This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenTelemetry is enhancing GenAI observability : By defining semantic conventions for GenAI and implementing Python-based instrumentation for OpenAI, OpenTel is moving towards addressing GenAI monitoring and performance tuning needs. Second, it enables efficient and effective correlation and comparison of data between various sources.
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs).
It facilitates the distribution of these learnings to other models, either through shared model weights for fine tuning or directly through embeddings. The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs).
CPU isolation and efficient system management are critical for any application which requires low-latency and high-performance computing. To achieve this level of performance, such systems require dedicated CPU cores that are free from interruptions by other processes, together with wider system tuning.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
In this episode, Dimitris discusses the many different tools and processes they use. From development tools to collaboration, alerting, and monitoring tools, Dimitris explains how he manages to create a successful—and cost-efficient—environment. It also helps reduce the agency’s carbon footprint.
This growth was spurred by mobile ecosystems with Android and iOS operating systems, where ARM has a unique advantage in energy efficiency while offering high performance. Energy efficiency and carbon footprint outshine x86 architectures The first clear benefit of ARM in the enterprise IT landscape is energy efficiency.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. REST APIs, authentication, databases, email, and video processing all have a home on serverless platforms. The Serverless Process.
In addition to service-level monitoring, certain services within the OpenTelemetry demo application expose process-level metrics, such as CPU and memory consumption, number of threads, or heap size for services written in different languages. So, stay tuned for more enhancements and features. This is just the beginning.
Introducing sufficient jitter to the flush process can further reduce contention. By creating multiple topic partitions and hashing the counter key to a specific partition, we ensure that the same set of counters are processed by the same set of consumers. This process can also be used to track the provenance of increments.
As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. The request schema for the observability endpoint.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. This allows developers to easily access and process the file without handling the upload mechanics directly. Complete mitigation is only guaranteed in Struts version 7.0.0
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Proper setup involves creating a configuration process that accounts for hostname changes, which could prevent nodes from rejoining the cluster.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. Adding AIOps to automation processes makes the volume of data that applications and multicloud environments generate much less overwhelming.
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. DevOps has gained ground in recent years as a way to combine key operational principles with development cycles, recognizing that these two processes must coexist.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Cassandra), ensuring fast and efficient access.
The shift-left approach aims to ensure bugs and other issues are discovered and addressed early in the development process, leading to improved software quality and lower costs associated with late-stage troubleshooting. Why the sudden change in tune? Instead, it’s now prelevant throughout the entire lifecycle. Well, it’s simple.
Application scalability is the potential of an application to grow in time, being able to efficiently handle more and more requests per minute (RPM). It’s not just a simple tweak you can turn on/off; it’s a long-time process that touches almost every single item in your stack, including both hardware and software sides of the system.
In an effort to effectively and efficiently produce this content we are looking to improve and automate many areas of the production process. Production: Enable content creation from script to screen that optimizes the production process for efficiency and transparency.
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. In this way, no human intervention is required in the remediation process. Multi-objective optimizations.
Berkeley Packet Filter (BPF) is an in-kernel execution engine that processes a virtual instruction set, and has been extended as eBPF for providing a safe way to extend kernel functionality. After several iterations of the architecture and some tuning, the solution has proven to be able to scale. What is BPF?
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as data warehouse tables in AWS S3.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. The OpenTelemetry Protocol (OTLP) plays a critical role in this framework by standardizing how systems format and transport telemetry data, ensuring that data is interoperable and transmitted efficiently.
Dynatrace Grail™ is a data lakehouse optimized for high performance, automated data collection and processing, and queries of petabytes of data in real time. Another consideration is compliance with end-user privacy rights to delete personal data processed about them in line with data protection laws like GDPR and CCPA.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. ” A data warehouse, on the other hand, is an efficient and fast option for querying data.
Operational simplicity Service owners often reach out to us with questions about excessive pause times and for help with tuning. We have several frameworks that periodically refresh large amounts of on-heap data to avoid external service calls for efficiency. No explicit tuning has been required to achieve these results.
Having end-to-end visibility across the entire IT environment and validating our findings with customers and partners, we identified four key pain points DORA surfaces and how we think Dynatrace helps turn them into opportunities to innovate while increasing security, resiliency, and efficiency.
To stay tuned, keep an eye on our release notes. Remediation tracking now enables you to view the risk assessment for the process groups affected by a vulnerability. Reintroduced a limit of 100,000 process group instances (last 72h) running on hosts presented on the “Deployment status” page for OneAgents. (APM-370529).
Tracking changes to automated processes, including auditing impacts to the system, and reverting to the previous environment states seamlessly. The ultimate goal of each of these reviews is to identify gaps, quantify risk, and develop recommendations for improving the team, processes, and architecture with each of the five pillars.
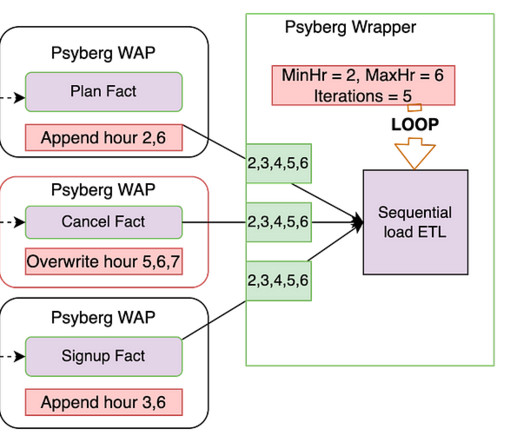
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful Data Processing. We’ll return to the sample customer lifecycle: Processing Requirement : Keep track of the end-of-hour state of accounts, e.g., Active/Upgraded/Downgraded/Canceled.
You don’t really gain the efficiencies or the objectives that you need to be [gaining].” Johnson also shared how his team is using AI to automate certain talent management processes, such as expediting applicant-job matching and aligning training and certification offerings with workforce skill gaps. Download now!
I wanted to understand how I could tune Dynatrace’s problem detection, but to do that I needed to understand the situation first. This is required for understanding how I intend to improve the efficiency of (manual) alert ticket handling. With R (or RStudio) you can efficiently perform analysis on large data sets.
Communicating security insights efficiently across teams in your organization isn’t easy Security management is a complex and challenging task; effectively communicating security insights is even more so. Sample dashboard Next, you want to prepare an efficient plan for remediation.
Profile-Guided Optimization (PGO) stands as a potent technique capable of substantially enhancing the efficiency of your Java programs. By harnessing runtime profiling data, PGO empowers developers to fine-tune their code and apply optimizations that align with their application's real-world usage patterns.
Apache Spark is a powerful open-source distributed computing framework that provides a variety of APIs to support big data processing. In addition, pySpark applications can be tuned to optimize performance and achieve better execution time, scalability, and resource utilization.
Logs can include data about user inputs, system processes, and hardware states. Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded. Log analytics is the process of evaluating and interpreting log data so teams can quickly detect and resolve issues.
Getting the problem status of all environments has to be efficient. Websockets allows efficient data push via multicast to browsers and D3.js Stay tuned for my next part of this series where I will cover another visualization and how it helped me optimize the Dynatrace Anomaly Detection settings and our operations processes!
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content