This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our latest enhancements to the Dynatrace Dashboards and Notebooks apps make learning DQL optional in your day-to-day work, speeding up your troubleshooting and optimization tasks. These ready-made dashboards offer your platform engineers, who oversee Kubernetes environments, immediate and comprehensive data visibility.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Chaos scenario: Random pods executing worker instances are deleted.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. These tags will allow us to create dashboards, request attributes or calculate service metrics specifically for our application under test. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. Grabner also introduced four ways organizations can turbocharge their performance engineering with automation.
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
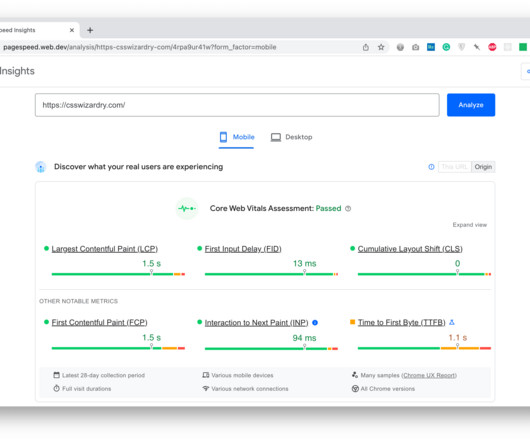
Google do strongly encourage you to focus on site speed for better performance in Search, but, if you don’t pass all relevant Core Web Vitals (and the applicable factors from the Page Experience report) they will not push you down the rankings. While Core Web Vitals can help with SEO, there’s so much more to site-speed than that.
Metrics that offer measurable, repeatable insight into the user experience from the moment they arrive on a website from a mobile or desktop device. Great user experiences start with Core Web Vitals (CWVs) — a set of metrics defined by Google to help measure user experience at scale. When do these metrics matter?
While increasing both the precision and the recall of our secrets detection engine, we felt the need to keep a close eye on speed. In a gearbox, if you want to increase torque, you need to decrease speed. So it wasn’t a surprise to find that our engine had the same problem: more power, less speed.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. We accomplish this by gathering detailed column-level metrics that offer insights into the state and quality of each impression.
Annie leads the Chrome SpeedMetrics team at Google, which has arguably had the most significant impact on web performance of the past decade. It's really important to acknowledge that none of this would have been possible without the great work from Annie and her small-but-mighty SpeedMetrics team at Google.
We’re able to help drive speed, take multiple data sources, bring them into a common model and drive those answers at scale.”. With this announcement: Davis now automatically ingests additional Kubernetes events and metrics, including state changes, workload changes and critical events across clusters, containers and runtimes.
I never thought I’d write an article in defence of DOMContentLoaded , but here it is… For many, many years now, performance engineers have been making a concerted effort to move away from technical metrics such as Load , and toward more user-facing, UX metrics such as Speed Index or Largest Contentful Paint. Or are they…?
To speed up release frequency, they’re investing in delivery-pipeline automation. The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs. Which metrics are relevant for your business, anyway?
As a result, site reliability has emerged as a critical success metric for many organizations. Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. Mobile retail e-commerce spending in the U. Service-level objectives (SLOs).
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. Achieving the ideal state with aggregated, centralized log data, metrics, traces , and other metadata is challenging—particularly for multicloud environments. And how can this combination unlock greater IT automation?
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. Enable the Davis AI causation engine to automatically analyze every metric.
By leveraging the AWS Lambda Extensions API , Dynatrace brings the unique value of its Davis AI-engine for fully automatic root cause analysis to AWS Lambda. Serverless functions extend applications to accelerate speed of innovation. Now let’s take a look how each of these advantages reveal themselves in Dynatrace.
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. – blog.
How does this affect your page speed, your Core Web Vitals, your search rank, your business, and most important – your users? For almost fifteen years, I've been writing about page bloat, its impact on site speed, and ultimately how it affects your users and your business. Keep scrolling for the latest trends and analysis.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. Further, it builds a rich analytics layer powered by Dynatrace causational artificial intelligence, Davis® AI, and creates a query engine that offers insights at unmatched speed.
In such contexts, platform engineering offers a compelling solution to enable business competitiveness in a manner that significantly enhances the developer experience. Treating an Internal Developer Platform (IDP) as a product is an emerging paradigm within platform engineering communities.
Search Engine Optimization Checklist (PDF). Search Engine Optimization Checklist (PDF). Search engine optimization (SEO) is an essential part of a website’s design, and one all too often overlooked. A Smashing Guide To The World Of Search Engine Optimization. Prioritizing Metrics Online metrics are almost limitless.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Developers also need to automate the release process to speed up deployment and reliability. Dynatrace news. Why is automated orchestration critical?
The only way to address these challenges is through observability data — logs, metrics, and traces. IT pros want a data and analytics solution that doesn’t require tradeoffs between speed, scale, and cost. Your key business objectives will drive your strategy and metrics. But it doesn’t stop there.
SLOs have evolved beyond basic target measurements; they are powerful guidance tools for site reliability engineers (SREs) and DevOps platform teams to help direct areas of improvement in both CI/CD as well as production processes of every organization. Step 4: Identify key metrics to use as service-level indicators (SLIs).
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
The scale and speed of the program triggered challenges for these banks that they had never before imagined. Speed up loan processing to deliver critically needed relief to small businesses? Full speed ahead. Let your Dynatrace Sales Engineer know you want to get started with Digital Business Analytics.
The Client and UI Engineering team built a certification test with these streams to analyze both the device logs as well as the pictures rendered on the screen. With multiple iterations, the team arrived at a recipe that significantly speeds up the encoding with negligible compression efficiency changes.
Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. To help you speed up MTTR, there are several levels of visualization to help slice and dice through information: Instances. Pool nodes. Virtual servers. Interfaces.
You can, for example, drive ad hoc multidimensional analysis to analyze, chart, and report on microservice-based metrics without code changes. You can use powerful dashboard capabilities to visualize whatever metrics are most relevant to your teams and let the Davis AI causation engine automatically identify the root cause of problems.
IT pros need a data and analytics platform that doesn’t require sacrifices among speed, scale, and cost. Therefore, many organizations turn to a data lakehouse, which combines the flexibility and cost-efficiency of a data lake with the contextual and high-speed querying capabilities of a data warehouse. What is a data lakehouse?
As they increase the speed of product innovation and software development, organizations have an increasing number of applications, microservices and cloud infrastructure to manage. Further, many organizations—more than 90%—have turned to cloud computing to navigate the highwire act of balancing speed and quality.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. Observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. The collected set of metrics are queries for some timeframe.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually. It helps to assess the long- and short-term efficiency and speed of DevOps.
Telemetry data — such as metrics, logs, and traces — gives IT teams crucial context to understand how all entities are connected. Without appropriate context, the so-called pillars of observability — metrics, logs, and traces — are simply sources of data, not insights. These are not only numerous but also dynamic.
We asked hundreds of developers, engineers, software architects, dev teams, and IT leaders at DeveloperWeek to discover the current NoSQL vs. SQL usage, most popular databases, important metrics to track, and their most time-consuming database management tasks. Most Important Metric Tracked For Database Performance.
This is where Site Reliability Engineering (SRE) practices are applied. SREs face ever more challenging situations as environment complexity increases, applications scale up, and organizations grow: Growing dependency graphs result in blind spots and the inability to correlate performance metrics with user experience.
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior software engineer Yarden Laifenfeld explored developer observability. Why is developer observability important for engineers? When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics.
Traditional monitoring systems cannot keep up with the speed of change in those highly dynamic large-scale container environments. These enhancements include: Integration of the new Kubernetes/OpenShift cluster metrics with custom charting. Native integration of Kubernetes/OpenShift node events with the Davis AI causation engine.
Site Reliability Engineering (SRE) relies on observability and the automated setup of observability to find answers to questions like, “Did my deployment work?”, “Did the change improve our users’ experience?” , or “Did the last update cause the application issue or was it something else?” Dynatrace enables software intelligence as code.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content