This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 However, when we captured packets on the ZeroMQ socket while reproducing the issue, we didn’t observe heavy traffic on this socket that could cause such blocking. Meanwhile, traffic from other ports, such as port 22 for SSH, remained unaffected.
Before a new version of the application is deployed, the software is subject to a series of load tests that evaluate capacity and performance under a series of simulated traffic and application demands. These metrics are latency, traffic, errors, and saturation, all of which must be key considerations when curating user experience.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
Continuous Instrumentation of the Linux Scheduler To ensure the reliability of our workloads that depend on low latency responses, we instrumented the run queue latency for each container, which measures the time processes spend in the scheduling queue before being dispatched to the CPU. For this purpose, we chose the eBPF ring buffer.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. This model supports both simple and complex data models, balancing flexibility and efficiency.
Benefits of Caching Improved performance: Caching eliminates the need to retrieve data from the original source every time, resulting in faster response times and reduced latency. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
Reduced tail latencies In both our GRPC and DGS Framework services, GC pauses are a significant source of tail latencies. Each of these errors is a canceled request resulting in a retry so this reduction further reduces overall service traffic by this rate: Errors rates per second.
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. Edgar captures 100% of interesting traces , as opposed to sampling a small fixed percentage of traffic. by Elizabeth Carretto Everyone loves Unsolved Mysteries.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
Like any move, a cloud migration requires a lot of planning and preparation, but it also has the potential to transform the scope, scale, and efficiency of how you deliver value to your customers. This can fundamentally transform how they work, make processes more efficient, and improve the overall customer experience. Here are three.
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. Being able to canary a new route let us verify latency and error rates were within acceptable limits. Replay Testing Enter replay testing.
Note : you might hear the term latency used instead of response time. Both latency and response time are critical to ensure reliability. Latency typically refers to the time it takes for a single request to travel from its source to its destination. Latency primarily focuses on the time spent in transit.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
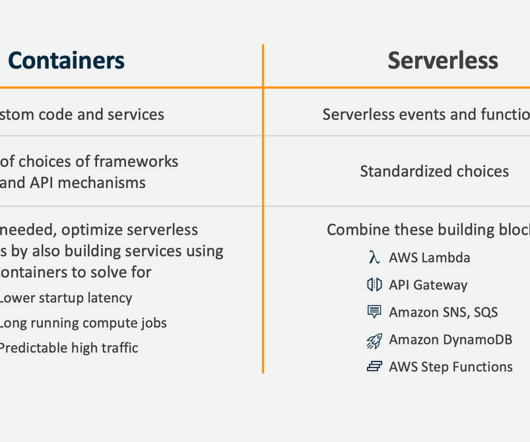
For example, to handle traffic spikes and pay only for what they use. Scale automatically based on the demand and traffic patterns. Higher latency and cold start issues due to the initialization time of the functions. The elasticity of serverless services helps organizations scale as needed.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. million impression events globally every second, with each event approximately 1.2KB in size.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? To detect issues proactively, we need to simulate traffic and predict system behavior in advance.
However, scaling up software development requires more tools along the software product lifecycle, which must be configured promptly and efficiently. Efficient environment configuration at scale One of software engineers’ most significant challenges is managing the numerous tools and technologies required for the software product lifecycle.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. This evolution in automation, referred to as answer-driven automation, empowers teams to address complex issues in real time, optimize workflows, and enhance overall operational efficiency.
Azure Traffic Manager. Azure Front Door enables you to define, manage, and monitor the global routing for your web traffic by optimizing for best performance and quick global failover for high availability. With Azure Batch, you can run large-scale parallel and high-performance computing batch jobs efficiently in Azure.
Kubernetes can be complex, which is why we offer comprehensive training that equips you and your team with the expertise and skills to manage database configurations, implement industry best practices, and carry out efficient backup and recovery procedures.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. However, having a scalable stream processing platform doesn’t help much if you can’t store data in a cost efficient manner.
Digital experience monitoring enables companies to respond to issues more efficiently in real time, and, through enrichment with the right business data, understand how end-user experience of their digital products significantly affects business key performance indicators (KPIs).
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. This talk explores the journey, learnings, and improvements to performance analysis, efficiency, reliability, and security. Wednesday?—?December
Ideally, a TiDB cluster should always be efficient and problem-free. For external reasons, application traffic may surge and increase the pressure on the cluster. For external reasons, application traffic may surge and increase the pressure on the cluster. However, reality is often unsatisfactory.
Then they tried to scale it to cope with high traffic and discovered that some of the state transitions in their step functions were too frequent, and they had some overly chatty calls between AWS lambda functions and S3. They state in the blog that this was quick to build, which is the point.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. It’s like a well-maintained highway where you can cruise without any traffic jams.
Learn how RabbitMQ can boost your system’s efficiency and reliability in these practical scenarios. Understanding RabbitMQ as a Message Broker RabbitMQ is a powerful message broker that enables applications to communicate by efficiently directing messages from producers to their intended consumers.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.
s web-based applications often encounter database scaling challenges when faced with growth in users, traffic, and data. Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. Consistency. SimpleDBâ??s
Resource consumption & traffic analysis. What is the network traffic going to be between services we migrate and those that have to stay in the current data center? How much traffic is sent between two processes hosting a certain service? Step 3: Detailed Traffic Dependency Analysis. What’s in your stack?”.
In this case, we have a quite well-defined scenario that can resemble the image below: In this scenario, the proxies must sit inside Pods, balancing the incoming traffic from the Service LoadBalancer connecting with the active data nodes. In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. There is a system that monitors traffic and counts unique visitors for different criteria (visited site, geography, etc.) A group of several such sketches can be used to process range query. bits per unique value.
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. Most of the business views created on top of the Iceberg tables can tolerate a few minutes of latency. The audits check for equality (i.e.
Under the hood, Titus is powered by Kubernetes , but it provides a thick layer of enhancements over off-the-shelf Kubernetes, to make it more observable , secure , scalable , and cost-efficient. In other cases, it is more convenient to share the results via a low-latency API.
Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
This enables us to use our scale to increase throughput and reduce latencies. Here, based on the video length, the throughput and latency requirements, available scale etc., Video quality has matured in Cosmos and we are invested in making VQS more flexible and efficient. VQS is called using the measureQuality endpoint.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup. Memcached shines in scenarios where a simple, fast, and efficient caching solution is required without data persistence. Memory Efficiency Compared When it comes to memory efficiency, Redis and Memcached have different strengths.
This separation aims to streamline transaction write logging, improving efficiency and consistency. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. Who can benefit from DLV?
The AWS GovCloud (US-East) Region is located in the eastern part of the United States, providing customers with a second isolated Region in which to run mission-critical workloads with lower latency and high availability. US International Traffic in Arms Regulations (ITAR).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content