This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Site Reliability Engineers (SREs) also face significant challenges in maintaining database reliability, ensuring performance, and preventing disruptions in highly dynamic and distributed environments. For SREs, this means better proactive monitoring, fewer database-related incidents, and greater stability in production environments.
Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. Reducing fragmentation enables DevOps and site reliability engineering (SRE) teams to work in a unified way to ensure code quality and security. Gaining speed without sacrificing quality.
Observability is no longer just for IT Ops Observability is no longer just about monitoring IT systems. Its not just for IT Ops but a critical capability for platform engineering, SREs, developers, as well as business and IT executives. Its aboutunderstandingand automating the entire digital ecosystem.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
Our latest enhancements to the Dynatrace Dashboards and Notebooks apps make learning DQL optional in your day-to-day work, speeding up your troubleshooting and optimization tasks. These ready-made dashboards offer your platform engineers, who oversee Kubernetes environments, immediate and comprehensive data visibility.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. Grabner also introduced four ways organizations can turbocharge their performance engineering with automation. Automating monitoring.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. Platform engineering: Build for self-service Self-service deployment is a key attribute of platform engineering. “It makes them more productive.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? Real-time monitoring of user application and service interactions.
But without automated workflows, IT professionals are finding it difficult to monitor, manage, secure, and troubleshoot applications at scale. Despite best efforts, human beings can’t match the accuracy and speed of computers. ” Driving intelligent multicloud automation Speed is essential for DevSecOps teams.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
For executives, these directives present several challenges, including compliance complexity, resource allocation for continuous monitoring, and incident reporting. For example, for companies with over 1,000 DevOps engineers, the potential savings are between $3.4
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Now our environment where we’ll be deploying our application under test is now automatically monitored by Dynatrace! This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. This can be anything from adjusting monitoring and alerting to making code changes in production. Dynatrace news.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Stage 2: Service monitoring.
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Don’t worry, when it comes to SAP monitoring, Dynatrace has you covered. Simplify SAP HANA performance monitoring and analysis.
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Follow along to create this host monitoring dashboard We will create a basic Host Monitoring dashboard in just a few minutes. Create a new dashboard.
This is why we’re proud to announce fully automated and AI-powered full-stack monitoring for OpenShift 4.0 Traditional monitoring systems cannot keep up with the speed of change in those highly dynamic large-scale container environments. Automated distributed tracing, deep monitoring and AI-powered answers for OpenShift 4.0
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Whether you're a developer, DevOps engineer, or IT manager, this will help you make a smart choice for your monitoring needs. It combines two earlier projects, OpenCensus and OpenTracing, and gives you a unified, vendor-neutral way to monitor systems. What Are OpenTelemetry and Dynatrace?
By Alex Hutter , Falguni Jhaveri and Senthil Sayeebaba Over the past few years Content Engineering at Netflix has been transitioning many of its services to use a federated GraphQL platform. By transacting with a database which is monitored by a CDC connector that creates events, or b.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. Dynatrace news.
Kubernetes was architected to allow for additional technologies and services to assist in speed, scalability and reducing the overall complexity which can arise from a Microservices environment. Let’s go into a bit of detail on each pillar and the extended Observability Dynatrace provides: Metrics: Cluster health and utilization monitoring.
Take one look at LinkedIn right now, and you’ll notice some of the most in-demand jobs include application developers and software engineers. After a deeper dive, you’ll find many companies across multiple industries are looking for site reliability engineers or SREs.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. With Azure Functions, engineers don’t have to worry about provisioning and maintaining underlying hardware; they simply upload their code, and it’s up and running seconds later. Dynatrace news.
I am delighted to share, Dynatrace has been named a Leader for the 11 th consecutive time in the 2021 Gartner Magic Quadrant for Application Performance Monitoring (APM) report. Dynatrace enables our customers to tame cloud complexity, speed innovation, and deliver better business outcomes through BizDevSecOps collaboration.
These criteria include operational excellence, security and data privacy, speed to market, and disruptive innovation. But as a company with a mission to “ Do It Right ” and be a relentless ally for customers and communities, the high-cost monitoring solutions it was using provided only limited insights into end-user experiences.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly.
In such contexts, platform engineering offers a compelling solution to enable business competitiveness in a manner that significantly enhances the developer experience. Treating an Internal Developer Platform (IDP) as a product is an emerging paradigm within platform engineering communities.
We’ve worked closely with our partner AWS to deliver a complete, end-to-end picture of your cloud environment that includes monitoring support for all AWS services. By leveraging the AWS Lambda Extensions API , Dynatrace brings the unique value of its Davis AI-engine for fully automatic root cause analysis to AWS Lambda.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. Next-gen Infrastructure Monitoring. Next up, Steve introduced enhancements to our infrastructure monitoring module. AI-powered Answers for Native Mobile App Monitoring.
Search Engine Optimization Checklist (PDF). Search Engine Optimization Checklist (PDF). Search engine optimization (SEO) is an essential part of a website’s design, and one all too often overlooked. Testing And Monitoring. A Smashing Guide To The World Of Search Engine Optimization. by Search Engine Journal.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually. It helps to assess the long- and short-term efficiency and speed of DevOps.
This automatic analysis enables engineers to spend more time innovating and improving business operations. Each piece of the AIOps triumvirate plays a crucial role in the automation process to speed innovation. Dynatrace Synthetic Monitoring shows availability, uptime, and average load and response times.
To speed up release frequency, they’re investing in delivery-pipeline automation. The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs. Read more about the basics of Site Reliability Engineering below.).
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. What is a data lakehouse?
Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. Check back here throughout the event for the latest news, insights, and announcements.
The scale and speed of the program triggered challenges for these banks that they had never before imagined. Speed up loan processing to deliver critically needed relief to small businesses? Full speed ahead. Let your Dynatrace Sales Engineer know you want to get started with Digital Business Analytics.
Gartner just released its latest Magic Quadrant for Application Performance Monitoring (APM) , and a separate Critical Capabilities for APM report. Gartner, Magic Quadrant for Application Performance Monitoring, Charley Rich, Federico De Silva, 22 April 2020. Dynatrace news. Before 2015, Dynatrace was listed as Compuware.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues.
SLOs have evolved beyond basic target measurements; they are powerful guidance tools for site reliability engineers (SREs) and DevOps platform teams to help direct areas of improvement in both CI/CD as well as production processes of every organization. Step 7: Ensure proactive SLO monitoring and alerting.
Existing observability and monitoring solutions have built-in limitations when it comes to storing, retaining, querying, and analyzing massive amounts of data. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































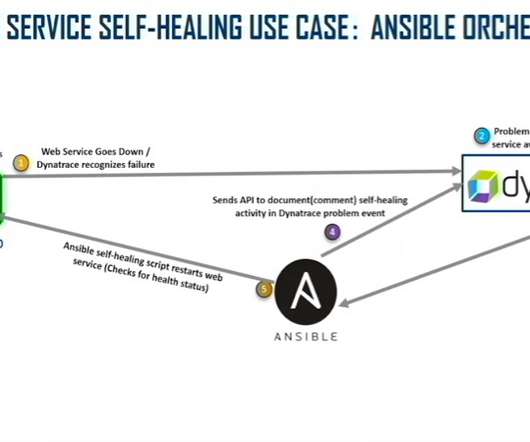















Let's personalize your content