This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. Why Black Friday traffic threatens customer experience.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
Part of the problem is technologies like cloud computing, microservices, and containerization have added layers of complexity into the mix, making it significantly more challenging to monitor and secure applications efficiently. Learn more about how you can consolidate your IT tools and visibility to drive efficiency and enable your teams.
When the SLO status converges to an optimal value of 100%, and there’s substantial traffic (calls/min), BurnRate becomes more relevant for anomaly detection. SLOs must be evaluated at 100%, even when there is currently no traffic. What characterizes a weak SLO? Use the default transformation. Interested in learning more?
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency. 54% reported deploying updates every two hours or less.
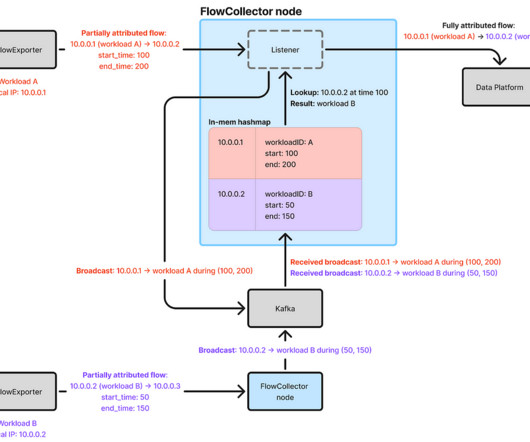
Although more efficient broadcasting implementations exist, the Kafka-based approach is simple and has worked well forus. To optimize flow reporting and minimize cross-regional traffic, a FlowCollector cluster runs in each major region, and FlowExporter agents send flows to their corresponding regional FlowCollector.
Network traffic power calculations rely on static power estimations for both public and private networks. Static assumptions are: Local network traffic uses 0.12 Public network traffic uses 1.0 These estimates are converted using the emission factor for the data center location.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Configuring quorum queues achieves high data safety and reliability in your RabbitMQ setup.
This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient. To detect issues proactively, we need to simulate traffic and predict system behavior in advance. The stakes are even higher when ensuring every title launches flawlessly.
This is done without the need to create custom dashboards and is complemented by efficient analysis capabilities that automatically guide SREs to potential root causes of anomalies, enabling more efficient work and freeing up time for essential workflows.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. This integration will not only optimize performance but also ensure more efficient resource utilization.
Scheduler and controller manager These components are the conductors of your Kubernetes cluster, ensuring that your applications run smoothly and efficiently. When communications aren’t properly encrypted, attackers who gain network access can intercept traffic between components. Common misconfiguration. Real-world impact.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Each of these services addresses specific use cases, offering diverse functionalities to meet the demands of modern applications.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
In this article, we’ll dive deep into the concept of database sharding, a critical technique for scaling databases to handle large volumes of data and high levels of traffic. This section will provide insights into the architecture and strategies to ensure efficient query processing in a sharded environment.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems. Start your free trial today!
HAProxy is one of the cornerstones in complex distributed systems, essential for achieving efficient load balancing and high availability. This open-source software, lauded for its reliability and high performance, is a vital tool in the arsenal of network administrators, adept at managing web traffic across diverse server environments.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
Unnecessary traffic between such data centers can result in wasted resources, unpredictable downtimes, and lost business. By minimizing bandwidth and preventing unrelated traffic between data centers, you can maintain healthy network infrastructure and save on costs. optimizing traffic routing.
Even when the staging environment closely mirrors the production environment, achieving a complete replication of all potential scenarios, such as simulating extremely high traffic volumes to assess software performance, remains challenging. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
Deployment frequency measures both long-term and short-term efficiency. For example, by measuring deployment frequency daily or weekly, you can determine how efficiently your team is responding to process changes. This metric gauges the stability and efficiency of your DevOps processes. Application usage and traffic.
In the dynamic world of microservices architecture, efficient service communication is the linchpin that keeps the system running smoothly. It comprises a suite of capabilities, such as managing traffic, enabling service discovery, enhancing security, ensuring observability, and fortifying resilience.
With its ability to handle large amounts of traffic and complex data, the Apollo router is quickly becoming a popular choice among developers seeking a reliable and efficient routing solution. With this integrated telemetry functionality, the Apollo router provides a streamlined and efficient performance monitoring solution.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Detect and respond to security threats like DDoS attacks or web application attacks by monitoring application traffic and logs.
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. Performances testing helps establish the scalability, stability, and speed of the software application.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. The “scheduler” determines the placement of new containers so compute resources are used most efficiently. In production, containers are easy to replicate. What is Docker? Networking.
The situation quickly settles back into the learned baseline, as shown below: As you can see, efficient monitoring is a matter of balance between quick reaction when necessary and avoiding overreacting to short hiccups. Give your baselining more observation time to avoid false positives. Close issues sooner with shorter event timeouts.
This SLO highlights the importance of a smooth and efficient checkout experience. Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. Thus, an ApDex score of 0.85 means that 85% of requests met that threshold. The Apdex score of 0.85
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Possible scenarios A retail website crashes during a major sale event due to a surge in traffic. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
Like any move, a cloud migration requires a lot of planning and preparation, but it also has the potential to transform the scope, scale, and efficiency of how you deliver value to your customers. This can fundamentally transform how they work, make processes more efficient, and improve the overall customer experience. Here are three.
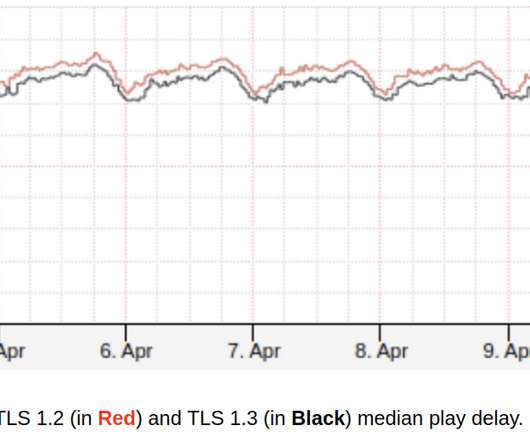
To achieve that, we are efficiently using ABR (adaptive bitrate streaming) for a better playback experience, DRM (Digital Right Management) to protect our service and TLS (Transport Layer Security) to protect customer privacy and to create a safer streaming experience. for streaming traffic. Now we support TLS 1.3 What is TLS?
and thus fall back to less efficient encode families. Since then, we have applied innovations such as shot-based encoding and newer codecs to deploy more efficient encode families. 264/AVC Main profile family still represents a substantial portion of the members viewing hours and an even larger portion of the traffic.
Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency. Improved availability: Caching can help maintain service availability during high-traffic periods or in case of temporary server failures by serving content from the cache.
Kubernetes can be complex, which is why we offer comprehensive training that equips you and your team with the expertise and skills to manage database configurations, implement industry best practices, and carry out efficient backup and recovery procedures.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. It also enhances syslog messages with additional context and optimizes network traffic, improving overall system resilience and security.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
Some of the benefits organizations seek from digital transformation journeys include the following: Increased DevOps automation and efficiency. Digital tools and technologies provide a more efficient way of doing things. Previously, they had 12 tools with different traffic thresholds. Improved customer experience.
Before a new version of the application is deployed, the software is subject to a series of load tests that evaluate capacity and performance under a series of simulated traffic and application demands. These metrics are latency, traffic, errors, and saturation, all of which must be key considerations when curating user experience.
In our Dynatrace Dashboard tutorial, we want to add a chart that shows the bytes in and out per host over time to enhance visibility into network traffic. This approach helps you quickly pinpoint potential problems and ensures efficient monitoring of your infrastructure.
With any cloud technology, managing cost efficiency is critical. One example we often see is manag ing efficiency with cloud application workloads through intent-based capacity planning. This can be increasingly difficult with spontaneous user habits – or other outside variables.
A traffic spike can be another root cause (for example, if a new marketing promotion drives lots of new customer traffic to your site). Davis baselines your traffic levels mainly to identify traffic drops, however it can also be set to create events when traffic is higher than expected.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content