This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Average query response time.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
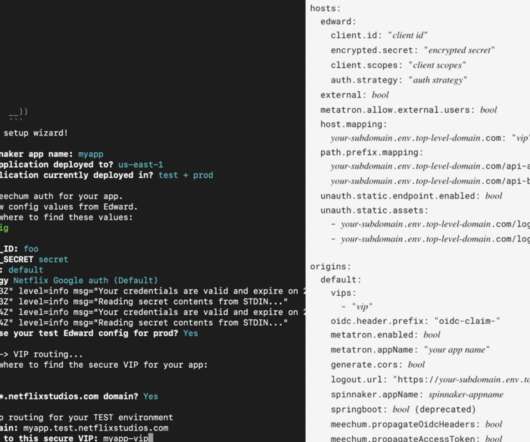
a Netflix member via Twitter This is an example of a question our on-call engineers need to answer to help resolve a member issue?—?which Now let’s look at how we designed the tracing infrastructure that powers Edgar. We needed to increase engineering productivity via distributed request tracing.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
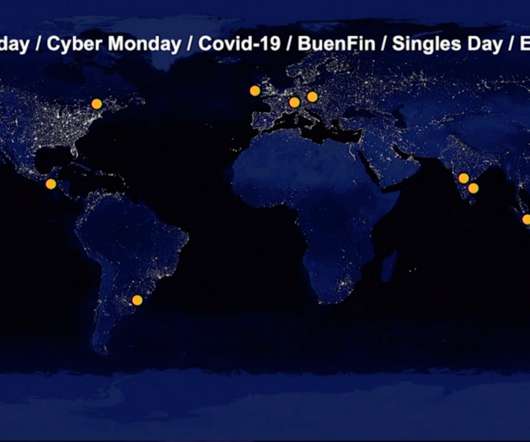
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. Five-nines availability has long been the goal of site reliability engineers (SREs) to provide system availability that is “always on.” What is always-on infrastructure?
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice?
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? This approach provides a few advantages: Low burden on existing systems: Log processing imposes minimal changes to existing infrastructure.
This tier extended existing infrastructure by adding new backend components and a new remote call to our ads partner on the playback path. To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Once Dynatrace sees the incoming traffic it will also show up in Dynatrace, under Transaction & Services. Dynatrace news. Keptn uses SLO definitions to automatically configure Dynatrace or Prometheus alerting rules.
By the summer of 2020, many UI engineers were ready to move to GraphQL. The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations.
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. What is Docker? What is Kubernetes?
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. CRITICAL : This traffic affects the ability to play.
With the release of Dynatrace version 1.249, the Davis® AI Causation Engine provides broader support to subsequent Kubernetes issues and their impact on business continuity like: Automated Kubernetes root cause analysis. Such context is easy to understand using the Dynatrace Davis AI engine. Incidents are harder to solve.
With most employees now working from home, and the demand on e-commerce platforms hits an all-time high, applications and infrastructure are under intense pressure with new usage patterns that have never been planned for or tested against. IT teams are on the frontlines of these efforts.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. What are the issues with traffic losses and connectivity drops? If the network is sluggish, an application may also be slow, frustrating users. Without the network, nothing will happen,” Ziemianowicz said.
This is article was written by Dirceu Pereira Tiegs, Site Reliability Engineer at Auth0, and originally was originally published in Auth0. We designed Auth0 from the beginning so that it could run anywhere: on our cloud, on your cloud, or even on your own private infrastructure. A lot has changed since then in Auth0.
While today’s IT world continues the shift toward treating everything as a service, many organizations need to keep their environments under strict control while managing their infrastructure themselves on-premises. Based on monitored traffic, Dynatrace OneAgent is capable of automatic recognition of topological relations.
Generally speaking, cloud migration involves moving from on-premises infrastructure to cloud-based services. In cloud computing environments, infrastructure and services are maintained by the cloud vendor, allowing you to focus on how best to serve your customers. However, it can also mean migrating from one cloud to another.
A unified platform approach to observability and security Dynatrace and its partners offer powerful solutions to complex business resiliency challenges through an observability and security platform that delivers a unified view of applications, infrastructure, and business processes.
For today’s highly dynamic and exceedingly complex production environments, performance problems that are evident at the service level (for example, slow response times or failed requests) are often the result of underlying (cloud) infrastructure issues. Enrich OpenTelemetry instrumentation with high-fidelity data provided by OneAgent.
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. Managing this change is difficult.
The success of an organization often depends on the quality of the on-premises or physical IT infrastructure, among other things. Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. Monitor Cisco and any other devices.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
With sniffers, network performance engineers were ultimately able to relate wire data performance to what business owners expected from the networks they financed. With tools like ApplicationVantage, network engineers discovered application inefficiencies and advised on corrective actions. Technology developments come in waves.
An easy, though imprecise, way of thinking about Netflix infrastructure is that everything that happens before you press Play on your remote control (e.g., Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. are you logged in?
Organizations are doing their best to monitor what they can, often using disparate tools for logs, infrastructure, and digital experience. The webinar begins with an overview of Kubernetes, emphasizing its popularity and the technical simplicity that underscores the value of infrastructure as code.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
Google has a pretty tight grip on the tech industry: it makes by far the most popular browser with the best DevTools, and the most popular search engine, which means that web developers spend most of their time in Chrome, most of their visitors are in Chrome, and a lot of their search traffic will be coming from Google. Chrome for iOS?
Minimized cross-data center network traffic. – A Dynatrace customer, Head of Performance Engineering. This is achieved by active-active deployment for optimum hardware utilization, thus eliminating the need for separate standby disaster recovery (passive) hosts and the associated infrastructure to store and transfer backup data.
OneAgent technology simplifies deployment across large enterprises and relieves engineers of the burden of instrumenting their applications by hand. One parameter toggles for different capabilities like Kubernetes API monitoring or OneAgent traffic routing. Dynatrace news. One key Dynatrace advantage is ease of activation.
I posed these questions to a couple of friends and colleagues who are responsible for monitoring critical infrastructure and services and my friend Thomas and my colleagues from the Dynatrace Engineering Productivity shared the following stories and screenshots with me. Is working via VPN as good as working from the office?
Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices. The more data ingestion channels you provide to the Dynatrace Davis® AI engine, the more comprehensive Dynatrace automated root cause analysis becomes.
Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. The traffic SLO targets the website’s ability to handle a high volume of transactional activity during periods of high demand. The Apdex score of 0.85
VPC Flow Logs is a feature that gives you the capability to capture more robust IP traffic data that traverses your VPCs. Dynatrace uses your data and its sophisticated AI causation engine Davis® to automatically detect performance anomalies in applications, services, and infrastructure. What is VPC Flow Logs.
For example, an organization might use security analytics tools to monitor user behavior and network traffic. Infrastructure type In most cases, legacy SIEM tools are on-premises. Security analytics must also contend with the multicomponent architecture of modern IT infrastructure.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
Supporting developers through those checklists for edge cases, and then validating that each team’s choices resulted in an architecture with all the desired security properties, was similarly not scalable for our security engineers. Netflix engineers talk a lot about the concept of a “ Paved Road ”.
When thousands of lives are at risk, software infrastructure can make the difference between life and death. The team also recognized the infrastructure is only one part of the equation since the applications that run on that infrastructure are how residents seek information and engage. High Traffic Notification.
First, he pointed to the infrastructure monitoring capabilities as critical to understanding the impact of hardware failures. He also highlighted the benefits of Davis , the AI-engine at the heart of Dynatrace. “We The engineer can get a preview on how to fix the issue, how to identify it. We really like how Davis works.
While infrastructure has historically been treated as a bottleneck where proper scaling and compute power are applied to improve performance, these aspects are now typically addressed by hyperscalers that offer cloud-based infrastructure and infrastructure as a service.
The key information displayed on the standard Dynatrace Problems app and the Infrastructure and Operations App became the basis of their team’s remediation plan. The problem card helped them identify the affected application and actions, as well as the expected traffic during that period.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content