This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After years of working in the intricate world of software engineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention.
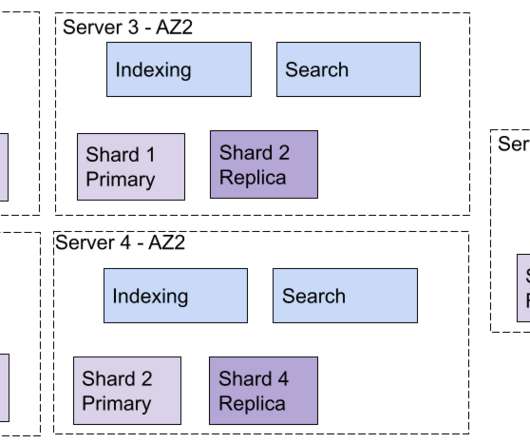
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
One of the more notable aspects of ChatGPT is its engine, which not only powers the web-based chatbot but can also be integrated into your Java applications.
Modern distributed systems, like microservices and cloud-native architectures, are built to be scalable and reliable. Chaos engineering is a useful way to test and improve system resilience by intentionally creating controlled failures. However, their complexity can lead to unexpected failures.
Platform engineering is the creation and management of foundational infrastructure and automated processes, incorporating principles like abstraction, automation, and self-service, to empower development teams, optimize resource utilization, ensure security, and foster collaboration for efficient and scalable software development.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. In response to this shift, platform engineering is growing in popularity. Why is platform engineering important?
Non-compliance and misconfigurations thrive in scalable clusters without continuous reporting. Compliance auditing is a challenge. Kubernetes’s ephemeral nature and limited logging make compliance auditing a nightmare. There is a high likelihood of uncontrolled attack surfaces.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. Different types of search queries are supported using the Elasticsearch as a backend search engine. As an example, the label can be ‘shower curtain’.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. This created problems with both visibility and scalability. Platform engineering looks to bring in a unified toolset.” billion. .
Reverse engineering an ancient analog computer is a detective story worth reading. Here's a review that is not on the block chain: Number Stuff: Don't miss all that the Internet has to say on Scalability, click below and become eventually. Hey, HighScalability is here again! Do you love this Stuff?
Site Reliability Engineering (SRE) is a systematic and data-driven approach to improving the reliability, scalability, and efficiency of systems. It combines principles of software engineering, operations, and quality assurance to ensure that systems meet performance goals and business objectives.
The scalability, agility, and continuous delivery offered by microservices architecture make it a popular option for businesses today. Various factors, such as network communication, inter-service dependencies, external dependencies, and scalability issues, can contribute to outages.
What would a totally new search engine architecture look like? Search engines, and more generally, information retrieval systems, play a central role in almost all of today’s technical stacks. After more than 30 years of evolution since TREC, search engines continue to grow and evolve, leading to new challenges.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. These practices are commonly known as “ chaos engineering. ”
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
This thoughtful approach doesnt just address immediate hurdles; it builds the resilience and scalability needed for the future. Challenge: Dont understand the cascading effects of their setup on these perceived black box personalization systems - Personalization System Engineers Role: Develop and operate the personalization systems.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
1958: An engineer wiring an early IBM computer 2021: An engineer wiring an early IBM quantum computer. Never fear, HighScalability is here! enclanglement. My Stuff: I'm proud to announce a completely updated and expanded version of Explain the Cloud Like I'm 10 !
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Chaos scenario: Random pods executing worker instances are deleted.
This channel is the perfect blend of programming, hardware, engineering, and crazy. Here's a 100% bipartisan review: Number Stuff: Don't miss all that the Internet has to say on Scalability, click below and become eventually. Hey, HighScalability is back! After watching you’ll feel inadequate, but in an entertained sort of way.
Only Dynatrace provides this level of depth and breadth across Kubernetes clusters , from infrastructure level information needed by operations teams, all the way down to code-level inefficiencies that are best handled by application engineers. A look to the future. Migration instructions are available in Dynatrace Documentation.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Most backend engineering teams follow a process very similar to what is shown below. If so, we invite you to begin the interview process.
In the dynamic world of online services, the concept of site reliability engineering (SRE) has risen as a pivotal discipline, ensuring that large-scale systems maintain their performance and reliability.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Organizations can then integrate these skilled engineers at key points in the DevOps life cycle.
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges software engineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
As a developer, engineer, or architect, finding the right storage solution that seamlessly integrates with your infrastructure while providing the necessary scalability, security, and performance can be a daunting task. Scalability and Flexibility One of the key strengths of StoneFly's offerings is its exceptional scalability.
Key to this recognition as a uniquely global company is an agile and scalable approach to creativity. The company also introduced its proprietary Davis® AI engine. Innovating with passion—at scale At Dynatrace, innovation is one of our core values.
In the dynamic realm of modern software development and operations, terms such as Platform Engineering, DevOps, and Site Reliability Engineering (SRE) are frequently used, sometimes interchangeably, often causing confusion among professionals entering or navigating these domains.
Organizations are increasingly moving to multicloud environments and adopting microservices to increase the efficiency, reliability, and scalability of their applications and services. Check out the full Perform 2023 session: “ Reduce engineering toil with automation.”
Additionally, the Dynatrace Automation Engine will leverage SLO alerts to create event-triggered workflows to inform relevant stakeholders, provide reports, or automatically kick off remediation activities. At the same time, dedicated configuration-as-code support in Monaco and Terraform will provide a scalable, automated solution.
that offers security, scalability, and simplicity of use. Python code also carries limited scalability and the burden of governing its security in production environments and lifecycle management. Scalability and failover Extensions 2.0 and focusing on a much-improved version 2.0 Extensions 2.0 Extensions 2.0 Extensions 2.0
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? The complexity of these operational demands underscored the urgent need for a scalable solution.
This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. They must also provide enough information for partner engineers to identify the problem with the underlying service in cases of system-level issues.
Have you ever wondered how large-scale systems handle millions of requests seamlessly while ensuring speed, reliability, and scalability? Behind every high-performing application whether its a search engine, an e-commerce platform, or a real-time messaging service lies a well-thought-out system design.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Because of its adaptability, Prometheus has become an essential tool for observability engineering. Jolly good!
We are well aware of what is meant by system scalability. System scalability is about maintaining the SLA of the system as the user base continues to grow and as the user activity continues to rise. However, to build highly successful products, this is not the only type of scalability that we should worry about. Introduction.
In this article, I’m going to demonstrate how you can migrate a comprehensive web application from MySQL to YugabyteDB using the open-source data migration engine YugabyteDB Voyager. This helps improve availability, scalability, and performance.
If you are a site reliability engineer (SRE) for a large Kubernetes-powered application, optimizing resources and performance is a daunting job. It’s simply not sustainable or practical, and certainly not scalable. Moreover, there will always be unexpected peaks to respond to.
Data engineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for data engineering projects and provide detailed implementation steps to get started.
A good SRE engineer will tell you your service is never down. A great SRE engineer will tell you that’s not what you should be measuring. In fact, they’ll tell you their job is customer service.
Maintaining reliability and scalability requires a good grasp of resource management; predicting future demands helps prevent resource shortages, avoid over-provisioning, and maintain cost efficiency. The forecast is created instantly, even for large data sets, and updates dynamically whenever filter settings are changed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content