This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Average query response time.
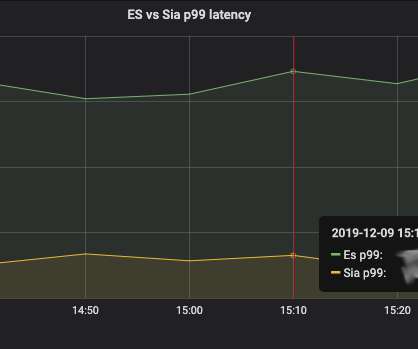
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. Is it a bug in the codebase, a malfunctioning backend service, an overloaded hosting infrastructure, or perhaps a misconfigured network?
Recently, we added another powerful tool to our arsenal: neural networks for video downscaling. In this tech blog, we describe how we improved Netflix video quality with neural networks, the challenges we faced and what lies ahead. How can neural networks fit into Netflix video encoding?
a Netflix member via Twitter This is an example of a question our on-call engineers need to answer to help resolve a member issue?—?which Now let’s look at how we designed the tracing infrastructure that powers Edgar. We needed to increase engineering productivity via distributed request tracing.
The success of an organization often depends on the quality of the on-premises or physical IT infrastructure, among other things. Constantly monitoring infrastructure health state and making ongoing optimizations are essential for Ops teams, SREs (site-reliability engineers), and IT admins. Start monitoring in minutes.
Google has a pretty tight grip on the tech industry: it makes by far the most popular browser with the best DevTools, and the most popular search engine, which means that web developers spend most of their time in Chrome, most of their visitors are in Chrome, and a lot of their search traffic will be coming from Google. somewhere sensible.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. Chaos engineering is a practice that extends beyond traditional failure testing by identifying unpredictable issues.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
Various factors, such as network communication, inter-service dependencies, external dependencies, and scalability issues, can contribute to outages. The scalability, agility, and continuous delivery offered by microservices architecture make it a popular option for businesses today.
Complexity and data volume for IT infrastructure soars to new heights. The volume of data and events grows in tandem with the rising complexity of IT infrastructure. Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools.
Protecting IT infrastructure, applications, and data requires that you understand security weaknesses attackers can exploit. Examples of such weaknesses are errors in application code, misconfigured network devices, and overly permissive access controls in a database. NMAP is an example of a well-known open-source network scanner.
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
If you’re doing it right, cloud represents a fundamental change in how you build, deliver and operate your applications and infrastructure. And that includes infrastructure monitoring. This also implies a fundamental change to the role of infrastructure and operations teams. Able to provide answers, not just data.
Business-focused, unified platform approach : A unified platform approach enables platform engineering and self-service portals, simplifying operations and reducing costs. Davis, the causal AI engine, instantly identifies root causes and predicts service degradation before it impacts users.
Five-nines availability has long been the goal of site reliability engineers (SREs) to provide system availability that is “always on.” Site reliability engineering teams often measure system availability in percentages in the pursuit of 100% uptime. What is always-on infrastructure?
However, if you’re an operations engineer who’s been tasked with migrating to HANA from a legacy database system, you’ll need to get up to speed quickly. Enable the Davis AI causation engine to automatically analyze every metric. Enable the Davis AI causation engine to automatically analyze every metric.
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. With public clouds, multiple organizations share resources.
Sure, cloud infrastructure requires comprehensive performance visibility, as Dynatrace provides , but the services that leverage cloud infrastructures also require close attention. Extend infrastructure observability to WSO2 API Manager. Cloud-based application architectures commonly leverage microservices. What’s next?
Data engineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for data engineering projects and provide detailed implementation steps to get started.
OneAgent gives you all the operational and business performance metrics you need, from the front end to the back end and everything in between—cloud instances, hosts, network health, processes, and services. Let the Davis AI causation engine analyze additional metrics. Example 1: Gain visibility into your NVIDIA GPUs.
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Every day around the world, millions of trips take place across the Uber network, giving users more reliable transportation through ridesharing, bikes, and scooters, drivers and truckers additional opportunities to earn, employees and employers more convenient business travel, and hungry … The post Uber Infrastructure in 2019: Improving Reliability, (..)
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
Without having network visibility, it’s not possible to improve our reliability, security and capacity posture. Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. 43416 5001 52.213.180.42
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic.
Open Connect Open Connect is Netflix’s content delivery network (CDN). An easy, though imprecise, way of thinking about Netflix infrastructure is that everything that happens before you press Play on your remote control (e.g., video streaming) takes place in the Open Connect network. are you logged in? what plan do you have?
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Because of its adaptability, Prometheus has become an essential tool for observability engineering. Jolly good!
Intro to Istio Observability Using Prometheus Istio service mesh abstracts the network from the application layers using sidecar proxies. You can implement security and advance networking policies to all the communication across your infrastructure using Istio. But another important feature of Istio is observability.
While today’s IT world continues the shift toward treating everything as a service, many organizations need to keep their environments under strict control while managing their infrastructure themselves on-premises. Exceeded throughput levels can be a sign that some changes to the network configuration might be required.
For two decades, Dynatrace NAM—Network Application Monitoring, formerly known as DC RUM—has been successfully monitoring the user experience of our customers’ enterprise applications. SNMP managed the costs of network links well, but not the sources of those costs (i.e., Dynatrace news. Performance has always mattered.
Containers enable developers to package microservices or applications with the libraries, configuration files, and dependencies needed to run on any infrastructure, regardless of the target system environment. This orchestration includes provisioning, scheduling, networking, ensuring availability, and monitoring container lifecycles.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. Dynatrace AWS monitoring gives you an overview of the resources that are used in your AWS infrastructure along with their historical usage. Monitoring your i nfrastructure.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Think of containers as the packaging for microservices that separate the content from its environment – the underlying operating system and infrastructure. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices.
Software performance can be compromised in many ways, including software bugs, cyberattacks, overwhelming demand, backup failures, network issues, and human error. Teams can use this information to optimize infrastructure and application performance, ensuring that systems can handle increased traffic without compromising user experience.
Getting insights into the health and disruptions of your networking or infrastructure is fundamental to enterprise observability. Even for a supported component, delivering logs from applications and infrastructure to DevSecBizOps workflows requires significant manual configuration.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. System Components. References.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. Here are the six steps of a typical ITOA process : Define the data infrastructure strategy. Apache Spark.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content