This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Chaos engineering is a useful way to test and improve system resilience by intentionally creating controlled failures. This article explores ways to make chaos engineering more cost-effective while maintaining its quality and reliability. However, their complexity can lead to unexpected failures.
To enhance reliability, testing the software under these conditions is crucial to prepare for potential issues by leveraging chaos engineering or similar tools. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues. It forms the cornerstone of chaos engineering experiments.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. These practices are commonly known as “ chaos engineering. ”
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Also be aware that the extraction where it says “between TSN= and ;”: Request Attributes extract meta data on a request level such as Test Step Name, Virtual User Id …. Dynatrace news.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Organizations can then integrate these skilled engineers at key points in the DevOps life cycle. Dynatrace news.
It makes sense for DevOps engineers and architects to perform canary deployments in their CI/CD workflows. They cannot skip testing a release for the sake of adhering to continuous delivery practices, can they? In canary deployments, the new version, called canary, is tested with limited live traffic at first.
Organizations running these ESXi versions should prioritize implementing the recommended patches or mitigations to protect their virtualization infrastructure from these significant security threats. This advisory addresses three distinct vulnerabilities with severity ratings ranging from High to Critical and CVSSv3 scores of 7.1
In this exclusive interview, Nicolas Vibert — senior technical engineer at Isovalent — traces this evolution and explains how open-source projects like eBPF and Cilium are continuing to drive advanced networking use cases for the modern cloud era.
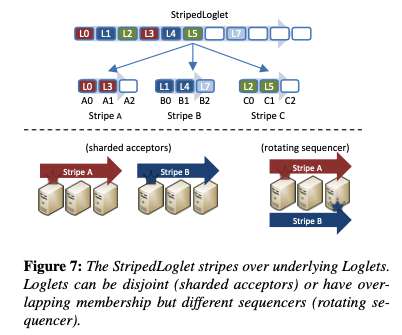
Virtual consensus in Delos , Balakrishnan et al. Back in 2017 the engineering team at Facebook had a problem. If you think of this a bit like mapping memory addresses to data in memory, then another parallel comes to mind: the virtual address space. We propose the novel abstraction of a virtual shared log (or VirtualLog).
Some of these instances have been containerized over the years, but many still run in the traditional setup of a virtual machine with Linux. Red Hat JBoss Web Server (JWS) combines a web server (Apache HTTPD), a servlet engine (Apache Tomcat), and modules for load balancing (mod_jk and mod_cluster).
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
Hardware virtualization for cloud computing has come a long way, improving performance using technologies such as VT-x, SR-IOV, VT-d, NVMe, and APICv. It's an exciting development in cloud computing: hardware virtualization is now fast. That's deliberate engineering: optimizing the most important workloads first.
Some of these instances have been containerized over the years, but many still run in the traditional setup of a Linux -based virtual machine or even on bare metal. Red Hat JBoss Web Server (JWS) combines the servlet engine (Apache Tomcat) with the web server (Apache HTTPD), and modules for load balancing (mod_jk and mod_cluster).
Today, Google announced virtual machines (VMs) based on the Arm architecture on Compute Engine called Tau T2A , which are optimized for cost-effective performance for scale-out workloads, as well as GKE Arm. Meet Davis, our powerful AI-engine | Dynatrace. Arm architecture. Get started using Dynatrace for GKE monitoring today .
Saving your cloud operations and SRE teams hours of guesswork and manual tagging, the Davis AI engine analyzes billions of events in real time. Auto-detection starts monitoring new virtual machines as they are deployed.
This ranges from deploying virtual machines and configuring software to ensuring that software development operations are proceeding efficiently and reliably. Additionally, DevOps engineers can specify automated quality gates that evaluate code early in the CI/CD pipeline to reduce the chance of deploying code with errors.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. The newer, pluggable storage engine, WiredTiger, addresses this by using prefix compression, collection-level locking, and row-based storage.
There are three current underlying reasons for the platform engineering meme today. The virtualization and networking platform could be datacenter based, with something like VMware, or cloud based using one of the cloud providers such as AWS EC2. The second is that some companies with tools to sell are marketing the term.
By Vi Iyengar , Keila Fong , Hossein Taghavi , Andy Yao , Kelli Griggs , Boris Chen , Cristina Segalin , Apurva Kansara , Grace Tang , Billur Engin , Amir Ziai , James Ray , Jonathan Solorzano-Hamilton Welcome to the first post in our multi-part series on how Netflix is developing and using machine learning (ML) to help creators make better media?—?
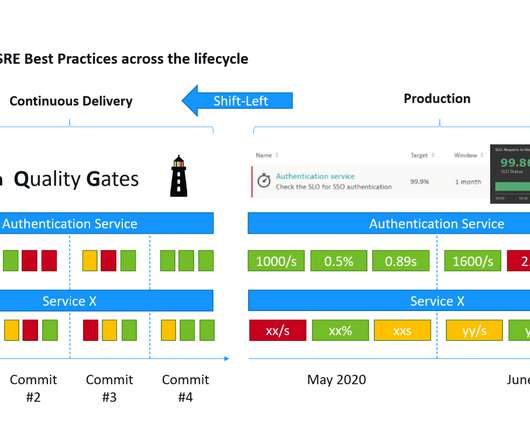
It’s a free virtual event so I hope you join me. If you’re not familiar with Site Reliability Engineering (SRE) and the concepts of Service Level Indicators (SLIs), Service Level Objectives (SLOs) and Service Level Agreements (SLAs) I recommend watching the YouTube Video from Google Engineers called SLIs, SLOs, SLAs, oh my!
Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. This helps significantly in automatically answering complex questions such as “ Is the CPU saturation of my F5 device caused by any of the virtual servers running on it?
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. In some deployment scenarios, you might skip CloudWatch altogether.
With Dynatrace for Government , you simply configure a local gateway server, set up your single sign-on (this setup will require support from our FedRAMP D ev O ps team), and deploy the automated One Agent to your physical or virtual hosts. . Your systems are managed by US-based and vetted engineers . Conclusion .
Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Accordingly, the remaining 27% of clusters are self-managed by the customer on cloud virtual machines.
If you’re unable to join us in Las Vegas, be sure to register to attend virtually —or view sessions on-demand afterward—so you don’t miss out! Register now to attend in person (or virtually). Read on to learn what you can look forward to hearing about from each of our cloud partners at Perform.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
While there are still quite a lot of cases where it is still applicable, it needs to evolve into more sophisticated processes tightly integrated with development and other parts of performance engineering. Data preparation and service virtualization functionality/tools would be here very handy here.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Average query response time. Number of reported errors (including RCODE ) to facilitate diagnosis.
On May 8, OReilly Media will be hosting Coding with AI: The End of Software Development as We Know It a live virtual tech conference spotlighting how AI is already supercharging developers, boosting productivity, and providing real value to their organizations.
Virtual Assembly Figure 3 describes how a virtual assembly of the encoded chunks replaces the physical assembly used in our previous architecture. Just as with virtual memory management systems, locality of reference is important in determining the active cache size and performance. We’re hiring!
Berkeley Packet Filter (BPF) is an in-kernel execution engine that processes a virtual instruction set, and has been extended as eBPF for providing a safe way to extend kernel functionality. What is BPF? In some ways, eBPF does to the kernel what JavaScript does to websites: it allows all sorts of new applications to be created.
This orchestration layer uses software-based tools to automate IT tasks and manage resources—virtualized or other. An orchestration tool can create a new virtual machine instance and determine the best location in the cloud for deploying that instance. Support virtual machines and containers.
DevOps teams, SREs (site reliability engineers), platform teams, and SecOps teams aren’t always working from a common source of truth: SAST tools (static application security testing) provide scanning code for vulnerabilities. Runtimes like Java Virtual Machine (JVM) and.NET CLR, or Node.js
At the same time, Dynatrace AI engine, Davis® saves additional time and resources by automatically identifying and prioritizing alerts from Kubernetes applications and infrastructure. Dynatrace also has many other Azure services, such as Virtual Machines, Functions, App Services, Spring Cloud, Service Fabric, and Virtual Machine Scale Sets.
At our virtual conference, Dynatrace Perform 2022 , the theme is “Empowering the game changers.”. Organizations seek to modernize, reduce costs, and adjust to the realities of globalization, increased competition in virtually every industry, and shifts in economic development since the emergence of COVID-19.
IT admins can automate virtually any time-consuming task that requires regular application. As organizations continue to adopt multicloud strategies, the complexity of these environments grows, increasing the need to automate cloud engineering operations to ensure organizations can enforce their policies and architecture principles.
Many Site Reliability Engineers could do without the frustrations of managing virtual or bare-metal compute nodes. Dynatrace news. Though serverless platforms relieve them from this burden, such platforms are built using Kubernetes alternatives that require different APIs, orchestration tools, and observability requirements.
Each service comes with zero-configuration, automatic instance detection, continuous data capture in context, and what’s most important – thanks to our AI engine Davis – is each service provides answers, not just data. Top use cases include recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.
In addition to providing visibility for core Azure services like virtual machines, load balancers, databases, and application services, we’re happy to announce support for the following 10 new Azure services, with many more to come soon: Virtual Machines (classic ones). Azure Virtual Network Gateways. Azure Batch.
Host analysis focuses on operating systems, virtual machines, and containers to understand if there are software components with known vulnerabilities that can be patched. This is done by scanning targets such as application code, network infrastructure, or virtual machines. Identify vulnerabilities. Analyze findings.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. You haven’t detected that there’s a shortage of disk space on the virtualization host (or its shared storage). Conclusion.
Saving your cloud operations and site reliability engineering teams hours of guesswork and manual tagging, the Davis AI engine analyzes billions of events in real time. Auto-detection starts monitoring new virtual machines as they are deployed. Modern cloud done right.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content