This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Indeed, chaos engineering is an innovation concerning testing infrastructure resilience these days. Therefore, no one can underestimate the role of stress testing in ensuring that the systems are resilient against unfortunate events and failures.
This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation. This latest integration with Microsoft Sentinel expands our partnership, providing joint customers with a holistic view of their entire cloud environment; from application to infrastructure, data, and security. “As
At the time when I was building the most innovative observability company, security seemed too distant. Configuration and Compliance , adding the configuration layer security to both applications and infrastructure and connecting it to compliance.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
Running workloads on top of Kubernetes is significantly valuable, not just for application teams, but for infrastructure teams as well. At the core of this approach is the Dynatrace AI engine, Davis ®, which automatically delivers an in-depth analysis and precise root cause whenever anomalies arise. More about Kubernetes.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. With higher demand for innovation, IT teams are working diligently to release high-quality software faster.
At Dynatrace, we’ve been exploring the many ways of using GPTs to accelerate our innovation on behalf of our customers and the productivity of our teams. ChatGPT and generative AI: A new world of innovation Software development and delivery are key areas where GPT technology such as ChatGPT shows potential.
On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
In fact, 76% of technology leaders say the dynamic nature of Kubernetes makes it more difficult to maintain visibility of their infrastructure compared with traditional technology stacks. Taking a strategic Kubernetes platform engineering approach Spier noted that keeping Kubernetes simple requires a strategic approach. billion. “We
Site reliability engineering first emerged to address cloud computing’s new performance needs. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. Understanding the platform engineer role DevOps is a constantly evolving discipline.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
AIOps and observability for infrastructure management. This kind of IT automation “ingests data from every layer in the stack — from the infrastructure layer to the application layer and even user experience data,” says Bipin Singh, director of product marketing at Dynatrace. This allows us to manipulate our environment,” he says.
This approach enhances key DORA metrics and enables early detection of failures in the release process, allowing SREs more time for innovation. To enhance reliability, testing the software under these conditions is crucial to prepare for potential issues by leveraging chaos engineering or similar tools. Why reliability?
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
Infrastructure as code is a way to automate infrastructure provisioning and management. In this blog, I explore how Dynatrace has made cloud automation attainable—and repeatable—at scale by embracing the principles of infrastructure as code. Infrastructure-as-code. But how does it work in practice?
More than 90% of enterprises now rely on a hybrid cloud infrastructure to deliver innovative digital services and capture new markets. That’s because cloud platforms offer flexibility and extensibility for an organization’s existing infrastructure. Dynatrace news. Five hybrid cloud platforms to consider.
Taking an end-to-end responsibility for our customers’ critical infrastructure and applications, we are always striving to optimize the performance of our industrialized platform. The post Intility unlocks digital innovations for its customers with Dynatrace appeared first on Dynatrace blog. Faster time to value.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Most backend engineering teams follow a process very similar to what is shown below. If so, we invite you to begin the interview process.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation. SRE drives a “shift left” mindset.
Software should forward innovation and drive better business outcomes. Conversely, an open platform can promote interoperability and innovation. Legacy technologies involve dependencies, customization, and governance that hamper innovation and create inertia. Data supports this need for organizations to flex and modernize.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying software engineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
In today's rapidly evolving technological landscape, developers, engineers, and architects face unprecedented challenges in managing, processing, and deriving value from vast amounts of data.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
Architects, DevOps, and cloud engineers are gradually trying to understand which is better to continue the journey with: the API gateway, or adopt an entirely new service mesh technology?
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
These criteria include operational excellence, security and data privacy, speed to market, and disruptive innovation. The innovation is mutual The Ally Technology Partner Awards are a way for the company to acknowledge its exceptional partners. “We Dynatrace is especially proud to support innovators like Ally Financial.
” He credits this shift to the early days of the DevOps movement when infrastructure was built more as code but was still tied to individual machines. “Kubernetes has become almost like this operating system of applications, where companies build their platform engineering initiatives on top.”
Dynatrace full stack observability for Red Hat OpenShift Dynatrace enhances software quality and operational efficiency, which drives innovation by unifying application, operation, and platform engineering teams on a single platform. Learn more about the new Kubernetes Experience for Platform Engineering.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? This approach provides a few advantages: Low burden on existing systems: Log processing imposes minimal changes to existing infrastructure.
Echoing John Van Siclen’s sentiments from his Perform 2020 keynote, Steve cited Dynatrace customers as the inspiration and driving force for these innovations. “A Highlighting the company’s announcements from Perform 2020, Steve and a team of other Dynatrace product leaders introduced the audience to several of our latest innovations.
In the Magic Quadrant report, Gartner defines APM as, “software that enables the observation of application behavior and its infrastructure dependencies, users, and business key performance indicators (KPIs) throughout the application’s life cycle.” It’s this combination that helps our customers deal with the explosion of observability data.
GKE Autopilot empowers organizations to invest in creating elegant digital experiences for their customers in lieu of expensive infrastructure management. Dynatrace’s collaboration with Google addresses these needs by providing simple, scalable, and innovative data acquisition for comprehensive analysis and troubleshooting.
Today, businesses are racing ever faster to accommodate customer demands and innovate without sacrificing product quality or security. As they increase the speed of product innovation and software development, organizations have an increasing number of applications, microservices and cloud infrastructure to manage.
A unified platform approach to observability and security Dynatrace and its partners offer powerful solutions to complex business resiliency challenges through an observability and security platform that delivers a unified view of applications, infrastructure, and business processes.
Navigate digital infrastructure complexity In today’s rapidly evolving digital environment, organizations face increasing pressure from customers and competitors to deliver faster, more secure innovations. Use case: Digital infrastructure change The problem is not always in the application.
Lambda serverless functions help developers innovate faster, scale easier, and reduce operational overhead, removing the burden of managing underlying infrastructure when updating and deploying code. The latest Amazon Lambda innovation, Lambda SnapStart, has day one support from Dynatrace. What is Lambda?
Modern solutions like Snyk and Dynatrace offer a way to achieve the speed of modern innovation without sacrificing security. This innovative solution combines Snyk Container and Dynatrace observability data to provide comprehensive reporting—highlighting which running containers have undergone Snyk Container scans.
It will let you focus on where you want to be – building and running apps perhaps – while GKE Autopilot ‘self-flies’ the rest of the infrastructure for you. Just as GKE Autopilot is running your Kubernetes infrastructure, by deploying the Dynatrace Operator, the ? GKE Autopilot and beyond.
The growing adoption of innovations like generative AI, based on large-language models (LLMs), will only increase demand for cloud computing. Given the benefits of these innovations, organizations can’t afford to pull back on their efforts to build AI and shift more workloads to the cloud. That’s why we developed Carbon Impact.
Within every industry, organizations are accelerating efforts to modernize IT capabilities that increase agility, reduce complexity, and foster innovation. Docker Swarm First introduced in 2014 by Docker, Docker Swarm is an orchestration engine that popularized the use of containers with developers.
As a leader in cloud infrastructure and platform services , the Google Cloud Platform is fast becoming an integral part of many enterprises’ cloud strategies. Dynatrace provides out-of-the-box distributed tracing for Kubernetes and Google App Engine stacks, as well as full-stack Kubernetes Container Optimized OS support.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































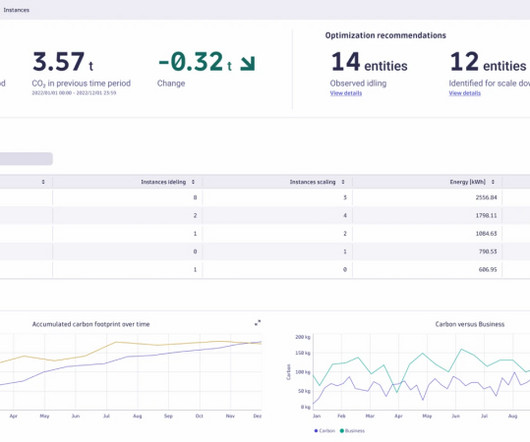








Let's personalize your content