This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Event-driven automation enables systems to react instantly to specific triggers or events, enhancing infrastructure resilience and efficiency. A simple and effective method for implementing event-driven automation is through webhooks, which can initiate specific actions in response to events.
One of the promises of container orchestration platforms is to make i t easier for the developers to accelerate the deployment of their app lication s without having to worry about scalability and infrastructure dependencies. Kubernetes events are a type of object providing context on what ’s happening inside a cluster.
Anyone moving to the cloud knows that it isn’t just a change from running servers in your data center to running them in someone else’s data center. If you’re doing it right, cloud represents a fundamental change in how you build, deliver and operate your applications and infrastructure. And that includes infrastructure monitoring.
Applications and services are often slowed down by under-performing DNS communications or misconfigured DNS servers, which can result in frustrated customers uninstalling your application. Identify under-performing DNS servers. Slower response times can be a sign of a stressed DNS server or network communication issues.
The HANA DB monitoring extension uses a remote connection to pull performance data from the HANA DB server (using that same mechanisms that SAP tools use) while distilling the information that’s essential to KPIs. No agent installation is required on your SAP server. Avoid false positives with auto-adaptive baselining.
Modern service infrastructure depends heavily on IT’s ability to dynamically scale the number of hosts up or down, depending on the expected workload. To avoid false-positive alerts, Dynatrace availability alerting for servers automatically detects the planned downscaling of AWS spot instances. Dynatrace news.
In those cases, what should you do if you want to be proactive and ensure that your infrastructure is always up and running? Are you looking to monitor your infrastructure using one of our ready-made extensions, or would you like to draw on our experience and create your own synthetic monitors? Platform extensions.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is Apache Kafka?
They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions. These initial automation endeavors paved the way for greater advancements, leading to the next evolution of event-driven automation.
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
A single instance of OneAgent can handle the monitoring of many types of entities , including servers, applications, services, databases, and more. Host extensions enable you to add additional metrics, events, and properties to hosts. Looking for ways to solve some of your infrastructure-related problems? Dynatrace news.
As recent events have demonstrated, major software outages are an ever-present threat in our increasingly digital world. From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing. This often occurs during major events, promotions, or unexpected surges in usage.
The market offers plenty of monitoring solutions that can link a specific monitored event with a specific scripted action. To begin this prescriptive approach, we perform the initial deployment of infrastructure and applications with Ansible Automation Platform, providing a more consistent and predictable environment.
Serverless architecture shifts application hosting functions away from local servers onto those managed by providers. This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Enhancing event ingestion. Let’s get started. Simplicity.
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. How does Dynatrace help?
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events.
Now, Dynatrace has gone a step further and expanded its coverage and intelligent observability into the next layer: database infrastructure. Easily track the health and performance of database servers with AI support. Start monitoring your Oracle and MS SQL Server databases today to improve your database intelligent observability.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
Logs represent event data in plain-text, structured or binary format. But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. Traces help find the flow of a request through a distributed system. Monitoring your i nfrastructure.
Wondering whether an on-premise vs. public cloud vs. hybrid cloud infrastructure is best for your database strategy? Cloud Infrastructure Analysis : Public Cloud vs. On-Premise vs. Hybrid Cloud. Popular examples of commercial databases include Oracle, SQL Server, and DB2. Cloud Infrastructure Breakdown by Database.
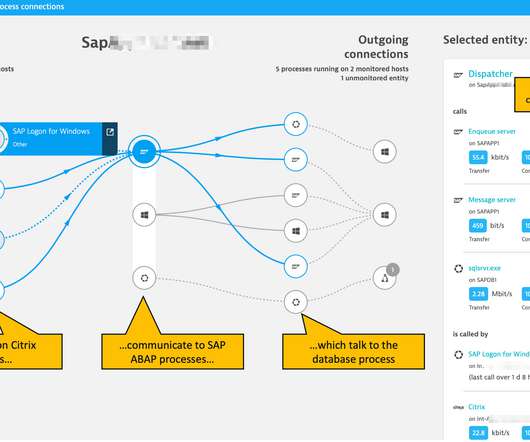
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace Extension: database performance as experienced by the SAP ABAP server. OneAgent: Citrix infrastructure performance. SAP server. Citrix VDA.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources.
While today’s IT world continues the shift toward treating everything as a service, many organizations need to keep their environments under strict control while managing their infrastructure themselves on-premises. Events and alerts. Some SNMP-enabled devices are designed to report events on their own with so-called SNMP traps.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
If the primary server encounters issues, operations are smoothly transitioned to a standby server with minimal interruption. Key Takeaways PostgreSQL automatic failover enhances high availability by seamlessly switching to standby servers during primary server failures, minimizing downtime, and maintaining business continuity.
The first step is determining whether the problem originates from the application or the underlying infrastructure. On Titus , our multi-tenant compute platform, a "noisy neighbor" refers to a container or system service that heavily utilizes the server's resources, causing performance degradation in adjacent containers.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier. Event Item : An event item is a key-value pair that users use to store data for a given event.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices.
An easy, though imprecise, way of thinking about Netflix infrastructure is that everything that happens before you press Play on your remote control (e.g., Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. are you logged in?
Running workloads on top of Kubernetes is significantly valuable, not just for application teams, but for infrastructure teams as well. Dynatrace provides the insights to help teams determine this, while also uncovering a range of additional insights, including event tracking and over-commitment rate. More about Kubernetes.
Cloud migration enables IT teams to enlist public cloud infrastructure so an organization can innovate without getting bogged down in managing all aspects of IT infrastructure as it scales. They need ways to monitor infrastructure, even if it’s no longer on premises. Right-sizing infrastructure.
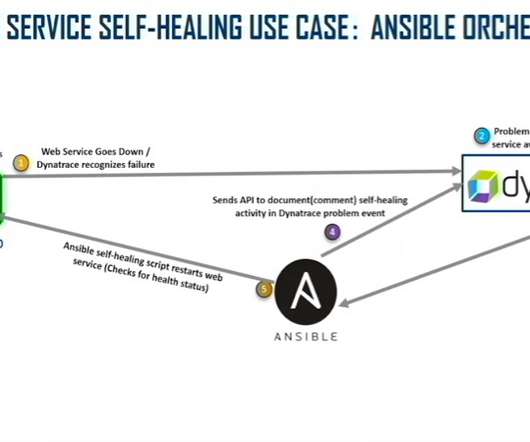
At Dynatrace Perform 2022 , David Walker, a Lockheed Martin Fellow, and William Swofford, a full-stack engineer at Lockheed Martin, discuss how to create a self-diagnosing and self-healing IT server environment using this AIOps combination for auto-baselining, auto-remediation, monitoring as code, and more. An example of the self-healing web.
This extends Dynatrace visibility into SAP ABAP performance from the infrastructure and ABAP application platform perspective. As of today, the SAP ABAP application server remains the central component of the SAP ERP solution. The Dynatrace ActiveGate extension queries SAP servers for key performance counters.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Logs can also be used to represent event data. Cloud provider/infrastructure layer.
The Dynatrace ® unified observability and security platform addresses the needs of enterprise-edge scenarios by managing the health and performance of containerized applications and multi-cloud infrastructures with metrics, traces, and logs in one place.
See all detected databases All databases running on your server instances are autodetected, so you can easily check your database performance statistics and settings. Drill down into further details You can review the availability and performance of high availability replicas and AlwaysOn groups in SQL Server.
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. Whereas log monitoring is the process of tracking ingested and recorded logs, log analytics evaluates those logs and their context for the significance of the events they represent.
However, serverless applications have unique characteristics that make observability more difficult than in traditional server-based applications. Serverless applications are composed of event-driven functions that run on demand in response to triggers from various sources, such as HTTP requests, messages, or timers.
As organizations expand their cloud footprints, they are combining public, private, and on-premises infrastructures. But modern cloud infrastructure is large, complex, and dynamic — and over time, this cloud complexity can impede innovation. “We used Dynatrace to monitor that large increase in servers. Dynatrace news.
The time from browser request to the first byte of information from the server. Load event start. The time it takes to begin the page’s load event. Load event end. The time it takes to complete the page’s load event. The time taken to complete the page load. Time to first byte. Time to render.
This is especially true when we consider the explosive growth of cloud and container environments, where containers are orchestrated and infrastructure is software defined, meaning even the simplest of environments move at speeds beyond manual control, and beyond the speed of legacy Security practices. And this poses a significant risk.
Vidhya Arvind , Rajasekhar Ummadisetty , Joey Lynch , Vinay Chella Introduction At Netflix our ability to deliver seamless, high-quality, streaming experiences to millions of users hinges on robust, global backend infrastructure. This model supports both simple and complex data models, balancing flexibility and efficiency.
In this article, I will share some of the best practices to help you understand and survive the current situation — as well as future proof your applications and infrastructure for similar situations that might occur in the months and years to come. There are proven strategies for handling this. Step 6: Automate the Workflow.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content