This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How to achieve sustainable IT practices Use observability tools The first step in driving improvements is to obtain a comprehensive view of your IT infrastructure’s climate impact. Platform engineers can set defaults for development teams, such as the number of replicas a service should have or whether it scales automatically.
In softwareengineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. The data community is striving to incorporate the core concepts of engineering rigor found in software communities but still has further to go. Posted with permission.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. The result is a cloud-native approach to software delivery. Why is platform engineering important?
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges softwareengineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
Site Reliability Engineering (SRE) is a systematic and data-driven approach to improving the reliability, scalability, and efficiency of systems. It combines principles of softwareengineering, operations, and quality assurance to ensure that systems meet performance goals and business objectives.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation. SRE drives a “shift left” mindset.
In the dynamic world of online services, the concept of site reliability engineering (SRE) has risen as a pivotal discipline, ensuring that large-scale systems maintain their performance and reliability.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Most backend engineering teams follow a process very similar to what is shown below. If so, we invite you to begin the interview process.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior SoftwareEngineer at Netflix.
Also in April, I was interviewed by Jordi Mon Companys for SoftwareEngineering Daily, and that interview was just published on the SE Daily podcast. government recently released a report calling on the technical community to proactively reduce the attack surface area of softwareinfrastructure.
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
Let the Davis AI causation engine analyze additional metrics. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages. All the data bound to hosts is analyzed by the Davis AI causation engine and made available on custom dashboards and events pages.
Softwareengineering for machine learning: a case study Amershi et al., More specifically, we’ll be looking at the results of an internal study with over 500 participants designed to figure out how product development and softwareengineering is changing at Microsoft with the rise of AI and ML. ICSE’19.
SRE is the transformation of traditional operations practices by using softwareengineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Investing in automation and tooling to avoid toil. SRE vs DevOps?
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a softwareengineer takes nine hours to remediate a problem within a production application. With that, Softwareengineers, SREs, and DevOps can define a broad automation and remediation mapping.
There are a few qualities that differentiate average from high performing softwareengineering organisations. In my experience, the culture is better and the results are better in orgs where engineers and architects obsess over the design of code and architecture. My experience is the opposite.
Build an umbrella for Development and Operations In modern softwareengineering, the discipline of platform engineering delivers DevSecOps practices to developers to bridge the gaps between development, security, and operations and enhance the developer experience.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying softwareengineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. They enable IT teams to identify and address the precise cause of application and infrastructure issues.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
Today, DevOps orchestration is necessary to gain a comprehensive view and means of control over infrastructure, services, and software development practices. One key advantage of this integration is a single point of access to monitoring, logging, and other information needed to keep software development operations running efficiently.
While infrastructure has historically been treated as a bottleneck where proper scaling and compute power are applied to improve performance, these aspects are now typically addressed by hyperscalers that offer cloud-based infrastructure and infrastructure as a service.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. System Components.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
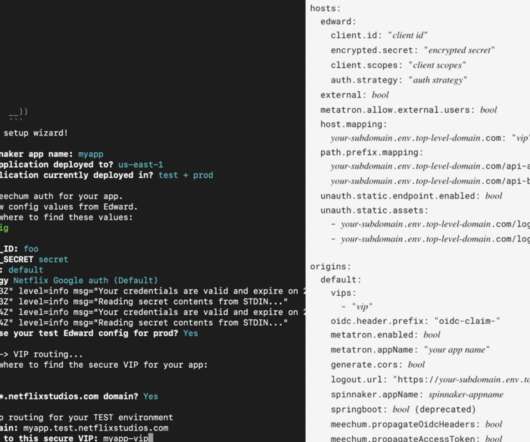
By Astha Singhal , Lakshmi Sudheer , Julia Knecht The Application Security teams at Netflix are responsible for securing the software footprint that we create to run the Netflix product, the Netflix studio, and the business. Our customers are product and engineering teams at Netflix that build these software services and platforms.
Because of its matrix of cloud services across multiple environments, AWS and other multicloud environments can be more difficult to manage and monitor compared with traditional on-premises infrastructure. EC2 is Amazon’s Infrastructure-as-a-service (IaaS) compute platform designed to handle any workload at scale. Amazon EC2.
Supporting developers through those checklists for edge cases, and then validating that each team’s choices resulted in an architecture with all the desired security properties, was similarly not scalable for our security engineers. Netflix engineers talk a lot about the concept of a “ Paved Road ”.
Join us and be a part of the amazing team that brought you this tech-blog; open positions: SoftwareEngineer, Cloud Gaming SoftwareEngineer, Live Streaming References [1] L. Krasula, A. Choudhury, S. Malfait, A. 263–1–8 (2023) [ online ] [2] A.
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. For more background on Growth Engineering and the signup funnel, please have a look at our previous blog post that covers the basics. We need to be constantly adapting and innovating as a result of this change.
Incident management with clearly defined responsibilities Site Reliability Engineers (SRE) are challenged not only to detect problems and identify the root cause quickly but also to remediate problems immediately. Any softwareengineer can search for monitored entities that relate to specific deployments and their respective teams.
In our quest for greater scalability, resilience, and flexibility within the digital infrastructure of our organization, there has been a strategic pivot away from traditional monolithic application architectures towards embracing modern softwareengineering practices such as microservices architecture coupled with cloud-native applications.
About two years ago, we, at our newly formed Machine Learning Infrastructure team started asking our data scientists a question: “What is the hardest thing for you as a data scientist at Netflix?” mainly because of mundane reasons related to softwareengineering. like they would do in a Jupyter notebook.
In response to the scale and complexity of modern cloud-native technology, organizations are increasingly reliant on automation to properly manage their infrastructure and workflows. Operations automation: The operations section addresses the level of automation organizations use in maintaining and managing existing software.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. In effect, the engineer designs and builds the world wherein the software operates. The new category is often called MLOps.
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior softwareengineer Yarden Laifenfeld explored developer observability. Why is developer observability important for engineers? They also care about infrastructure: SREs require system visibility and incident management.
To do that, Anita’s team drove innovation around a common delivery pipeline to enable developers automating operational tasks such as runbook execution to solve infrastructure problems. At Dynatrace our ACE team is enabling our engineers to deliver better software faster. Autonomous Cloud with Dynatrace.
Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. To learn more about platform engineering, explore the following resources.
Motivation Growth in the cloud has exploded, and it is now easier than ever to create infrastructure on the fly. Groups beyond softwareengineering teams are standing up their own systems and automation. At many companies, managing cloud hygiene and security usually falls under the infrastructure or security teams.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content