This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. Reducing fragmentation enables DevOps and site reliability engineering (SRE) teams to work in a unified way to ensure code quality and security. Gaining speed without sacrificing quality.
Site Reliability Engineers (SREs) also face significant challenges in maintaining database reliability, ensuring performance, and preventing disruptions in highly dynamic and distributed environments. One slow query, an inefficient index, or a schema misstep can grind an application to a halt.
From developers leveraging platform engineering tools to optimize application performance, to Site Reliability Engineers (SREs) ensuring resilience, and executives gaining critical business insights, observability increases the velocity of innovation across every level of an organization.
Site reliability engineering first emerged to address cloud computing’s new performance needs. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. Understanding the platform engineer role DevOps is a constantly evolving discipline.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
Getting up to speed in a new codebase takes time. Most engineering organizations face the dilemma of ensuring the new developer gets the support they need without slowing down the rest of the team too much. Developers spend weeks or even months onboarding at a new company.
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Chaos scenario: Random pods executing worker instances are deleted.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. Grabner also introduced four ways organizations can turbocharge their performance engineering with automation. Automating root cause analysis.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. Platform engineering: Build for self-service Self-service deployment is a key attribute of platform engineering. “It makes them more productive.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
Despite best efforts, human beings can’t match the accuracy and speed of computers. Finally, manual monitoring processes take significant time, hindering DevSecOps ‘ efforts to deliver solutions at speed. ” Driving intelligent multicloud automation Speed is essential for DevSecOps teams.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Organizations can then integrate these skilled engineers at key points in the DevOps life cycle. Dynatrace news.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. One, however, splits by HttpStatusClass which allows us to later chart the number requests split by HttpStatusClass: I automated the creation of what I consider 6 important Performance Engineering SLI metrics.
Were proud to announce that Dynatrace has introduced a new capability to speed up your incident response and root cause analysis use cases with case templates in Security Investigator. The accumulated time spent on such activities before starting incident resolution can be a lot of overhead for engineers and the company.
By Alex Hutter , Falguni Jhaveri and Senthil Sayeebaba Over the past few years Content Engineering at Netflix has been transitioning many of its services to use a federated GraphQL platform. it began to power a significant portion of the user experience for many applications within Content Engineering.
the brilliant synth-pop score or the perfectly mixed soundscape of a high speed chase?—?is Our engineering team and Creative Technologies sound expert joined forces to quickly solve the issue, but a larger conversation about higher quality audio continued. Imagine this scene without the sound. experience for many more moments of joy.
Data Engineers of Netflix?—?Interview Interview with Kevin Wylie This post is part of our “Data Engineers of Netflix” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Kevin Wylie is a Data Engineer on the Content Data Science and Engineering team.
Our latest enhancements to the Dynatrace Dashboards and Notebooks apps make learning DQL optional in your day-to-day work, speeding up your troubleshooting and optimization tasks. These ready-made dashboards offer your platform engineers, who oversee Kubernetes environments, immediate and comprehensive data visibility.
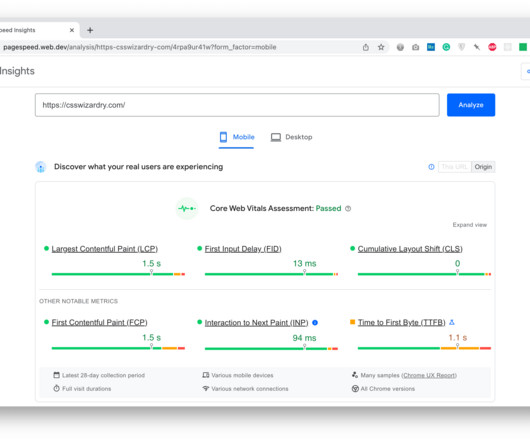
Google do strongly encourage you to focus on site speed for better performance in Search, but, if you don’t pass all relevant Core Web Vitals (and the applicable factors from the Page Experience report) they will not push you down the rankings. While Core Web Vitals can help with SEO, there’s so much more to site-speed than that.
Have you ever wondered how large-scale systems handle millions of requests seamlessly while ensuring speed, reliability, and scalability? Behind every high-performing application whether its a search engine, an e-commerce platform, or a real-time messaging service lies a well-thought-out system design.
While increasing both the precision and the recall of our secrets detection engine, we felt the need to keep a close eye on speed. In a gearbox, if you want to increase torque, you need to decrease speed. So it wasn’t a surprise to find that our engine had the same problem: more power, less speed.
Whether you're a developer, DevOps engineer, or IT manager, this will help you make a smart choice for your monitoring needs. You decide what data to collect such as speed, routes, or delivery times and you can use this data with any tracking system. But how do you know which one is best for you? What Are OpenTelemetry and Dynatrace?
Take one look at LinkedIn right now, and you’ll notice some of the most in-demand jobs include application developers and software engineers. After a deeper dive, you’ll find many companies across multiple industries are looking for site reliability engineers or SREs.
This holds true for the critical field of data engineering as well. Automated testing methodologies are now imperative to deliver speed, accuracy, and integrity. This comprehensive guide takes an in-depth look at automated testing in the data engineering domain.
An open-source distributed SQL query engine, Trino is widely used for data analytics on distributed data storage. Optimizing Trino to make it faster can help organizations achieve quicker insights and better user experiences, as well as cut costs and improve infrastructure efficiency and scalability. But how do we do that?
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. But with that speed and agility comes new complications and complexity, all while maintaining performance and reliability with less than 1% down-time per year. SRE as an application of DevOps. SRE vs DevOps?
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. Part 1: Creating the Source of Truth for Impressions By: TulikaBhatt Imagine scrolling through Netflix, where each movie poster or promotional banner competes for your attention.
Performances testing helps establish the scalability, stability, and speed of the software application. Performance testing is mainly a subset of Performance engineering and is also referred to as ' Perf Tests.' Confirming scalability, dependability, stability, and speed of the app is crucial.
For example, it can help DevOps and platform engineering teams write code snippets by drawing on information from software libraries. Engineering teams will, therefore, always need to check the code they get from GPTs to ensure it doesn’t risk software reliability, performance, compliance, or security.
Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. Check back here throughout the event for the latest news, insights, and announcements.
You can use powerful dashboard capabilities to visualize whatever metrics are most relevant to your teams and let the Davis AI causation engine automatically identify the root cause of problems. The post Smart and intuitive time-traveling for intelligent observability with our new warp-speed, lingual input appeared first on Dynatrace blog.
Dynatrace enables our customers to tame cloud complexity, speed innovation, and deliver better business outcomes through BizDevSecOps collaboration. Whether it’s the speed and quality of innovation for IT, automation and efficiency for DevOps, or enhancement and consistency of user experiences, Dynatrace makes it easy.
At Perform 2021, Dynatrace product manager Michael Winkler sat down with Atlassian’s DevOps evangelist, Ian Buchanan, to talk about how you can achieve speed, stability, and scale in your DevOps toolchain as you optimize your practices on the path to self-service. The status quo of the DevOps toolchain.
Annie leads the Chrome Speed Metrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty Speed Metrics team at Google. Nice job, everyone!
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. – blog.
As they increase the speed of product innovation and software development, organizations have an increasing number of applications, microservices and cloud infrastructure to manage. Further, many organizations—more than 90%—have turned to cloud computing to navigate the highwire act of balancing speed and quality.
In today’s rapidly evolving business and technology landscape, organizations often prioritize the speed of development over security. Modern solutions like Snyk and Dynatrace offer a way to achieve the speed of modern innovation without sacrificing security.
The scale and speed of the program triggered challenges for these banks that they had never before imagined. Speed up loan processing to deliver critically needed relief to small businesses? Full speed ahead. Let your Dynatrace Sales Engineer know you want to get started with Digital Business Analytics.
In such contexts, platform engineering offers a compelling solution to enable business competitiveness in a manner that significantly enhances the developer experience. Treating an Internal Developer Platform (IDP) as a product is an emerging paradigm within platform engineering communities.
To speed up release frequency, they’re investing in delivery-pipeline automation. The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs. Read more about the basics of Site Reliability Engineering below.).
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. As the number of apps and services deployed increases, teams face increased pressure to speed up native mobile app innovation and resolve app issues quicker. Next-gen Infrastructure Monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content