This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
Network traffic power calculations rely on static power estimations for both public and private networks. Static assumptions are: Local network traffic uses 0.12 Public network traffic uses 1.0 Storage calculations assume that one terabyte consumes 1.2 A CPU operating at 100% utilization consumes power equal to its TDP.
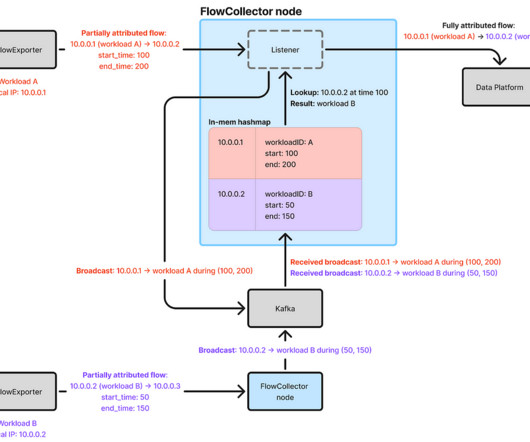
Although more efficient broadcasting implementations exist, the Kafka-based approach is simple and has worked well forus. Because the in-memory state can be quickly rebuilt when a FlowCollector node starts up, no persistent storage is required. With 30 c7i.2xlarge
This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient. To detect issues proactively, we need to simulate traffic and predict system behavior in advance. The stakes are even higher when ensuring every title launches flawlessly.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. This integration will not only optimize performance but also ensure more efficient resource utilization.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency. 54% reported deploying updates every two hours or less.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Configuring quorum queues achieves high data safety and reliability in your RabbitMQ setup.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems. Start your free trial today!
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. It also enhances syslog messages with additional context and optimizes network traffic, improving overall system resilience and security.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
Even when the staging environment closely mirrors the production environment, achieving a complete replication of all potential scenarios, such as simulating extremely high traffic volumes to assess software performance, remains challenging. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
Progressive rollouts, rollbacks, storage orchestration, bin packing, self-healing, cost efficiency, and access to the Cloud Native Computing Foundation (CNCF) ecosystem carry heavy observability challenges. Unlike evictions from resource exhaustion on a node, this event resulted from ephemeral storage limits exceeded on the pod.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. It involves both the collection and storage of logs, as well as aggregation, analysis, and even the long-term storage and destruction of log data.
As a result, organizations are implementing security analytics to manage risk and improve DevSecOps efficiency. For example, an organization might use security analytics tools to monitor user behavior and network traffic. Dehydrated data has been compressed or otherwise altered for storage in a data warehouse. Read now!
Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Cloud storage monitoring. Teams can keep track of storage resources and processes that are provisioned to virtual machines, services, databases, and applications. Cloud-server monitoring.
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. We earned the trust of our engineers by developing empathy for their operational burden and by focusing on providing efficient tracer library integrations in runtime environments.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
This SLO highlights the importance of a smooth and efficient checkout experience. Traffic This SLO measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. Thus, an ApDex score of 0.85 means that 85% of requests met that threshold. The Apdex score of 0.85
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. VPC Flow Logs is a feature that gives you the capability to capture more robust IP traffic data that traverses your VPCs.
1) depicts the migration of traffic from fixed bitrates to DO encodes. 1: Migration of traffic from fixed-ladder encodes to DO encodes. In spite of reaching higher qualities than the fixed ladder, the HDR-DO ladder, on average, occupies only 58% of the storage space compared to fixed-bitrate ladder. The graphic below (Fig.
Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? How much traffic is sent between two processes hosting a certain service? Step 3: Detailed Traffic Dependency Analysis. What’s in your stack?”.
Digital experience monitoring enables companies to respond to issues more efficiently in real time, and, through enrichment with the right business data, understand how end-user experience of their digital products significantly affects business key performance indicators (KPIs). Endpoint monitoring (EM). Endpoints can be physical (i.e.,
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. This talk explores the journey, learnings, and improvements to performance analysis, efficiency, reliability, and security. Wednesday?—?December
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. This separation aims to streamline transaction write logging, improving efficiency and consistency. Who can benefit from DLV? and later v10 versions MySQL: 8.0.28
This SLO example highlights the importance of a smooth and efficient checkout experience. Traffic The traffic SLO example measures the amount of traffic or workload an application receives, either in terms of requests per second or data transfer rate. or above for the checkout process. The Apdex score of 0.85
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
Grail combines the big-data storage of a data warehouse with the analytical flexibility of a data lake. For example, these include verifying app deployments, isolating faults coming from a single IP address, identifying root causes of traffic spikes, or investigating malicious user activity.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. Since doing full table scans in Cassandra is not generally recommended on large tables (due to potential timeouts), our cassandra schema contains several reverse indices that help us query all data efficiently.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. By default, MongoDB provides a snappy block compression method for storage and network communication.
On the other hand, when one is interested only in simple additive metrics like total page views or average price of conversion, it is obvious that raw data can be efficiently summarized, for example, on a daily basis or using simple in-stream counters. A group of several such sketches can be used to process range query. bits per unique value.
This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. Storage is a critical aspect to consider when working with cloud workloads. This opens up possibilities not only difficult but almost impossible to attain conventionally!
s web-based applications often encounter database scaling challenges when faced with growth in users, traffic, and data. Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. The growth of Amazonâ??s
Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model. Thus making it an ideal choice for businesses seeking a successful implementation of their multi-cloud strategy.
Shazam needed to handle an enormous increase in traffic for the duration of the Super Bowl and used DynamoDB as part of their architecture. Indexed Storage costs : We are lowering the price of indexed storage by 75%. Virginia) Region, the price of data storage will drop from $1 per GB per month to $0.25. s prices by 70%.
Storage Encryption for Persistent Messages Protecting sensitive data from unauthorized access is crucial, and encrypting messages at rest safeguards this information should the physical storage be breached. It is essential during firewall configuration to restrict the number of open ports while managing inbound traffic effectively.
This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details. Using AI for Enhanced Cloud Operations The integration of AI in cloud computing is enhancing operational efficiency in several ways.
Chatbots and virtual assistants Chatbots and virtual assistants are becoming more common on websites and web applications as they provide an efficient and convenient way for users to interact with a business. This can help to ensure that the website or web application remains available and responsive, even during periods of high traffic.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content