This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Identifying defects and troubleshooting for their root cause is one of the important but painful tasks in softwareengineering and essential to maintaining good quality software. To help them in the quest for improving MTTR, software developers use application monitoring tools.
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges softwareengineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. All important health signals are highlighted.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. Platform engineering: Build for self-service Self-service deployment is a key attribute of platform engineering. “It makes them more productive.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
In the dynamic world of online services, the concept of site reliability engineering (SRE) has risen as a pivotal discipline, ensuring that large-scale systems maintain their performance and reliability.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
In recent years, observability has re-emerged as a critical aspect of DevOps and softwareengineering in general, driven by the growing complexity and scale of modern, cloud-native applications.
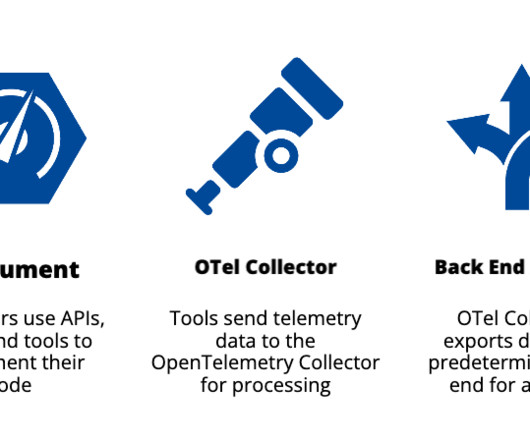
This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. They must also provide enough information for partner engineers to identify the problem with the underlying service in cases of system-level issues. there is a dedicated collector.
These resources generate vast amounts of data in various locations, including containers, which can be virtual and ephemeral, thus more difficult to monitor. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. AWS monitoring best practices. Automate monitoring tasks.
Following are some of the coolest things weve seen engineers do with Live Debugger. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of softwareengineering. Maybe you want to monitor performance under different system loads. In many ways, it’s more of an art than a science.
Take one look at LinkedIn right now, and you’ll notice some of the most in-demand jobs include application developers and softwareengineers. After a deeper dive, you’ll find many companies across multiple industries are looking for site reliability engineers or SREs.
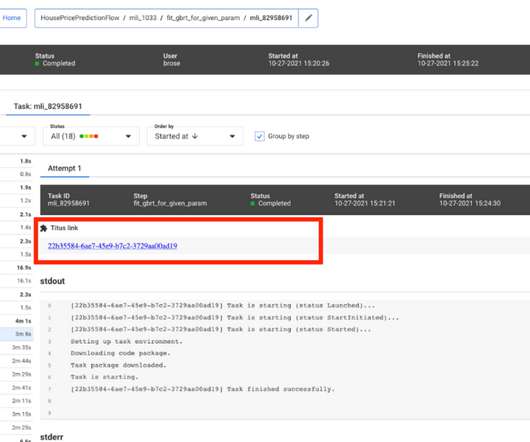
Open-Sourcing a Monitoring GUI for Metaflow, Netflix’s ML Platform tl;dr Today, we are open-sourcing a long-awaited GUI for Metaflow. The Metaflow GUI allows data scientists to monitor their workflows in real-time, track experiments, and see detailed logs and results for every executed task.
Softwareengineering for machine learning: a case study Amershi et al., More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and softwareengineering is changing at Microsoft with the rise of AI and ML. ICSE’19.
Softwareengineers didn’t need to understand the database, and even if they owned it, it was just a single component of the system. Guaranteeing software quality was much easier because the deployment happened rarely, and things could be captured on time via automated tests. Reasoning about applications is now much harder.
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
After investigating, the softwareengineering team discovered that it wasn’t leveraging application performance monitoring (APM) tooling data to its full potential. First, the organization assembled a group of motivated SMEs, including members of the product team as well as iOS and Android engineers.
Build an umbrella for Development and Operations In modern softwareengineering, the discipline of platform engineering delivers DevSecOps practices to developers to bridge the gaps between development, security, and operations and enhance the developer experience. However, other data formats, like logs, can also be employed.
Cloud providers enable faster delivery of new services but require new practices, including a need for closely monitoring costs. One key advantage of this integration is a single point of access to monitoring, logging, and other information needed to keep software development operations running efficiently.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a softwareengineer takes nine hours to remediate a problem within a production application. With that, Softwareengineers, SREs, and DevOps can define a broad automation and remediation mapping.
The Client and UI Engineering team built a certification test with these streams to analyze both the device logs as well as the pictures rendered on the screen. The Performance Engineering team specializes in optimizing resource utilization at Netflix. Challenge 4: How do we continuously monitor AV1 streaming?
The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. There are several ways Dynatrace monitors and alerts on the impact of service disruption. Ready to learn more? Then read on! Fact #1: AWS EC2 outage properly documented.
To address this need, Dynatrace now provides automation for DevSecOps collaboration that associates ownership information with monitored services to further minimize mean-time-to-restore (MTTR). Associating ownership-team details with monitored services is flexible. team structure, or links to external resources such as a wiki.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
It is a crucial aspect of distributed systems, as it allows stakeholders such as SoftwareEngineers, Site Reliability Engineers , and Product Managers to troubleshoot issues with their service, monitor performance, and gain insights into the software system's behavior.
The Dynatrace AI engine, Davis,?automatically Other tools in the market for monitoring AWS Lambda traces can’t deliver real end-to-end visibility from the end-user perspective across all?moving – Robert Trueman, Head of SoftwareEngineering at CDL. Real User Monitoring. potential gaps and blind spots?make
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. “It’s quite a big scale,” said an engineer at the financial services group.
The 737Max and Why SoftwareEngineers Might Want to Pay Attention As someone with a bit of a reputation for talking about aviation and software development and operations , I’ve been asked about the 737Max repeatedly over the past week. To cope, they added additional monitoring and control systems.
A single instance of OneAgent can handle the monitoring of many types of entities , including servers, applications, services, databases, and more. But what if a particular metric is crucial for your monitoring needs and it isn’t there? Let the Davis AI causation engine analyze additional metrics. Dynatrace news.
Techniques such as statistics-based monitoring and behavior-based monitoring are also possible. Statistics-based monitoring is when organizations take statistics from exploits that vendors have detected and feed them into a system to learn and identify these attacks. Application logs are a good data source for this method.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Teams can plug in new tools for testing, deployment, or even monitoring without having to modify a lot of existing automation tools. Dynatrace news.
Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. To learn more about platform engineering, explore the following resources.
To handle this challenge, enterprises need to automate and streamline the onboarding and lifecycle of tool configurations in the software development processes, including aspects of observability, security, alerting, and remediation. Development teams must set up tailored configurations for each tool and component they’re responsible for.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Over the years, this platform took on support for both elastic online services and fully featured batch workloads supporting use cases across Netflix engineering.
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior softwareengineer Yarden Laifenfeld explored developer observability. Why is developer observability important for engineers? With traditional monitoring tools, the granular data that developers require typically involves manual preparation.
A key to success from the start was that not only we did build Dynatrace, but Anita’s team was also always “Customer 0” of Dynatrace because clearly we were in need of a world class monitoring platform that gave us visibility into our deployments in dev, staging and production. Wave two: NoOps to ensure stability!
Application security is a softwareengineering term that refers to several different types of security practices designed to ensure applications do not contain vulnerabilities that could allow illicit access to sensitive data, unauthorized code modification, or resource hijacking. Dynatrace news. So, why is all this important?
If a microservice falls in the forest and all your monitoring solutions report it differently, can operators accurately trace what happened and automate a response? Different monitoring point solutions, such as Jaeger, Zipkin, Logstash, Fluentd, and StatsD, each have their own way of observing and recording such an event.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. One of the great aspects of the AI Age is that more people will be able to build software.
A dashboard for monitoring activities such as database locks, connected sessions, and prepared transactions for multiple servers. They come with features such as query analysis, performance monitoring, and advanced SQL refactoring capabilities.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these best practices to innovate at speed without sacrificing quality, reliability, or security. SRE applies softwareengineering principles to operations and infrastructure processes. – blog.
Supporting developers through those checklists for edge cases, and then validating that each team’s choices resulted in an architecture with all the desired security properties, was similarly not scalable for our security engineers. Netflix engineers talk a lot about the concept of a “ Paved Road ”.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content