This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
HAProxy is one of the cornerstones in complex distributed systems, essential for achieving efficient load balancing and high availability. This open-source software, lauded for its reliability and high performance, is a vital tool in the arsenal of network administrators, adept at managing web traffic across diverse server environments.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency. 54% reported deploying updates every two hours or less.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Each of these services addresses specific use cases, offering diverse functionalities to meet the demands of modern applications.
These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. This setup allows for efficient streaming of real-time data through Kafka and the preservation of historical data in Iceberg, providing a comprehensive and flexible data processing and storage solution.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems. Start your free trial today!
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Detect and respond to security threats like DDoS attacks or web application attacks by monitoring application traffic and logs.
Reduced server load: By serving cached content, the load on the server is reduced, allowing it to handle more requests and improving overall scalability. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
A standard Docker container can run anywhere, on a personal computer (for example, PC, Mac, Linux), in the cloud, on local servers, and even on edge devices. This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. What is Docker? Networking. Observability.
Possible scenarios A Distributed Denial of Service (DDoS) attack overwhelms servers with traffic, making a website or service unavailable. Possible scenarios A retail website crashes during a major sale event due to a surge in traffic. These attacks can be orchestrated by hackers, cybercriminals, or even state actors.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Cassandra), ensuring fast and efficient access.
If the primary server encounters issues, operations are smoothly transitioned to a standby server with minimal interruption. Key Takeaways PostgreSQL automatic failover enhances high availability by seamlessly switching to standby servers during primary server failures, minimizing downtime, and maintaining business continuity.
Application servers use connection pools to maintain connections with the databases that they communicate with. A traffic spike can be another root cause (for example, if a new marketing promotion drives lots of new customer traffic to your site). Application server configurations.
Continuous cloud monitoring with automation provides clear visibility into the performance and availability of websites, files, applications, servers, and network resources. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Cloud-server monitoring. Website monitoring.
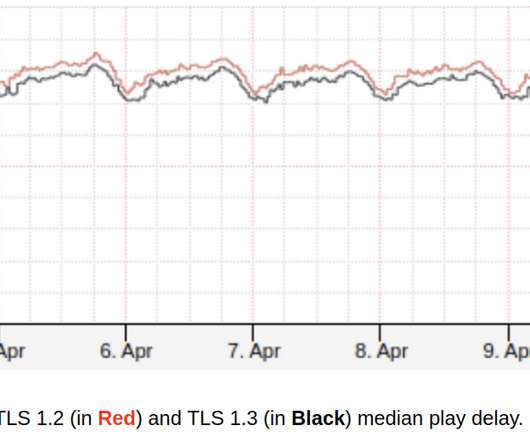
To achieve that, we are efficiently using ABR (adaptive bitrate streaming) for a better playback experience, DRM (Digital Right Management) to protect our service and TLS (Transport Layer Security) to protect customer privacy and to create a safer streaming experience. for streaming traffic. Now we support TLS 1.3 What is TLS?
For example, an attacker could exploit a misconfigured firewall rule to gain access to servers on your network. Scanning the runtime environment of your services can help to identify unusual network traffic patterns. The Dynatrace Application Security module gives you all the benefits of automated vulnerability management at scale.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
For example, a good course of action is knowing which impacted servers run mission-critical services and remediating those first. Together, these technologies enable organizations to maintain real-time visibility and control, swiftly mitigating the impact of incidents and efficiently restoring critical services.
Like any move, a cloud migration requires a lot of planning and preparation, but it also has the potential to transform the scope, scale, and efficiency of how you deliver value to your customers. This can fundamentally transform how they work, make processes more efficient, and improve the overall customer experience. Here are three.
For example, to handle traffic spikes and pay only for what they use. However, serverless applications have unique characteristics that make observability more difficult than in traditional server-based applications. Scale automatically based on the demand and traffic patterns. What are serverless applications?
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. It also enhances syslog messages with additional context and optimizes network traffic, improving overall system resilience and security.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. This evolution in automation, referred to as answer-driven automation, empowers teams to address complex issues in real time, optimize workflows, and enhance overall operational efficiency.
To keep infrastructure and bare metal servers running smoothly, a long list of additional devices are used, such as UPS devices, rack cases that provide their own cooling, power sources, and other measures that are designed to prevent failures. is the key to providing accurate root cause analysis.
Kubernetes can be complex, which is why we offer comprehensive training that equips you and your team with the expertise and skills to manage database configurations, implement industry best practices, and carry out efficient backup and recovery procedures.
Achieving 100 Gbps intrusion prevention on a single server , Zhao et al., Improving the efficiency with which we can coordinate work across a collection of units (see the Universal Scalability Law ). Today’s paper choice is a wonderful example of pushing the state of the art on a single server. OSDI’20.
On Titus , our multi-tenant compute platform, a "noisy neighbor" refers to a container or system service that heavily utilizes the server's resources, causing performance degradation in adjacent containers. These functions ensure that our eBPF program remains safe and efficient while retrieving the cgroup ID from the task struct.
Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency. In large organizations, it’s not uncommon to have hundreds of applications — each with its own specific infrastructure requirements based on architecture, function, traffic, and more.
Impacting Server-Side Requests: Dynatrace allows you to drill into your server-side requests to understand why your business logic is executing slow or fails. Dynatrace provides full page load waterfalls with automated optimization findings for all captured user sessions, and also allows you to drill into server-side PurePaths.
Digital experience monitoring enables companies to respond to issues more efficiently in real time, and, through enrichment with the right business data, understand how end-user experience of their digital products significantly affects business key performance indicators (KPIs). Endpoints can be physical (i.e.,
In today’s data-driven world, businesses across various industry verticals increasingly leverage the Internet of Things (IoT) to drive efficiency and innovation. IoT is transforming how industries operate and make decisions, from agriculture to mining, energy utilities, and traffic management.
That’s particularly true of our GRPC clients and servers, where request cancellations due to timeouts interact with reliability features such as retries, hedging and fallbacks. Each of these errors is a canceled request resulting in a retry so this reduction further reduces overall service traffic by this rate: Errors rates per second.
Until now, the process was cumbersome as it required you to manually create a token for each environment and store it in a secure place (for example, Secret Server or a CI/CD service). Improved cluster resilience for high user traffic volume. Other changes. Once the new cluster is running well, backup must be re-enabled manually.
Azure Traffic Manager. The Azure MySQL dashboard serves as a comprehensive overview of your MySQL servers and database services. Azure Front Door enables you to define, manage, and monitor the global routing for your web traffic by optimizing for best performance and quick global failover for high availability. Azure Batch.
Therefore, it was unsurprising to see a huge spike in traffic for Family Visa enrollment via Metrash. Let’s start with the spike in load: The high demand on family visa enrollments resulted in a huge traffic and CPU spike. Perform an audit on default settings of the application server.
As a MySQL database administrator, keeping a close eye on the performance of your MySQL server is crucial to ensure optimal database operations. However, simply deploying a monitoring tool is not enough; you need to know which Key Performance Indicators (KPIs) to monitor to gain insights into your MySQL server’s health and performance.
Content is placed on the network of servers in the Open Connect CDN as close to the end user as possible, improving the streaming experience for our customers and reducing costs for both Netflix and our Internet Service Provider (ISP) partners. takes place in Amazon Web Services (AWS), whereas everything that happens afterwards (i.e.,
More efficient SSL/TLS handling for OneAgent traffic. By default, all OneAgent traffic is now routed to your embedded ActiveGate via NGINX on port 443. For OneAgent traffic, the default port has been set to 443 for new clusters only so as to ensure backward compatibility. Additional audit logs for Nodekeeper.
Logs can include information about user activities, system events, network traffic, and other various activities that can help to detect and respond to critical security incidents. Efficient and effective log audit and forensics practices can require specialized understanding of cloud environments, applications, and log formats.
As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. In the Efficiency space, our data teams focus on transparency and optimization.
Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? How much traffic is sent between two processes hosting a certain service? Step 3: Detailed Traffic Dependency Analysis. What’s in your stack?”.
Learn how RabbitMQ can boost your system’s efficiency and reliability in these practical scenarios. Understanding RabbitMQ as a Message Broker RabbitMQ is a powerful message broker that enables applications to communicate by efficiently directing messages from producers to their intended consumers.
This was a custom built, 3-step pipeline: Capture the production traffic for the desired path(s) Replay the traffic against the two services in the TEST environment Compare and assert for differences It was a self-contained flow that, by design, captured entire requests, and not just the one path we requested.
Many of our customers also run their.NET, ASP.NET,NET Core, SQL Server, CRM, SharePoint … applications on AWS and have reached out to us in the past to ask about best practices around optimizing these workloads in order to run more efficiently and more cost effective. Are they receiving traffic? #3:
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content