they need to manage modern software deployments.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. The architects and developers who create the software must design it to be observed.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. Dynatrace Davis AI identifies the problem and maps the configuration change event to the root cause and the correct entity.
As businesses take steps to innovate faster, software development quality—and application security—have moved front and center. According to GitLab’s 2021 Global DevSecOps Survey , 36% of respondents develop software using DevSecOps, compared with only 27% in 2020. Increased adoption of Infrastructure as code (IaC).
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. where an error occurred at the code level.
Dynatrace enables our customers to monitor and optimize their cloud infrastructure and applications through the Dynatrace Software Intelligence Platform. A big part to the success within Dynatrace is that we use Dynatrace® across the software lifecycle on our own software projects. Dynatrace news.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Monolithic architectures were commonplace with legacy, on-premises software solutions.
Across both his day one and day two mainstage presentations, Steve Tack, SVP of Product Management, described some of the investments we’re making to continue to differentiate the Dynatrace Software Intelligence Platform. Next-gen Infrastructure Monitoring. Next up, Steve introduced enhancements to our infrastructure monitoring module.
But the Red Hat Ansible Automation Platform integration with the Dynatrace Software Intelligence Platform takes automated remediation to a whole new level. The market offers plenty of monitoring solutions that can link a specific monitored event with a specific scripted action. Dynatrace news.
The Dynatrace Software Intelligence Hub helps enterprises easily apply AI to all technologies and data sources and unlock automation at scale. A broad range of infrastructure components, open data frameworks, mobile platforms and frameworks (iOS, Android, Flutter, Xamarin, React, and others), and many more are also fully supported.
According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. The ability to effectively manage multi-cluster infrastructure is critical to consistent and scalable service delivery.
Distributed tracing follows an interaction by tagging it with a unique identifier, which stays with it as it interacts with microservices, containers, and infrastructure. It can also offer real-time visibility into user experience, from the top of the stack right down to the application layer and the large-scale infrastructure beneath.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. With the help of log monitoring software, teams can collect information and trigger alerts if something happens that affects system performance and health. What is log monitoring?
Challenges The cloud network infrastructure that Netflix utilizes today consists of AWS services such as VPC, DirectConnect, VPC Peering, Transit Gateways, NAT Gateways, etc and Netflix owned devices. These metrics are visualized using Lumen , a self-service dashboarding infrastructure.
Deploying and safeguarding software services has become increasingly complex despite numerous innovations, such as containers, Kubernetes, and platform engineering. Recent global IT outages, such as the CrowdStrike incident, remind us how dependent society is on software that works perfectly.
It is monitoring software that integrates with a wide range of systems natively or through the use of plugins. Prometheus can collect metrics about your application and infrastructure. Metrics are small concise descriptions of an event: date, time, and a descriptive value.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content