This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
With all the data collected and powered by our Davis AI-driven causation engine, Dynatrace automatically identifies slowdowns in your applications and services and points you to their root cause. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Network services visibility (DNS, NTP, ActiveDirectory).
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively. This enables proactive changes such as resource autoscaling, traffic shifting, or preventative rollbacks of bad code deployment ahead of time.
By the summer of 2020, many UI engineers were ready to move to GraphQL. The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? To detect issues proactively, we need to simulate traffic and predict system behavior in advance.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Once Dynatrace sees the incoming traffic it will also show up in Dynatrace, under Transaction & Services. Dynatrace news. Keptn uses SLO definitions to automatically configure Dynatrace or Prometheus alerting rules.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
Personalized Experience Refresh Netflix Recommendation engine continuously refreshes recommendations for every member. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
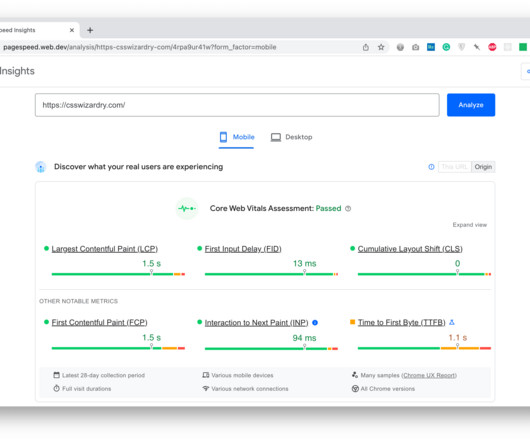
All Core Web Vitals data used to rank you is taken from actual Chrome-based traffic to your site. The Core Web Vitals Metrics Generally, I approve of the Core Web Vitals metrics themselves ( Largest Contentful Paint , First Input Delay , Cumulative Layout Shift , and the nascent Interaction to Next Paint ).
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices. What is Docker? Networking.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic.
Open-source metric sources automatically map to our Smartscape model for AI analytics. With this announcement, Dynatrace brings the value of its AI engine, the scale, security, and automation of Dynatrace OneAgent and the scale of our platform (which can handle 50,000 hosts) to open source technologies so that you get the best of both worlds.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. As you might know, we recently simplified observability for all custom metrics by making it possible to ingest hundreds of custom data sources into Dynatrace. Events and alerts.
As a result, site reliability has emerged as a critical success metric for many organizations. Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. Mobile retail e-commerce spending in the U. Service-level objectives (SLOs).
VPC Flow Logs is a feature that gives you the capability to capture more robust IP traffic data that traverses your VPCs. A full list of metrics can be found here and include dimensions such as the following: Packets. Log Metrics. What is VPC Flow Logs. The number of packets transferred during the flow. Resource type.
Dynatrace is fully committed to the OpenTelemetry community and to the seamless integration of OpenTelemetry data , including ingestion of custom metrics , into the Dynatrace open analytics platform. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control.
According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success.
In February 2021, Dynatrace announced full support for Google’s Core Web Vitals metrics , which will help site owners as they start optimizing Core Web Vitals performance for SEO. A page with low traffic and failing CWV compliance does not hold the same weight as a failing page with high traffic. Dynatrace news. Tell me more!
To effectively address such warning signs, organizations need to focus on putting observability data into context—mapping and visualizing relationships and dependencies within all collected telemetry data—not only traces, metrics, and logs. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. Amazon Data Firehose helps stream logs to the right destination But your SREs and DevOps engineers know CloudWatch is not the terminal destination for data but rather an intermediate station.
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. SLOs must be evaluated at 100%, even when there is currently no traffic. Data Explorer “test your Metric Expression” for info result coming from the above metric.
Furthermore, with this update you can: Get insights into connection pool metrics in context with the applications and services that use them. Get insights into connection pool metrics in context with the applications and services that use them. On the overview page you’ll find the metrics aggregated across all detected pools.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? Enterprises now have access to myriad metrics they can track and measure, but an abundance of choice doesn’t equal actionable insight. The result?
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time.
Rexed, Singh, and Stull outline the importance of metrics, traces, logs, events, and the role they play in achieving full–context Kubernetes observability and driving automated responses in hybrid and multi-cloud environments. To ensure everything runs smoothly, they employ the Dynatrace automated monitoring and observability solution.
A metric crossed a threshold. Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance. Metrics are a key part of understanding application health. Regional traffic evacuations.
Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. The F5 BIG-IP LTM extension offers a complete view, beyond simple metrics, into your Local Traffic Manager (LTM) platform. Advanced load balancer analysis.
For engineers, instead of whodunit, the question is often “what failed and why?” An engineer can find herself digging through logs, poring over traces, and staring at dozens of dashboards. Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. the trace, logs, analysis?—?and
In these circumstances, Site Reliability Engineering teams face two big challenges: Measuring uptime is not enough anymore. Which metrics are relevant for your business, anyway? Modern observability tools provide many metrics, but which ones are really important for your business?
Turnkey cluster overload protection with adaptive traffic management and control. The ALR mechanism also ensures maximum stability when the actual load exceeds the capacity of the cluster (though a statistically valid set of requests is still captured for analysis by the Dynatrace Davis AI causation engine ). Impact on disk space.
This is where Site Reliability Engineering (SRE) practices are applied. SREs face ever more challenging situations as environment complexity increases, applications scale up, and organizations grow: Growing dependency graphs result in blind spots and the inability to correlate performance metrics with user experience.
The more data ingestion channels you provide to the Dynatrace Davis® AI engine, the more comprehensive Dynatrace automated root cause analysis becomes. It also enhances syslog messages with additional context and optimizes network traffic, improving overall system resilience and security.
Niosha Behnam | Demand Engineering @ Netflix At Netflix we prioritize innovation and velocity in pursuit of the best experience for our 150+ million global customers. In the event of an isolated failure we first pre-scale microservices in the healthy regions after which we can shift traffic away from the failing one.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. It is proactive monitoring that simulates traffic with established test variables, including location, browser, network, and device type.
IoT is transforming how industries operate and make decisions, from agriculture to mining, energy utilities, and traffic management. Both methods allow you to ingest and process raw data and metrics. They enable real-time tracking and enhanced situational awareness for air traffic control and collision avoidance systems.
Certain SLOs can help organizations get started on measuring and delivering metrics that matter. With this objective, the app ensures that users experience real-time feedback and immediate updates when logging workouts, recording sets and reps, or tracking performance metrics. The Apdex score of 0.85
RUM gathers information on a variety of performance metrics. Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). Real user monitoring limitations.
Python has long been a popular programming language in the networking space because it’s an intuitive language that allows engineers to quickly solve networking problems. Demand Engineering Demand Engineering is responsible for Regional Failovers , Traffic Distribution, Capacity Operations and Fleet Efficiency of the Netflix cloud.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content