This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the most visible implementations of personalization is through recommendation systems, which provide users with tailored content, products, or experiences based on their interactions and preferences. This article explores how legacy rules-based systems operate, their limitations, and how machine learning has disrupted this space.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues.
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
Scale to zero Scaling systems to match current demand prevents underutilized machines from consuming significant energy while idling. While building production systems that can scale to zero and reliably restart can be challenging, it’s often simpler in test stages and build pipelines, making this a great place to start.
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need to catch up? Check out Part 1.
As a CTO, my role extends beyond overseeing technical solutions I work closely with engineering teams to ensure performance testing strategies align with business goals. One of the recurring challenges Ive observed is how sanity testing, despite being a simple step, often determines the success or failure of performance testing efforts.
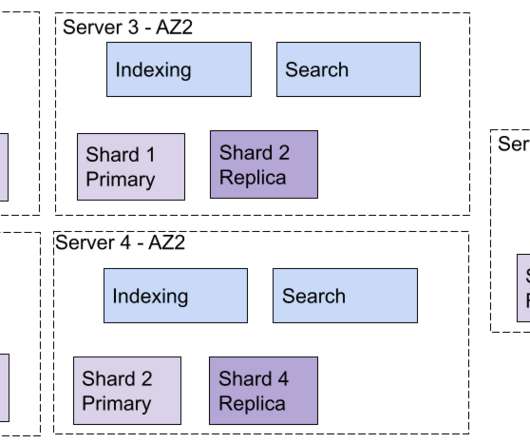
System resilience stands as the key requirement for e-commerce platforms during scaling operations to keep services operational and deliver performance excellence to users. We have developed a microservices architecture platform that encounters sporadic system failures when faced with heavy traffic events.
Monitoring system behavior is essential for ensuring long-term effectiveness. However, managing an end-to-end observability stack can feel like sailing stormy seas without a clear plan, you risk blowing off course into system complexities.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
Have you ever wondered how large-scale systems handle millions of requests seamlessly while ensuring speed, reliability, and scalability? Behind every high-performing application whether its a search engine, an e-commerce platform, or a real-time messaging service lies a well-thought-out system design.
What would a totally new search engine architecture look like? Search engines, and more generally, information retrieval systems, play a central role in almost all of today’s technical stacks. After more than 30 years of evolution since TREC, search engines continue to grow and evolve, leading to new challenges.
Our "serverless" order processing system built on AWS Lambda and API Gateway was humming along, handling 1,000 transactions/minute. The Day Our Serverless Dream Turned into a Nightmare It was 3 PM on a Tuesday. Then, disaster struck.
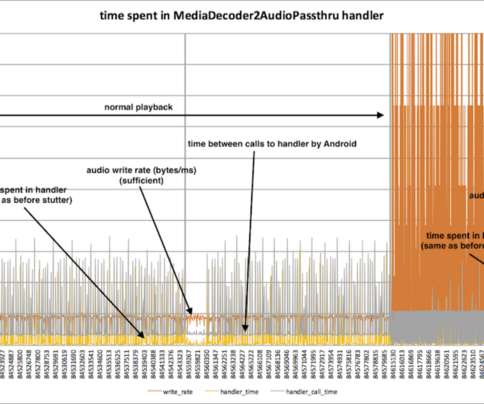
Life of a Netflix Partner Engineer?—?The The case of the extra 40 ms By: John Blair , Netflix Partner Engineering The Netflix application runs on hundreds of smart TVs, streaming sticks and pay TV set top boxes. The role of a Partner Engineer at Netflix is to help device manufacturers launch the Netflix application on their devices.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community! Learn more about how batch and streaming data pipelines are built at Netflix.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. “Our development teams relied heavily on logs to understand what was going on with our systems,” he said. billion. .
In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems. OpenTelemetry Collector 1.0
After years of working in the intricate world of software engineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention. Developers could understand and manage the entire systems intricacies.
Securing software systems ' dependability and resilience has grown to be of the utmost importance in a world driven by technology, where software systems are becoming more complex and interconnected. But chaos engineering stands out for its exceptional capacity to identify weaknesses and proactively fortify systems.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
A performance engineer is actually a professional performance testing and engineering expert with in-depth knowledge of many load-testing tools like LoadRunner, JMeter, Neoload, Gatling, K6, etc., and must have extensive experience in specialized skills.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams.
Site reliability engineering first emerged to address cloud computing’s new performance needs. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. Understanding the platform engineer role DevOps is a constantly evolving discipline.
Site Reliability Engineering (SRE) is a systematic and data-driven approach to improving the reliability, scalability, and efficiency of systems. It combines principles of software engineering, operations, and quality assurance to ensure that systems meet performance goals and business objectives.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
As Peter Sondergaard, former SVP of Gartner, insightfully stated, "Information is the oil of the 21st century, and analytics is the combustion engine." Although this approach was serviceable in a less dynamic business climate, it falls far short of the agile and instantaneous demands that define modern markets.
The evolution of enterprise software engineering has been marked by a series of "less" shifts — from client-server to web and mobile ("client-less"), data center to cloud ("data-center-less"), and app server to serverless.
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
As a result, problems introduced during system development could not be discovered before the release. While it's well-received in the community with its rich fault injection types and easy-to-use dashboard, it was difficult to use Chaos Mesh with end-to-end testing or the continuous integration (CI) process.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. These practices are commonly known as “ chaos engineering. ”
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Two big things: They bring the messiness of the real world into your system through unstructured data. When your system is both ingesting messy real-world data AND producing nondeterministic outputs, you need a different approach.
So I wanted to write a message to anyone looking to grow into engineering leadership. In some instances, these individuals stood their ground and continued forward in the face of violence, war, political and economic systems, beliefs, and stereotypes never before challenged.
Embedded systems have become an integral part of our daily lives, from smartphones and home appliances to medical devices and industrial machinery. These systems are designed to perform specific tasks efficiently, often in real-time, without the complexities of a general-purpose computer.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Our audits would detect this and alert the on-call data engineer (DE).
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
In the dynamic world of online services, the concept of site reliability engineering (SRE) has risen as a pivotal discipline, ensuring that large-scale systems maintain their performance and reliability.
By Alex Hutter , Falguni Jhaveri and Senthil Sayeebaba Over the past few years Content Engineering at Netflix has been transitioning many of its services to use a federated GraphQL platform. it began to power a significant portion of the user experience for many applications within Content Engineering.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Because of its adaptability, Prometheus has become an essential tool for observability engineering.
A transformative journey into the realm of system design with our tutorial, tailored for software engineers aspiring to architect solutions that seamlessly scale to serve millions of users.
At Dynatrace, we understand your challenges when dealing with external packageswhether you’re hustling with reverse engineering, automatically fetching open source code, or playing the guessing game. Source code is loaded only on an engineers workstation, using the engineers privileges.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content