This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After years of working in the intricate world of softwareengineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. In response to this shift, platform engineering is growing in popularity. The result is a cloud-native approach to software delivery.
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges softwareengineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
Site Reliability Engineering (SRE) is a systematic and data-driven approach to improving the reliability, scalability, and efficiency of systems. It combines principles of softwareengineering, operations, and quality assurance to ensure that systems meet performance goals and business objectives.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalablesoftware systems. Dynatrace news. SRE focuses on automation.
In the dynamic world of online services, the concept of site reliability engineering (SRE) has risen as a pivotal discipline, ensuring that large-scale systems maintain their performance and reliability.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Most backend engineering teams follow a process very similar to what is shown below. If so, we invite you to begin the interview process.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalablesoftware systems. Organizations can then integrate these skilled engineers at key points in the DevOps life cycle.
We are well aware of what is meant by system scalability. System scalability is about maintaining the SLA of the system as the user base continues to grow and as the user activity continues to rise. However, to build highly successful products, this is not the only type of scalability that we should worry about. Introduction.
This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. They must also provide enough information for partner engineers to identify the problem with the underlying service in cases of system-level issues.
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. For more background on Growth Engineering and the signup funnel, please have a look at our previous blog post that covers the basics. We need to be constantly adapting and innovating as a result of this change.
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?.
These methods can provide rich information for decision making, such as in experimentation platforms (“XP”) or in algorithmic policy engines. We want to amplify the effectiveness of our researchers by providing them software that can estimate causal effects models efficiently, and can integrate causal effects into large engineering systems.
SRE is the transformation of traditional operations practices by using softwareengineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Investing in automation and tooling to avoid toil. SRE vs DevOps?
antirez : "After 20 years as a softwareengineer, I've started commenting heavily. Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading). So many more quotes.
These workflows are then implemented as traditional software, which can be tested, versioned, and maintained. This approach is well understood in softwareengineering and contrasts sharply with building agents that rely on runtime decisionsan inherently less reliable and harder-to-maintain model.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. This is a guest post by Ankit Sirmorya.
Data Engineers of Netflix?—?Interview Interview with Dhevi Rajendran Dhevi Rajendran This post is part of our “Data Engineers of Netflix” interview series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. The culture was also something that piqued my interest.
billion : made by Pokeman GO; $13 billion : Netflix's new content budget; Quotable Quotes: @davidbrunelle : The best developers and engineering leaders I've personally worked with do *not* have a notable presence on GitHub or public bodies of speaking or writing work. Margaret Hamilton started the field of softwareengineering.
A good SRE engineer will tell you your service is never down. A great SRE engineer will tell you that’s not what you should be measuring. In fact, they’ll tell you their job is customer service.
A transformative journey into the realm of system design with our tutorial, tailored for softwareengineers aspiring to architect solutions that seamlessly scale to serve millions of users.
By Astha Singhal , Lakshmi Sudheer , Julia Knecht The Application Security teams at Netflix are responsible for securing the software footprint that we create to run the Netflix product, the Netflix studio, and the business. Our customers are product and engineering teams at Netflix that build these software services and platforms.
One key advantage of this integration is a single point of access to monitoring, logging, and other information needed to keep software development operations running efficiently. Orchestration leverages DevOps tools that allow for rapid updates and releases, version control, and other best practices for softwareengineering.
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. “It’s quite a big scale,” said an engineer at the financial services group.
Now, imagine yourself in the role of a softwareengineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. In this model, we scan system logs and metadata generated by various compute engines to collect corresponding lineage data.
In our quest for greater scalability, resilience, and flexibility within the digital infrastructure of our organization, there has been a strategic pivot away from traditional monolithic application architectures towards embracing modern softwareengineering practices such as microservices architecture coupled with cloud-native applications.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Over the years, this platform took on support for both elastic online services and fully featured batch workloads supporting use cases across Netflix engineering.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these best practices to innovate at speed without sacrificing quality, reliability, or security. SRE applies softwareengineering principles to operations and infrastructure processes. – blog.
Application security is a softwareengineering term that refers to several different types of security practices designed to ensure applications do not contain vulnerabilities that could allow illicit access to sensitive data, unauthorized code modification, or resource hijacking. Dynatrace news.
To handle this challenge, enterprises need to automate and streamline the onboarding and lifecycle of tool configurations in the software development processes, including aspects of observability, security, alerting, and remediation. Development teams must set up tailored configurations for each tool and component they’re responsible for.
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Motivation Scalability and usability are essential to enable large-scale workflows and support a wide range of use cases.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like softwareengineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. The new category is often called MLOps. This approach is not novel.
Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. To learn more about platform engineering, explore the following resources.
To gain insight into these problems, softwareengineers typically deploy application instrumentation frameworks that provide insight into applications and code. While this provides greater scalability than on-site instrumentation, it also introduces complexity. AWS monitoring best practices. Automate monitoring tasks.
Supporting developers through those checklists for edge cases, and then validating that each team’s choices resulted in an architecture with all the desired security properties, was similarly not scalable for our security engineers. Netflix engineers talk a lot about the concept of a “ Paved Road ”.
The Dynatrace AI engine, Davis,?automatically The new Dynatrace AWS Lambda extension further improves enterprise-grade scalability with low memory overhead, effortless manageability, continuous automation, and granular access-permission controls that support the structures of cloud-native applications teams within large organizations.
They are lightweight and scalable, and do not require a significant financial investment. Team Size Small Teams: For smaller teams or solo developers, free and open-source tools such as pgAdmin or OmniDB offer more than enough functionality for routine database management.
mainly because of mundane reasons related to softwareengineering. They know that feature engineering is critical for many models, so they want to stay in control of model inputs and feature engineering logic. The user can benefit from infinitely scalable compute clusters by adding a single line in their code: @batch.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. For heads of IT/Engineering responsible for building an analytics infrastructure , Etleap is an ETL solution for creating perfect data pipelines from day one. Who's Hiring?
T riplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn how engineering teams are using products like StackHawk and Snyk to add security bug testing to their CI pipelines. Created by former senior-level AWS engineers of 15 years.
Triplebyte lets exceptional softwareengineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Watch a demo and learn how Etleap can save you on engineering hours and decrease your time to value for your Amazon Redshift analytics projects. Who's Hiring? Apply here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















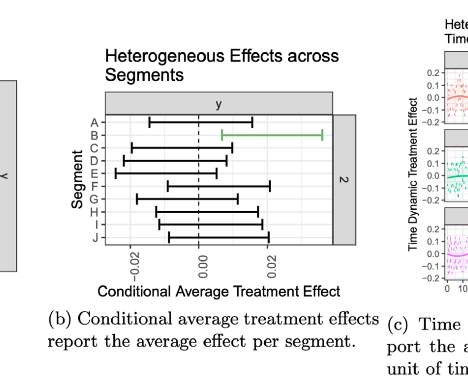




















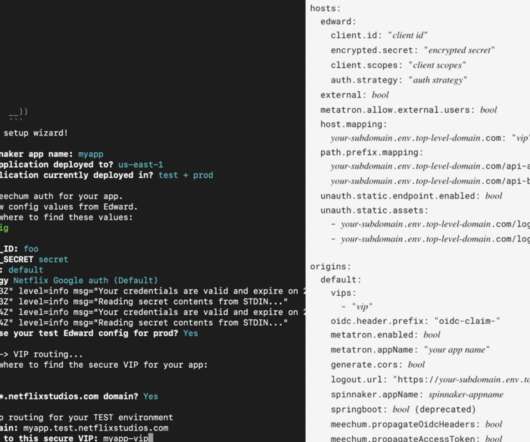












Let's personalize your content