This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Adopting AI to enhance efficiency and boost productivity is critical in a time of exploding data, cloud complexities, and disparate technologies. The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale.
Today, we’re excited to present the Distributed Counter Abstraction. In this context, they refer to a count very close to accurate, presented with minimal delays. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. This integration will not only optimize performance but also ensure more efficient resource utilization.
This leads to a more efficient and streamlined experience for users. Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult. Challenges with running Hyper-V Working with Hyper-V can come with several challenges.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems. JSON_QUERY extracts JSON fragments based on query conditions.
This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient. They allow us to verify whether titles are presented as intended and investigate any discrepancies. The stakes are even higher when ensuring every title launches flawlessly.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
The Insight TriadAPI To efficiently understand the health of a title and triage issues quickly, all implementations of the observability endpoint must answer: is the title eligible for this phase of promotion, if notwhy is it not eligible, and what can be done to fix any problems. The request schema for the observability endpoint.
At first, data tiering was a tactic used by storage systems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Even though they are quite costly, SSDs and flash can be categorized as high-performance storage classes.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
I wanted to present as much information as possible. Before we dive into the technical implementation, let me explain the visual concept of this “Global Status Page”: Another requirement for this status page was that it has to be lightweight, with no data storage at all. Real-time problem visualization of lots of environments.
But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. In most data storage models, indexing engines enable faster access to query logs. But indexing requires schema management and additional storage to be effective, which adds cost and overhead.
We have been leveraging machine learning (ML) models to personalize artwork and to help our creatives create promotional content efficiently. We will then present a case study of using these components in order to optimize, scale, and solidify an existing pipeline.
Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSONB supports indexing the JSON data, and is very efficient at parsing and querying the JSON data. JSONB storage results in a larger storage footprint. It is a decomposed binary format to store JSON.
At the same time, log analytics can present challenges as data volumes explode, particularly in traditional environments that lack end-to-end observability solutions. Cold storage and rehydration. Cold storage and rehydration. Data that organizations may need to access only once a quarter or year can reside in cold storage.
At the same time, log analytics can present challenges as data volumes explode, particularly in traditional environments that lack end-to-end observability solutions. Cold storage and rehydration. Cold storage and rehydration. Data that organizations may need to access only once a quarter or year can reside in cold storage.
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. Cloud storage monitoring. Teams can keep track of storage resources and processes that are provisioned to virtual machines, services, databases, and applications.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) But the ephemeral storage service for intermediate data is not based on S3.
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. Sample latency analysis Edgar should reduce burden, not add to it Presenting all of this data in one interface reduces the footwork of an engineer to uncover each source.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. These practices can be a boon to infrastructure management, but GitOps presents challenges.
If a more granular rule is present on the host level, that rule will precede any blanket rule on, for example, the tenant level. This allows you to create flexible and powerful log storage configurations on any level by utilizing the unique autodiscovery capabilities of Dynatrace OneAgent or a custom setup. Host group.
Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. For how our machine learning recommendation systems leverage our key-value stores, please see more details on this presentation. As most key-value storage engines support efficiently deleting a namespace (e.g.
In the keynote by Christina Yakomin and Steve Prazenica from Vanguard, the presenters recounted their journey from a monolith with alert-based incident reporting and no positive health signals to an observable microservice architecture. Trace-based sampling can help you save storage costs. We second that.
Azure Data Lake Storage Gen1. The other perspective that’s presented on the Azure Automation dashboard is the state of your deployment runs. Azure Data Factory is a hybrid data integration service that enables you to quickly and efficiently create automated data pipelines—without writing any code. Azure Logic Apps.
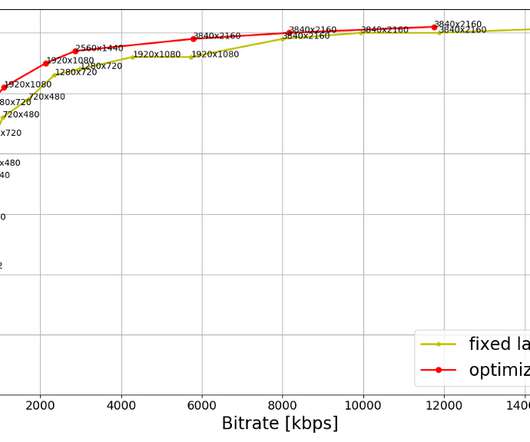
We present two sets. On the other hand, the optimized ladder presents a sharper increase in quality with increasing bitrate. In spite of reaching higher qualities than the fixed ladder, the HDR-DO ladder, on average, occupies only 58% of the storage space compared to fixed-bitrate ladder. The first set (Fig.
This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs. Automate cloud operations and trigger remediation workflow to enhance efficiency. What is AWS Transit Gateway?
In this blog post, we present benefits of applying the above-mentioned optimizations to standard dynamic range (SDR) 10-bit and 4K streams (some titles are also HFR). Mbps, is for a 4K animation title episode which can be very efficiently encoded. The 8-bit stream profiles go up to 1080p resolution.
Data Overload and Storage Limitations As IoT and especially industrial IoT -based devices proliferate, the volume of data generated at the edge has skyrocketed. Managing and storing this data locally presents logistical and cost challenges, particularly for industries like manufacturing, healthcare, and autonomous vehicles.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. It should be noted that not all of the techniques presented are universally applicable, as each migration presents its own unique set of circumstances.
With Amazon Web Services, the main sources from which to ingest logs—Simple Storage Service, or S3, and CloudWatch —come with an additional cost. Log Viewer enables users to present log data in a filterable, easy-to-use table and to browse log data within a certain time frame using detected aspects of the log content.
” But, he continues, ” Today’s environments present a completely different picture. By doing so, they can improve efficiency, reduce costs, and deliver better customer experiences. To stay ahead of the curve, organizations should focus on strategic, proactive innovation and optimization.
For nonurgent messages, texting is a more efficient approach. Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them. For all its virtues, message queuing presents some challenges from an observability perspective.
For nonurgent messages, texting is a more efficient approach. Consumers store messages in a queue — usually in a buffer or on a storage medium — until they can process and delete them. For all its virtues, message queuing presents some challenges from an observability perspective.
Grail handles data storage, data management, and processes data at massive speed, scale, and cost efficiency,” Singh said. The hypermodal AI engine shows what’s happening in a system down to the data coming in, while presenting the information in context. “It’s
Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. These systems are crucial for handling large volumes of data efficiently, enabling businesses and applications to perform complex queries, maintain data integrity, and ensure security.
A bloom filter is a space-efficient way of storing information about a list of keys. If all the bits are “1”, the value may be present. LSM storage engines like MyRocks are very different from the more common B-Tree-based storage engines like InnoDB. At its base, there is a bitmap and a hash function.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. When this data block is read, it decompresses it in memory and presents it to the incoming request.
4:45pm-5:45pm NFX 209 File system as a service at Netflix Kishore Kasi , Senior Software Engineer Abstract : As Netflix grows in original content creation, its need for storage is also increasing at a rapid pace. This talk explores the journey, learnings, and improvements to performance analysis, efficiency, reliability, and security.
Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model. Challenges of Multi-Cloud Although multi-cloud has its benefits, it also presents some obstacles.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. Storage is a critical aspect to consider when working with cloud workloads. This opens up possibilities not only difficult but almost impossible to attain conventionally!
Since that presentation, Pushy has grown in both size and scope, and this article will be discussing the investments we’ve made to evolve Pushy for the next generation of features. With these clear benefits, we continued to build out this functionality for more devices, enabling the same efficiency wins.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content