This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Average query response time.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. there is a dedicated collector.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Option 1: Log Processing Log processing offers a straightforward solution for monitoring and analyzing title launches.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? Real-time monitoring of user application and service interactions.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. Network traffic growth is the main reason for increasing spending, largely because of the adoption of hybrid and multi-cloud architectures.
Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance. Our streaming teams need a monitoring system that enables them to quickly diagnose and remediate problems; seconds count!
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Now our environment where we’ll be deploying our application under test is now automatically monitored by Dynatrace! This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Digital experience monitoring (DEM) allows an organization to optimize customer experiences by taking into account the context surrounding digital experience metrics. What is digital experience monitoring? Primary digital experience monitoring tools.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. EC2 is ideally suited for large workloads with constant traffic.
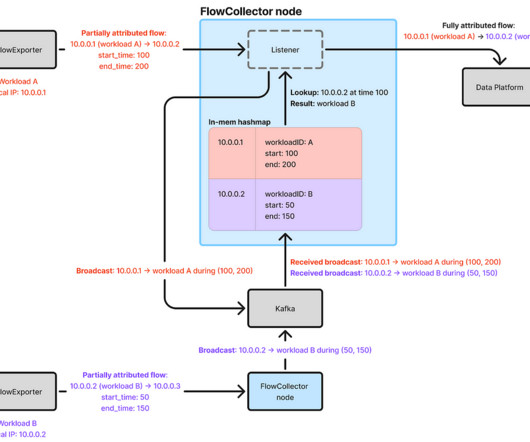
It uses eBPF and TCP tracepoints to monitor TCP socket state changes. To optimize flow reporting and minimize cross-regional traffic, a FlowCollector cluster runs in each major region, and FlowExporter agents send flows to their corresponding regional FlowCollector.
Following are some of the coolest things weve seen engineers do with Live Debugger. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering. Load generators simulate traffic. Maybe you want to monitor performance under different system loads.
By the summer of 2020, many UI engineers were ready to move to GraphQL. The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices. Built-in monitoring.
In the previous installment of this blog series , we explored how to set up Dynatrace as a build-stage orchestrator to effectively address the challenges faced by Site Reliability Engineers (SREs). This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. There are several ways Dynatrace monitors and alerts on the impact of service disruption. Ready to learn more? Fact #2: No significant impact on Dynatrace Users.
Monitor your cloud OpenPipeline ™ is the Dynatrace platform data-handling solution designed to seamlessly ingest and process data from any source, regardless of scale or format. Kubernetes log monitoring with Fluent Bit In an effort to further democratize data, Dynatrace provides a curated and supported OpenTelemetry collector.
Personalized Experience Refresh Netflix Recommendation engine continuously refreshes recommendations for every member. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly.
Because of Dynatrace’s Real User Monitoring (RUM) capability, and insights from our AI engine, Davis, they were able to quickly prioritize and fix the issues to ensure their employees had an optimal remote work experience. Facilitating an understanding of traffic patterns and potential traffic spikes helps maintain customer experience.
Since “hope is not a strategy” when it comes to running software services, you need to eliminate bad monitoring and instead establish an observability strategy for your services, as well as for involved third-party libraries and frameworks, that provides actionable answers instead of just more data.
For two decades, Dynatrace NAM—Network Application Monitoring, formerly known as DC RUM—has been successfully monitoring the user experience of our customers’ enterprise applications. With tools like ApplicationVantage, network engineers discovered application inefficiencies and advised on corrective actions.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
Turnkey cluster overload protection with adaptive traffic management and control. This can occur especially when: There are temporary load spikes due to peak loads from monitored applications that are being load tested, or from cluster nodes that are taking over load from others that are under maintenance or being upgraded.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Such monitoring data is critical to providing satisfying digital experiences and services to customers. OneAgent takes care of auto-instrumentation and creation of the Smartscape model, which enables the Davis AI causation engine. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control.
With the release of Dynatrace version 1.249, the Davis® AI Causation Engine provides broader support to subsequent Kubernetes issues and their impact on business continuity like: Automated Kubernetes root cause analysis. Such context is easy to understand using the Dynatrace Davis AI engine. Incidents are harder to solve.
Effectively assessing and mitigating these external risks requires robust vendor due diligence and continuous monitoring of their cybersecurity posture. This can require process re-engineering to fill gaps and ensuring clear communication and collaboration across security, operations, and development teams.
I posed these questions to a couple of friends and colleagues who are responsible for monitoring critical infrastructure and services and my friend Thomas and my colleagues from the Dynatrace Engineering Productivity shared the following stories and screenshots with me. Example #1 Order System: No change in user or buyers’ behavior.
Near-zero RPO and RTO—monitoring continues seamlessly and without data loss in failover scenarios. Minimized cross-data center network traffic. – A Dynatrace customer, Head of Performance Engineering. Achieve high SLOs with seamless monitoring when entire data centers experience outages.
Our enhanced host monitoring dashboard that highlights disk usage includes AI forecasting for CPU usage. In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic. Looking for something?
The monitoring challenges of on-premises environments. As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. Our new extension framework now makes it a no-brainer to start monitoring your SNMP protocols.
Implementing a robust monitoring and observability strategy has become the foundation of an organization’s ability to improve business resiliency and stay in control of their critical IT environments. Using Dynatrace synthetic monitoring capabilities, organizations can simulate user behavior and identify performance bottlenecks under load.
OneAgent technology simplifies deployment across large enterprises and relieves engineers of the burden of instrumenting their applications by hand. Dynatrace Operator for OneAgent, API monitoring, routing, and more. No need to repeat API endpoints or tokens across OneAgents and API monitors. Dynatrace news.
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. In some deployment scenarios, you might skip CloudWatch altogether.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
Unlike other solutions on the market that force you to manually deploy and configure monitoring, Dynatrace gives you out-of-the-box service-level insights with full end-to-end traces into your microservices. This is especially important as these are the gatekeepers for all incoming and outgoing traffic. Get started.
SLOs cover a wide range of monitoring options for different applications. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. One template explicitly targets service performance monitoring.
Real-time monitoring with out-of-the-box features Real-time data and monitoring are crucial for maintaining situational awareness of IT environment stability and performance, especially during a crisis. They also enable companies to measure the effectiveness of their remediation activities to ensure that recoveries proceed as expected.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content