This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. there is a dedicated collector.
Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance. Our streaming teams need a monitoring system that enables them to quickly diagnose and remediate problems; seconds count!
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. By watching applications for anomalous actions, security and operations teams can monitor unusual and erroneous behavior. Wednesday?—?December
Examples range from online banking to personal entertainment delivery and e-commerce. Web Application Firewall (WAF) helps protect a web application against malicious HTTP traffic. The most common web traffic transforms implement URL encryption, cookie signing, and anti-CSRF tokens to block CSRF attacks.
We needed to serve our growing base of startup, government, and enterprise customers across many vertical industries, including automotive, financial services, media and entertainment, high technology, education, and energy. To meet such large traffic numbers, they need a technology infrastructure that is secure, reliable, and flexible.
Website and Web Application Monitoring. Web monitoring is a comprehensive term that describes the activity of testing a website or web application for its availability and performance. Users who rely on the websites for their fundamental needs or entertainment will not tolerate even a few seconds delay. HTTP Monitoring.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. By watching applications for anomalous actions, security and operations teams can monitor unusual and erroneous behavior. Wednesday?—?December
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. By watching applications for anomalous actions, security and operations teams can monitor unusual and erroneous behavior. Wednesday?—?December
Example use case: Content Knowledge Graph Our knowledge graph of the entertainment world encodes relationships between titles, actors and other attributes of a film or series, supporting all aspects of business at Netflix. The back-end auto-scales the number of instances used to back your service based on traffic.
Applications can be horizontally scaled with Kubernetes by adding or deleting containers based on resource allocation and incoming traffic demands. It distributes the load among containers and nodes automatically, ensuring that your application can handle any spike in traffic without the need for manual intervention from an IT staff.
The modern HMI is a mix of a car control center with an entertainment system. Digital cockpit and entertainment system. At the end of the day, the system can monitor real-time situations and prevent traffic collisions and accidents. vehicle settings such as suspension, climate control, entertainment system, and so on).
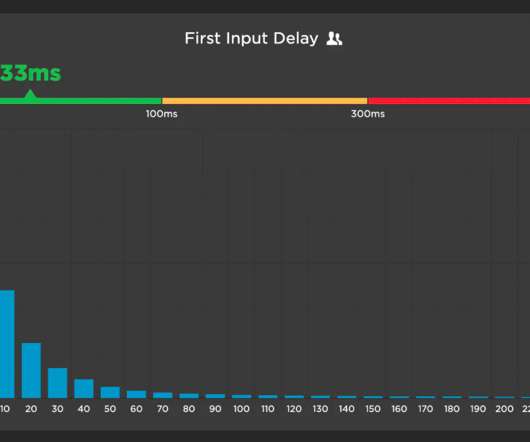
This metric is unique among the three Web Vitals in that it is can only be measured using real user monitoring (RUM), while the other two (Largest Contentful Paint and Cumulative Layout Shift) can be measured using both RUM and synthetic monitoring. FID is only measurable with real user monitoring (field data).
For example, an e-commerce company can use real-time data on website traffic and customer behaviors to adjust pricing or launch targeted promotions during peak shopping periods. As a result, they’re able to respond swiftly to changing market conditions, customer needs, and operational challenges.
Because we would like to time-travel all the services together to replicate a specific point in time in the past, we created a new capability to start stacks of multiple services with a common time configuration and route traffic between them on-the-fly per experiment to maintain temporal accuracy of the data.
Because we would like to time-travel all the services together to replicate a specific point in time in the past, we created a new capability to start stacks of multiple services with a common time configuration and route traffic between them on-the-fly per experiment to maintain temporal accuracy of the data.
Because we would like to time-travel all the services together to replicate a specific point in time in the past, we created a new capability to start stacks of multiple services with a common time configuration and route traffic between them on-the-fly per experiment to maintain temporal accuracy of the data.
As a company, we aim to be curious, and to truly and honestly understand our members around the world, and how we can better entertain them. This series has focused on fixed time horizon tests: sample sizes, the proportion of traffic allocated to each treatment experience, and the test duration are all fixed in advance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content