This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scale to zero Scaling systems to match current demand prevents underutilized machines from consuming significant energy while idling. While building production systems that can scale to zero and reliably restart can be challenging, it’s often simpler in test stages and build pipelines, making this a great place to start.
The evolution of enterprise softwareengineering has been marked by a series of "less" shifts — from client-server to web and mobile ("client-less"), data center to cloud ("data-center-less"), and app server to serverless.
After years of working in the intricate world of softwareengineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention. Developers could understand and manage the entire systems intricacies.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community! Learn more about how batch and streaming data pipelines are built at Netflix.
Whilst our traditional Dynatrace website predominantly showcases Dynatrace content and product information for visitors, the idea behind the creation of our new Engineering website – engineering.dynatrace.com – was to set up a space to feature the results of our research and innovation efforts and aims to be a site made by engineers for engineers.
Site Reliability Engineering (SRE) is a systematic and data-driven approach to improving the reliability, scalability, and efficiency of systems. It combines principles of softwareengineering, operations, and quality assurance to ensure that systems meet performance goals and business objectives.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive softwaresystems that emerged to cope with requirements for near real-time processing of massive amounts of data. Recovery time of the latency p90.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable softwaresystems. Dynatrace news. SRE focuses on automation.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable softwaresystems. Dynatrace news. SRE bridges the gap between Dev and Ops teams. SRE focuses on automation.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Most backend engineering teams follow a process very similar to what is shown below. If so, we invite you to begin the interview process.
In the dynamic world of online services, the concept of site reliability engineering (SRE) has risen as a pivotal discipline, ensuring that large-scale systems maintain their performance and reliability.
Following are some of the coolest things weve seen engineers do with Live Debugger. You can verify any system settings that might impact your tests and see them in action. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of softwareengineering.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
A transformative journey into the realm of system design with our tutorial, tailored for softwareengineers aspiring to architect solutions that seamlessly scale to serve millions of users.
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior SoftwareEngineer at Netflix.
In the world of softwareengineering, where complex systems are the norm, ensuring reliability and resilience is paramount. However, traditional testing methods often fall short of uncovering hidden vulnerabilities and edge cases that could lead to system failures. What Is Chaos Engineering?
The system is inconsistent, slow, hallucinatingand that amazing demo starts collecting digital dust. Traditional versus GenAI software: Excitement builds steadilyor crashes after the demo. Two big things: They bring the messiness of the real world into your system through unstructured data. Leadership gets excited. The way out?
TL;DR: Enterprise AI teams are discovering that purely agentic approaches (dynamically chaining LLM calls) dont deliver the reliability needed for production systems. The prompt-and-pray modelwhere business logic lives entirely in promptscreates systems that are unreliable, inefficient, and impossible to maintain at scale.
Our industry is in the early days of an explosion in software using LLMs, as well as (separately, but relatedly) a revolution in how engineers write and run code, thanks to generative AI.
In early September I had a very enjoyable technical chat with Steve Klabnik of Rust fame and interviewer Kevin Ball of SoftwareEngineering Daily, and the podcast is now available. Rust, while newer, is gaining traction in roles that demand safety and concurrency, particularly in systems programming.
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
We are well aware of what is meant by system scalability. System scalability is about maintaining the SLA of the system as the user base continues to grow and as the user activity continues to rise. Softwareengineering team scalability is equally important. SoftwareEngineering Team Scalability.
If you need to dynamically trace Linux process system calls, you might first consider strace. strace is simple to use and works well for issues such as "Why can't the software run on this machine?" So are there any tools that excel at tracing system calls in a production environment? The answer is YES.
Softwareengineering for machine learning: a case study Amershi et al., More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and softwareengineering is changing at Microsoft with the rise of AI and ML. ICSE’19.
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
In the world of distributed systems, the likelihood of components failing or becoming unresponsive is higher compared to monolithic systems. Therefore, resilience — the ability of a system to handle and recover from failures — becomes critically important in distributed environments.
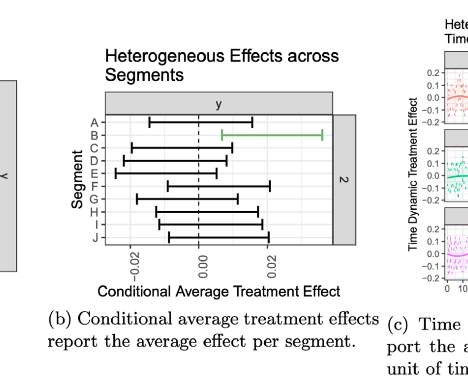
These methods can provide rich information for decision making, such as in experimentation platforms (“XP”) or in algorithmic policy engines. We want to amplify the effectiveness of our researchers by providing them software that can estimate causal effects models efficiently, and can integrate causal effects into large engineeringsystems.
Softwareengineers didn’t need to understand the database, and even if they owned it, it was just a single component of the system. Guaranteeing software quality was much easier because the deployment happened rarely, and things could be captured on time via automated tests.
Software development is not an established discipline where there is a clear technique used to solve any given problem. In fact, there are near infinite ways to solve every softwareengineering challenging. However, as softwaresystems age, the time it takes to add new features grows exponentially?—?and
There are a few qualities that differentiate average from high performing softwareengineering organisations. In my experience, the culture is better and the results are better in orgs where engineers and architects obsess over the design of code and architecture. Regularly spending time with domain experts is important.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a softwareengineer takes nine hours to remediate a problem within a production application. Context-rich tickets can be created in systems like Jira or ServiceNow for traceability and compliance.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying softwareengineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
Growth Engineering at Netflix?—?Automated In the Growth Engineering team, we refer to this as the top of the signup funnel. For more background on the signup funnel and Growth Engineering’s role in the signup funnel, please read our initial post on the topic: Growth Engineering at Netflix? Growth Engineering at Netflix?—?Automated
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. The streaming data store makes the system extensible to support other use-cases (e.g. System Components. The system will comprise of several micro-services each performing a separate task.
The 737Max and Why SoftwareEngineers Might Want to Pay Attention As someone with a bit of a reputation for talking about aviation and software development and operations , I’ve been asked about the 737Max repeatedly over the past week. the part under control of the automatic system?—?can
The Client and UI Engineering team built a certification test with these streams to analyze both the device logs as well as the pictures rendered on the screen. The Performance Engineering team specializes in optimizing resource utilization at Netflix. Some titles (e.g., Challenge 4: How do we continuously monitor AV1 streaming?
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. In particular, it’s our job to design and build the systems and protocols that enable customers from all over the world to sign up for Netflix with the plan features and incentives that best suit their needs.
A good SRE engineer will tell you your service is never down. A great SRE engineer will tell you that’s not what you should be measuring. In fact, they’ll tell you their job is customer service.
While load testing may sound like an esoteric domain exclusive to softwareengineers or network administrators, it is, in fact, a silent superhero in our increasingly digital world. Acting behind the scenes, load testing ensures the apps and websites we use daily are capable of withstanding the demands of their users without stumbling.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. And the last sentence of the email was what made me want to share this story publicly, as it’s a testimonial to how modern softwareengineering and operations should make you feel. Let me start with the end-user impact.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content