This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Collect metrics on energy consumption or derive them from existing signals. Platform engineers can set defaults for development teams, such as the number of replicas a service should have or whether it scales automatically. The post Sustainability: Thoughts from a software engineer appeared first on Dynatrace news.
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need to catch up? Check out Part 1.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. What is Prometheus?
Back during Perform 2019, we introduced the next generation of the Dynatrace AI causation engine , also known as Davis. becomes the default causation engine and will replace the previous version as the default for all new environments. as the default AI engine. AI causation engine. All existing Davis 1.0
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. This blog post explores the Reliability metric , which measures modern operational practices. It forms the cornerstone of chaos engineering experiments. Why reliability?
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. Taking a strategic Kubernetes platform engineering approach Spier noted that keeping Kubernetes simple requires a strategic approach.
In software engineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
Select any execution you’re interested in to display its details, for example, the content response body, its headers, and related metrics. All metrics and events storing information about execution details are available for further exploratory analytics utilizing Dashboards, Notebooks, or Davis CoPilot.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Combined with Microsoft Sentinel, Dynatrace automation and AI capabilities provide SecOps teams with deeper intelligence to detect attacks, vulnerabilities, audit logs, and problem events based on metrics, logs, and traces it collects from monitored environments.
Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams. Engineering teams are overwhelmed with stuff to do.” ” First, Akamas collects metrics, then recommends configuration improvements and applies these recommendations.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Depending on the environment, the different information types provide indicators that reveal potential problems for your customers.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
We are proud to s hare Dynatrace has been named the winner in the “ Best Overall AI-based Analytics Company ” category, recognized for our innovation and the business-driving impact of our AI engine, Davis. . The post Dynatrace wins AI Breakthrough Award for Davis AI engine appeared first on Dynatrace blog.
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. Recovery time of the throughput metric.
To get a better idea of OpenTelemetry trends in 2025 and how to get the most out of it in your observability strategy, some of our Dynatrace open-source engineers and advocates picked out the innovations they find most interesting. Because its constantly evolving, staying up to date with the latest in OpenTelemetry is no small feat.
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. Introducing metric extraction from business events Beginning with Dynatrace SaaS version 1.257, you can extract metrics from ingested business events.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
With this Google Cloud Ready integration, Dynatrace ensures that AlloyDB for PostgreSQL users can now ingest metrics along with existing Google Cloud data. Out of the box, Dynatrace also works with Google Cloud’s Cloud Run, BigQuery, Compute Engine, and dozens of other native Google Cloud services and offerings.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
In January and February, we spoke with a couple of the top influencers in government technology, including Jamie Holcombe , Chief Information Officer at the United State Patent and Trademark Office [USPTO]; and Dimitris Perdikou , Head of Engineering at the UK Home Office, Migration and Borders.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
Kubernetes Site Reliability Engineers (SREs) frequently encounter complex scenarios demanding swift and effective troubleshooting to maintain the stability and reliability of clusters.
For years, logs have been the dominant approach many observability vendors have taken to report business metrics on dashboards. Within the target pipeline, you can also define processing rules, extract metrics, set the security context, and define retention periods.
All metrics, traces, and real user data are also surfaced in the context of specific events. With Dynatrace, you can create custom metrics based on user-defined log events. Also depicted is Dynatrace instrumentation of the pods that deliver metrics and trace data to the Dynatrace environment.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Our audits would detect this and alert the on-call data engineer (DE).
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. If you don’t have one, you can use a trial account.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Seasonal Baseline: Ideal for metrics with predictable seasonal patterns, this option leverages Davis AI to create a confidence band based on historical data, accounting for expected variations.
Challenge: Dont understand the cascading effects of their setup on these perceived black box personalization systems - Personalization System Engineers Role: Develop and operate the personalization systems. Challenge: End up spending unplanned cycles on title launch and personalization investigations.
Finally, Dynatrace requires metrics data to be sent with delta temporality , not cumulative temporality. This means that youll need to include the cumulativetodelta processor in: Your Collector configuration ( cumulativetodelta ) Your metrics pipeline ( pipelines.metrics ) Never store your Dynatrace token and tenant name in plain text.
Imagine a ML practitioner on the Netflix Content ML team, sourcing features from hundreds of columns in our data warehouse, and creating a multitude of models against a growing suite of metrics. Subsequent versions of the model will result from experimenting with hyper parameters, tweaking feature engineering, or conducting feature diets.
Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively. It also helps to have access to OpenTelemetry, a collection of tools for examining applications that export metrics, logs, and traces for analysis.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
At the heart of Dynatrace Digital Experience Monitoring (DEM) is Davis, the state-of-the-art AI engine that accurately prioritizes the severity of each detected performance anomaly in terms of its potential impact on real users and business KPIs. Leverage AI assistance to deliver better customer experience.
By the summer of 2020, many UI engineers were ready to move to GraphQL. The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations.
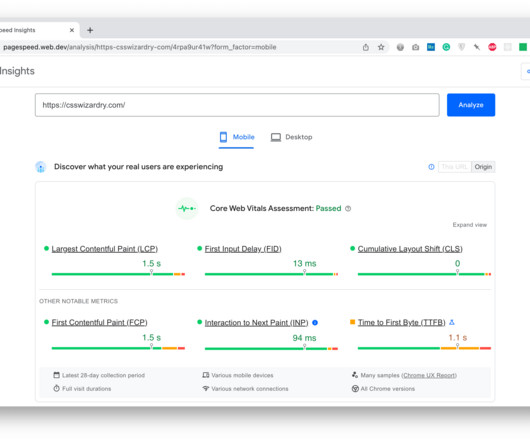
The Core Web Vitals Metrics Generally, I approve of the Core Web Vitals metrics themselves ( Largest Contentful Paint , First Input Delay , Cumulative Layout Shift , and the nascent Interaction to Next Paint ). All user-centric Core Web Vitals metrics will be represented in the dataset.
To calculate the service-level indicator for the Kubernetes namespace memory efficiency SLO, simply query the memory working set and request the memory metrics that are provided out of the box. However, if you require more granular information, you can adjust the levels for resource utilization monitoring accordingly.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content