This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. Stay tuned for more exciting updates as we continue to expand our collaboration with AWS and help our customers unlock new possibilities in the cloud. group of companies.
It facilitates the distribution of these learnings to other models, either through shared model weights for fine tuning or directly through embeddings. In NLP, the trend is moving away from numerous small, specialized models towards a single, large language model that can perform a variety of tasks either directly or with minimal fine-tuning.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. This decoupling simplifies system architecture and supports scalability in distributed environments. This allows Kafka clusters to handle high-throughput workloads efficiently.
We kick off with a few topics focused on how were empowering Netflix to efficiently produce and effectively deliver high quality, actionable analytic insights across the company. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient. The complexity of these operational demands underscored the urgent need for a scalable solution. Stay tuned for a closer look at the innovation behind thescenes!
This growth was spurred by mobile ecosystems with Android and iOS operating systems, where ARM has a unique advantage in energy efficiency while offering high performance. Energy efficiency and carbon footprint outshine x86 architectures The first clear benefit of ARM in the enterprise IT landscape is energy efficiency.
This solution offers both maximum efficiency and adherence for the toughest privacy or compliance demands. Stay tuned for more awesome Dynatrace Kubernetes announcements throughout the year. The post Flexible, scalable, self-service Kubernetes native observability now in General Availability appeared first on Dynatrace blog.
In this article, we explain why you should pay attention to when building a scalable application. What Is Application Scalability? Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM).
Optimizing Trino to make it faster can help organizations achieve quicker insights and better user experiences, as well as cut costs and improve infrastructure efficiency and scalability. In this article, we will show you how to tune Trino by helping you identify performance bottlenecks and provide tuning tips that you can practice.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
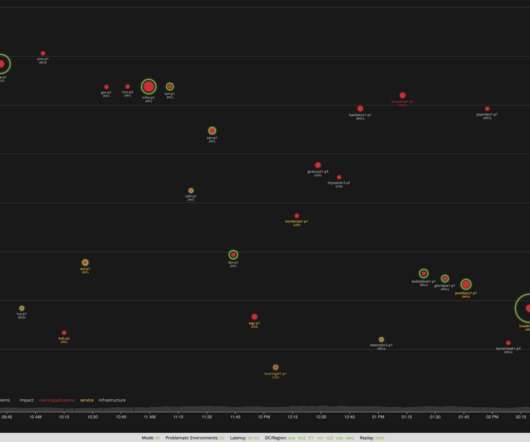
The Insight TriadAPI To efficiently understand the health of a title and triage issues quickly, all implementations of the observability endpoint must answer: is the title eligible for this phase of promotion, if notwhy is it not eligible, and what can be done to fix any problems. The request schema for the observability endpoint.
Rising consumer expectations for transparency and control over their data, combined with increasing data volumes, contribute to the importance of swift and efficient management of privacy rights requests. How can this services administrator meet this request in a quick, compliant, and efficient way?
Without an efficient data retention strategy, this approach may struggle to scale effectively. Rollup Pipeline: Each Counter-Rollup server operates a rollup pipeline to efficiently aggregate counts across millions of counters. In the following sections, we will share key details on how efficient aggregations are achieved.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. From the Kafka Streams community, one of the configurations mostly tuned in production is adding standby replicas. Recovery time of the latency p90.
Summary Providing network insight into the cloud network infrastructure using eBPF flow logs at scale is made possible with eBPF and a highly scalable and efficient flow collection pipeline. After several iterations of the architecture and some tuning, the solution has proven to be able to scale.
At AWS, we continue to strive to enable builders to build cutting-edge technologies faster in a secure, reliable, and scalable fashion. While building Amazon SageMaker and applying it for large-scale machine learning problems, we realized that scalability is one of the key aspects that we need to focus on. Factorization Machines.
The Key-Value Abstraction offers a flexible, scalable solution for storing and accessing structured key-value data, while the Data Gateway Platform provides essential infrastructure for protecting, configuring, and deploying the data tier. Those use cases are well served by the Netflix Atlas telemetry system.
In addition, pySpark applications can be tuned to optimize performance and achieve better execution time, scalability, and resource utilization. In this article, we will discuss some tips and techniques for tuning PySpark applications. This can significantly reduce network overhead and improve performance.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. ” A data warehouse, on the other hand, is an efficient and fast option for querying data.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. This model supports both simple and complex data models, balancing flexibility and efficiency. Cassandra), ensuring fast and efficient access.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. For a deeper look into how to gain end-to-end observability into Kubernetes environments, tune into the on-demand webinar Harness the Power of Kubernetes Observability. What is Docker? Networking.
More cost-efficiency through the incorporation of consumption and usage data. Drive developer experience through consistency and scalability. The Dynatrace Environment API v2 delivers a consistent developer experience and scalability by providing a set of common features for all endpoints. Please stay tuned for more details.
Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. What is Bulldozer Bulldozer is a self-serve data platform that moves data efficiently from data warehouse tables to key-value stores in batches. Figure 1 shows how we use Bulldozer to move data at Netflix.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
However, scaling up software development requires more tools along the software product lifecycle, which must be configured promptly and efficiently. Efficient environment configuration at scale One of software engineers’ most significant challenges is managing the numerous tools and technologies required for the software product lifecycle.
To handle errors efficiently, Netflix developed a rule-based classifier for error classification called “Pensive.” This talk will delve into the creative solutions Netflix deploys to manage this high-volume, real-time data requirement while balancing scalability and cost. Until next time!
To do that, we need an easy and efficient API access to all of our Dynatrace Environments, without having to create and maintain API access tokens of individual tenants. The Fan-Out/Fan-In pattern is nowadays found when building serverless functions for high scalability. Consolidating the APIs. I found a good read here.
The Dynatrace Software Intelligence Platform supports you on your way to the enterprise cloud with deep insights into containerized, scalable microservices on cutting-edge technologies like Red Hat OpenShift or Kubernetes. These capabilities allow you to build efficient and robust business services on the mainframe. Stay tuned!
Our goal is to make this process simple, scalable, and enjoyable. Our enterprise-grade platform takes care of scalability and manageability including load balancing, routing, and central management. So please stay tuned for updates. .
Critical success factors – velocity, resilience, and scalability. Broad-scale observability focused on using AI safely drives shorter release cycles, faster delivery, efficiency at scale, tighter collaboration, and higher service levels, resulting in seamless customer experiences.
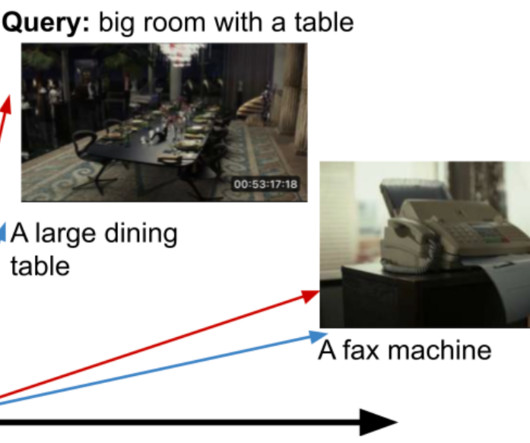
In order to train the model on internal training data (video clips with aligned text descriptions), we implemented a scalable version on Ray Train and switched to a more performant video decoding library. We also found that extending contrastive learning to videos and text provided a substantial improvement over frame-level models.
We earned the trust of our engineers by developing empathy for their operational burden and by focusing on providing efficient tracer library integrations in runtime environments. An additional implication of a lenient sampling policy is the need for scalable stream processing and storage infrastructure fleets to handle increased data volume.
As Big data and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Motivation Scalability and usability are essential to enable large-scale workflows and support a wide range of use cases.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. This evolution in automation, referred to as answer-driven automation, empowers teams to address complex issues in real time, optimize workflows, and enhance overall operational efficiency.
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
Although model-based anomaly detection approaches are more scalable and suitable for real-time analysis, they highly rely on the availability of (often labeled) context-specific data. On the other hand, in model-based anomaly detection approaches, models are built and used to detect anomalous incidents in a fairly automated manner.
The results will help database administrators and decision-makers choose the right platform for their performance, scalability, and cost-efficiency needs. Introduction Purpose and Scope Cloud-hosted PostgreSQL solutions are increasingly popular among organizations seeking scalable, high-performance databases.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. The main advantages of distributed SQL databases are scalability and continuous operation.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
For more efficient schema management and evolution, the platform will automatically infer the output schema based on the fields selected by the SQL query. This makes the query service lightweight, scalable, and execution agnostic. Stay tuned for more updates! We plan on gradually expanding the supported capabilities over time.
Moving away from the use of dedicated instances that were constrained in quantity, we tapped into Netflix’s internal trough created due to autoscaling microservices, leading to significant improvements in computation elasticity as well as resource utilization efficiency. depending on the use case.
We knew that given our scale, we needed to rely heavily on automations and that we needed to build our solutions using battle tested scalable infrastructure. Snare Finding Lifecycle Overview Snare was built from the ground up to be scalable to manage Netflix’s massive scale.
It inherits the automation, AI, scalability, and enterprise-grade robustness of the Dynatrace platform. With new RASP capabilities of the Dynatrace OneAgent, the same trusted approach extends the Dynatrace platform to application security: automatic, intelligent, highly scalable. Stay tuned – this is only the start.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Please stay tuned! To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content