This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In Kubernetes , Ingress resources are frequently used as traffic controllers, providing external access to services within the cluster. This blog post will walk you through the process of blocking your site's indexing on Kubernetes Ingress using robots.txt file, preventing search engine bots from crawling and indexing your content.
We have developed a microservices architecture platform that encounters sporadic system failures when faced with heavy traffic events. System resilience stands as the key requirement for e-commerce platforms during scaling operations to keep services operational and deliver performance excellence to users.
A sudden spike in traffic caused Lambda timeouts, API Gateway threw 5xx errors, and customers started tweeting, Why cant I check out?! Our "serverless" order processing system built on AWS Lambda and API Gateway was humming along, handling 1,000 transactions/minute. Then, disaster struck.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
With all the data collected and powered by our Davis AI-driven causation engine, Dynatrace automatically identifies slowdowns in your applications and services and points you to their root cause. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Average query response time.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Once Dynatrace sees the incoming traffic it will also show up in Dynatrace, under Transaction & Services. The post Tutorial: Guide to automated SRE-driven performance engineering appeared first on Dynatrace blog.
Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? To detect issues proactively, we need to simulate traffic and predict system behavior in advance.
By the summer of 2020, many UI engineers were ready to move to GraphQL. The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Following are some of the coolest things weve seen engineers do with Live Debugger. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering. Load generators simulate traffic. Live snapshot includes variables, process, stack trace, and tracing information.
Personalized Experience Refresh Netflix Recommendation engine continuously refreshes recommendations for every member. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
In the previous installment of this blog series , we explored how to set up Dynatrace as a build-stage orchestrator to effectively address the challenges faced by Site Reliability Engineers (SREs). This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
Growth Engineering at Netflix?—?Automated In the Growth Engineering team, we refer to this as the top of the signup funnel. For more background on the signup funnel and Growth Engineering’s role in the signup funnel, please read our initial post on the topic: Growth Engineering at Netflix? Growth Engineering at Netflix?—?Automated
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
A powerful surge of traffic is inevitable. It's midnight in the dim and cluttered office of The New York Times, currently serving as the "situation room." During every major election, the wave would crest and crash against our overwhelmed systems before receding, allowing us to assess the damage.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices. What is Docker? Networking.
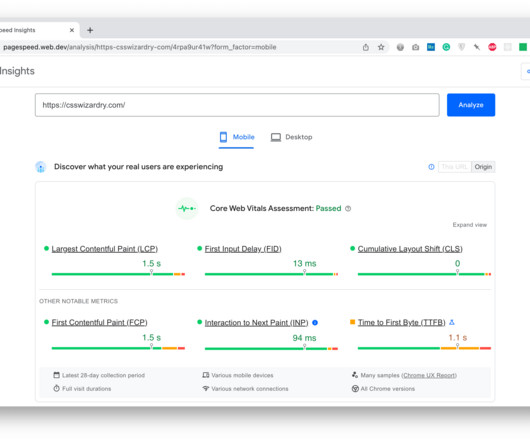
All Core Web Vitals data used to rank you is taken from actual Chrome-based traffic to your site. If you have a substantial amount of traffic from a country with, say, slow internet connections, then your performance in general will go down.
And the last sentence of the email was what made me want to share this story publicly, as it’s a testimonial to how modern software engineering and operations should make you feel. Through the RUM data, Dynatrace’s AI engine, Davis, detected seven users were impacted by the outage when they tried to access the Web Interface.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. This approach ensures high availability by isolating regions, so if one becomes degraded, others remain unaffected, allowing traffic to be shifted between regions to maintain service continuity.
Because of Dynatrace’s Real User Monitoring (RUM) capability, and insights from our AI engine, Davis, they were able to quickly prioritize and fix the issues to ensure their employees had an optimal remote work experience. Facilitating an understanding of traffic patterns and potential traffic spikes helps maintain customer experience.
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. Performance testing is mainly a subset of Performance engineering and is also referred to as ' Perf Tests.' An app is built with some expectations and is supposed to provide firm results.
Much like how an electrical circuit breaker prevents an overload by stopping the flow of electricity when excessive current is detected, the Circuit Breaker pattern in software engineering stops the flow of requests to a service when the number of failures exceeds a predefined threshold.
With the release of Dynatrace version 1.249, the Davis® AI Causation Engine provides broader support to subsequent Kubernetes issues and their impact on business continuity like: Automated Kubernetes root cause analysis. Such context is easy to understand using the Dynatrace Davis AI engine. Incidents are harder to solve.
As penance for this error, and for being short with Miguel , I must deconstruct the ways Apple has undermined browser engine diversity. Contrary to claims of Apple partisans, iOS engine restrictions are not preventing a "takeover" by Chromium — at least that's not the primary effect. And that's a choice. "WebKit
With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control. OneAgent implements network zones to create traffic routing rules and limit cross data-center traffic. Upgrade OpenTracing instrumentation with high-fidelity data provided by OneAgent.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
In this article, we will look at two types of load balancers: one used to expose Kubernetes services to the external world and another used by engineers to balance network traffic loads to those services. “Kubernetes load balancer” is a pretty broad term that refers to multiple things.
It makes sense for DevOps engineers and architects to perform canary deployments in their CI/CD workflows. In canary deployments, the new version, called canary, is tested with limited live traffic at first. They cannot skip testing a release for the sake of adhering to continuous delivery practices, can they?
Search Engine Optimization Checklist (PDF). Search Engine Optimization Checklist (PDF). Search engine optimization (SEO) is an essential part of a website’s design, and one all too often overlooked. Following best practice usually means a better website, more organic traffic, and happier visitors. Frederick O’Brien.
For engineers, instead of whodunit, the question is often “what failed and why?” An engineer can find herself digging through logs, poring over traces, and staring at dozens of dashboards. Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. the trace, logs, analysis?—?and
Google has a pretty tight grip on the tech industry: it makes by far the most popular browser with the best DevTools, and the most popular search engine, which means that web developers spend most of their time in Chrome, most of their visitors are in Chrome, and a lot of their search traffic will be coming from Google. Chrome for iOS?
Turnkey cluster overload protection with adaptive traffic management and control. The ALR mechanism also ensures maximum stability when the actual load exceeds the capacity of the cluster (though a statistically valid set of requests is still captured for analysis by the Dynatrace Davis AI causation engine ). Impact on disk space.
There are three current underlying reasons for the platform engineering meme today. What I want to cover in this blog post is how I think platforms should be structured, and why it’s always plural, there isn’t one platform or one platform team. We used this model effectively at Netflix when I was their cloud architect from 2010 through 2013.
OneAgent takes care of auto-instrumentation and creation of the Smartscape model, which enables the Davis AI causation engine. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control. OneAgent implements network zones to create traffic routing rules and limit cross-data-center traffic.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
With sniffers, network performance engineers were ultimately able to relate wire data performance to what business owners expected from the networks they financed. With tools like ApplicationVantage, network engineers discovered application inefficiencies and advised on corrective actions. Technology developments come in waves.
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. In some deployment scenarios, you might skip CloudWatch altogether.
VPC Flow Logs is a feature that gives you the capability to capture more robust IP traffic data that traverses your VPCs. Dynatrace uses your data and its sophisticated AI causation engine Davis® to automatically detect performance anomalies in applications, services, and infrastructure. What is VPC Flow Logs.
Network traffic growth is the main reason for increasing spending, largely because of the adoption of hybrid and multi-cloud architectures. What are the issues with traffic losses and connectivity drops? The AI engine AI delivers precise answers about the IT environment. These answers are instant, automatic, and continuous.
I posed these questions to a couple of friends and colleagues who are responsible for monitoring critical infrastructure and services and my friend Thomas and my colleagues from the Dynatrace Engineering Productivity shared the following stories and screenshots with me. Example #1 Order System: No change in user or buyers’ behavior.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content