This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
Simplify data ingestion and up-level storage for better, faster querying : With Dynatrace, petabytes of data are always hot for real-time insights, at a cold cost. Business-focused, unified platform approach : A unified platform approach enables platform engineering and self-service portals, simplifying operations and reducing costs.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues.
With all the data collected and powered by our Davis AI-driven causation engine, Dynatrace automatically identifies slowdowns in your applications and services and points you to their root cause. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Network services visibility (DNS, NTP, ActiveDirectory).
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
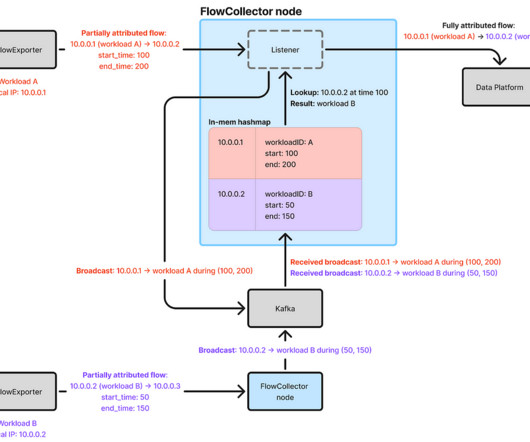
By Cheng Xie , Bryan Shultz , and Christine Xu In a previous blog post , we described how Netflix uses eBPF to capture TCP flow logs at scale for enhanced network insights. Because the in-memory state can be quickly rebuilt when a FlowCollector node starts up, no persistent storage is required. With 30 c7i.2xlarge
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
As a developer, engineer, or architect, finding the right storage solution that seamlessly integrates with your infrastructure while providing the necessary scalability, security, and performance can be a daunting task. Whether you're a small startup or a large enterprise, StoneFly's storage solutions can grow with your business.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. MezzFS has a number of features, including: Stream objects ?— ?
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. This is a guest post by Ankit Sirmorya.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Because of its adaptability, Prometheus has become an essential tool for observability engineering.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum interconnect is the networking layer of the architecture, and manages communication between the Greenplum segments and master host network infrastructure. Polymorphic Data Storage. Major Use Cases.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
Growth Engineering at Netflix?—?Automated In the Growth Engineering team, we refer to this as the top of the signup funnel. For more background on the signup funnel and Growth Engineering’s role in the signup funnel, please read our initial post on the topic: Growth Engineering at Netflix? Accelerating Innovation.
Additionally, the tight coupling with multiple native database APIs — APIs that continually evolve and sometimes introduce backward-incompatible changes — resulted in org-wide engineering efforts to maintain and optimize our microservice’s data access. Each namespace may use different backends: Cassandra, EVCache, or combinations of multiple.
Data engineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for data engineering projects and provide detailed implementation steps to get started.
a Netflix member via Twitter This is an example of a question our on-call engineers need to answer to help resolve a member issue?—?which We needed to increase engineering productivity via distributed request tracing. That is the first question our engineering teams asked us when integrating the tracer library.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
This complexity has surfaced seven top Kubernetes challenges that strain engineering teams and ultimately slow the pace of innovation. The top Kubernetes challenges and potential solutions Despite its benefits, Kubernetes has some potential pitfalls that engineering leaders should consider when managing the complexity it introduces.
But there’s more than just a need for minimizing resource (CPU, memory, storage) and network (bandwidth) consumption for observability at the edge. Moreover, edge environments can be highly dynamic, with devices frequently joining and leaving the network. Remote management and automated alerting are, therefore, crucial.
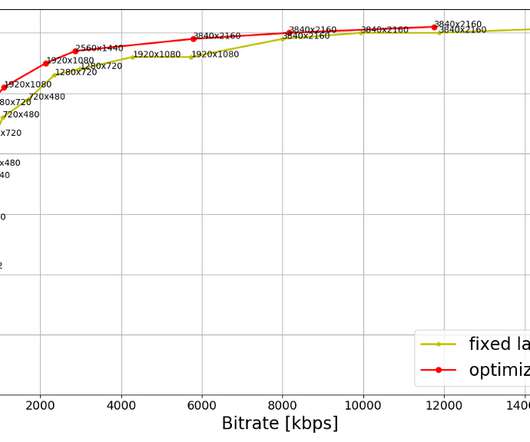
As the number of 4K titles in our catalog continues to grow and more devices support the premium features, we expect these video streams to have an increasing impact on our members and the network. The fixed-bitrate ladder starts at 560 kbps which may be too high for some cellular networks. shot-optimized encoding and 4K VMAF model ?—?and
But managing the deployment, modification, networking, and scaling of multiple containers can quickly outstrip the capabilities of development and operations teams. This orchestration includes provisioning, scheduling, networking, ensuring availability, and monitoring container lifecycles. How does container orchestration work?
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and network traffic. Dehydrated data has been compressed or otherwise altered for storage in a data warehouse.
The latest batch of services cover databases, networks, machine learning and computing. Each service comes with zero-configuration, automatic instance detection, continuous data capture in context, and what’s most important – thanks to our AI engine Davis – is each service provides answers, not just data. AWS Storage Gateway.
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. The newly introduced VPC Flow Logs for Transit Gateway service brings a new network dimension to application monitoring.
The number and variety of applications, network devices, serverless functions, and ephemeral containers grows continuously. Teams have introduced workarounds to reduce storage costs. Stop worrying about log data ingest and storage — start creating value instead. And this expansion shows no sign of slowing down.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale : Using Anna v0 as an in-memory storageengine, we set out to address the cloud storage problems described above. Each storage server collects statistics about the requests it serves, the data it stores, etc.
From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step. It is worth pointing out that cloud processing is always subject to variable network conditions.
Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. Redundancy in power, network, cooling systems, and possibly everything else relevant. this is addressed through monitoring and redundancy. Again the approach here is the same.
Managing Cold Storage with Amazon Glacier. With the introduction of Amazon Glacier , IT organizations now have a solution that removes the headaches of digital archiving and provides extremely low cost storage. All Things Distributed. Werner Vogels weblog on building scalable and robust distributed systems. Expanding the Cloud â??
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. This feature store is equipped with a data replication system that enables copying data to different storage solutions depending on the required access patterns. Figure 2 - a series of frame match cuts from Wednesday.
The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center network traffic. – A Dynatrace customer, Head of Performance Engineering. Regular Dynatrace Managed deployments can work seamlessly when a maximum of two nodes are down at a time and the network has low latency.
All the monitoring data that’s captured by Dynatrace is analyzed by the Dynatrace AI engine, Davis, which has a full picture of your application and able to find the root cause of application problems, all the way down to the code-level. .
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Additionally, they manage applications and services deployed on the network and provide secure access to authorized users. ” The post What is ITOps?
Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion. Quorum queues can still function during a network partition as long as most nodes communicate.
Getting insights into the health and disruptions of your networking or infrastructure is fundamental to enterprise observability. For example, a supported syslog component must support the masking of sensitive data at capture to avoid transmitting personally identifiable information or other confidential data over the network.
Kubernetes also gives developers freedom of choice when selecting operating systems, container runtimes, storageengines, and other key elements for their Kubernetes environments. Without having to worry about underlying infrastructure concerns, such as storage, security, and lifecycle management, developers can focus on writing code.
In spite of reaching higher qualities than the fixed ladder, the HDR-DO ladder, on average, occupies only 58% of the storage space compared to fixed-bitrate ladder. Join us and be a part of the amazing team that brought you this tech-blog; open positions: Software Engineer, Cloud Gaming Software Engineer, Live Streaming References [1] L.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. In this blog, we will discuss both data and network-level compression offered in MongoDB.
To address potentially high numbers of requests during online shopping events like Singles Day or Black Friday, it’s crucial that this online shop have a memory storage strategy that allows for speed, scaling, and resilience of all microservices, especially the shopping cart service.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. The Kubernetes experience. Conclusion.
The process involves monitoring various components of the software delivery pipeline, including applications, infrastructure, networks, and databases. Infrastructure monitoring Infrastructure monitoring reviews servers, storage, network connections, virtual machines, and other data center elements that support applications.
They were focused on getting Netflix onto TV sets, and thought the screen was too small, the time people would spend watching was too short, and there wasnt enough mobile network bandwidth. One of the Java engineers on my teamJian Wujoined me to help figure out the API. In September 2008 Netflix ran an internal hack day event.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content