This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries. This extra network overhead will easily result in increased latency compared to a single-node architecture where data access is straightforward.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
SVT-AV1: open-source AV1 encoder and decoder by Andrey Norkin , Joel Sole , Mariana Afonso , Kyle Swanson, Agata Opalach , Anush Moorthy , Anne Aaron SVT-AV1 is an open-source AV1 codec implementation hosted on GitHub [link] under a BSD + patent license.
This high level of abstraction is provided by industry-grade, opensource stream processing frameworks such as Kafka Streams , Apache Flink , and Spark Structured Streaming. Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume.
OpenTelemetry is an opensource observability project that encompasses a set of APIs, libraries, agents, and instrumentation standards. Traces are used for performance analysis, latency optimization, and root cause analysis. Capture critical performance indicators such as request latency, error rates, and resource usage.
Continuous Instrumentation of the Linux Scheduler To ensure the reliability of our workloads that depend on low latency responses, we instrumented the run queue latency for each container, which measures the time processes spend in the scheduling queue before being dispatched to the CPU. For this purpose, we chose the eBPF ring buffer.
In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
MySQL is the all-time number one opensource database in the world, and a staple in RDBMS space. Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. Read-Intensive Latency Benchmark. Balanced Workload Latency Benchmark.
The 2014 launch of AWS Lambda marked a milestone in how organizations use cloud services to deliver their applications more efficiently, by running functions at the edge of the cloud without the cost and operational overhead of on-premises servers. AWS continues to improve how it handles latency issues. Dynatrace news.
To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows. This talk explores the journey, learnings, and improvements to performance analysis, efficiency, reliability, and security.
Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Observability can identify the baseline user experience and allow teams to improve it by optimizing page load times or reducing latency. Why full-stack observability matters.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an opensource container orchestration system for automating software deployment, scaling, and management. You can ask for the best configuration to reduce latency or improve the user experience.”
At its core, Kubernetes (often abbreviated as K8s) is an opensource tool that automates the deployment, scaling, and management of containerized applications. This makes it much easier for organizations to transition to opensource solutions, reduce costs, and avoid vendor lock-in.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
With these clear benefits, we continued to build out this functionality for more devices, enabling the same efficiency wins. It was very efficient, but it had a set job size, requiring manual intervention if we wanted to horizontally scale it, and it required manual intervention when rolling out a new version.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. However, having a scalable stream processing platform doesn’t help much if you can’t store data in a cost efficient manner.
Anna is not only incredibly fast, it’s incredibly efficient and elastic too: an autoscaling, multi-tier, selectively-replicating cloud service. The issue is that Anna is now orders of magnitude more efficient than competing systems, in addition to being orders of magnitude faster. What's changed ? Related Articles.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an opensource machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
TiDB is an open-source, distributed SQL database that supports Hybrid Transactional/Analytical Processing (HTAP) workloads. Ideally, a TiDB cluster should always be efficient and problem-free. It should be stable, load-balanced, and have a reliable rate of queries per second (QPS).
It enables you to use popular open-source frameworks such as Hadoop, Spark, and Kafka in Azure cloud environments. With our brand new Azure Front Door page, you get immediate insights into the number of served client requests, latency, and back-end health, so you always have a clear picture of the metrics that really matter.
This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked. As you can see, the latency remains relatively jitter-free despite large fluctuations in the cluster size. At first, the team looked to a few open-source solutions (e.g.,
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities¹ and processes of a business domain. Operational Reporting Pipeline Example Iceberg Sink Apache Iceberg is an opensource table format for huge analytics datasets.
As the amount of data grows, the need for efficient data compression becomes increasingly important to save storage space, reduce I/O overhead, and improve query performance. Snappy compression is designed to be fast and efficient regarding memory usage, making it a good fit for MongoDB workloads. provides higher compression rates.
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among opensource options for effectively monitoring MySQL performance. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution. Hint Hint, ProxySQL helps.
Redis Revealed: An Overview Redis, a renowned open-source, in-memory remote dictionary server, stands out for its diverse data structures and advanced features. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup. Memcached’s primary strength lies in its simplicity.
We’re excited to let you know that we have an OpenSource track at re:Invent this year! Brendan Gregg tours BPF tracing, with opensource tools & examples for EC2 instance analysis. OPN304 Learnings from migrating a service from JDK 8 to JDK 11 AWS Lambda improved latency by migrating to JDK 11 with Amazon Corretto.
We’re excited to let you know that we have an OpenSource track at re:Invent this year! Brendan Gregg tours BPF tracing, with opensource tools & examples for EC2 instance analysis. OPN304 Learnings from migrating a service from JDK 8 to JDK 11 AWS Lambda improved latency by migrating to JDK 11 with Amazon Corretto.
Learn how RabbitMQ can boost your system’s efficiency and reliability in these practical scenarios. Understanding RabbitMQ as a Message Broker RabbitMQ is a powerful message broker that enables applications to communicate by efficiently directing messages from producers to their intended consumers. What is a Message Queue?
Developers need efficient methods to store, traverse, and query these relationships. When using relational databases, traversing relationships requires expensive table JOIN operations, causing significantly increased latency as table size and query complexity grow. Enter graph databases. Bringing it all together.
It has become a de facto standard for perceptual quality measurements within Netflix and, thanks to its open-source nature , throughout the video industry. This enables us to use our scale to increase throughput and reduce latencies. Here, based on the video length, the throughput and latency requirements, available scale etc.,
The net result is, for many datasets, vastly more efficient use of RAM. and can achieve orders of magnitude more efficient data access, which opens up many possibilities. Traditional Hollow usage The problem with this total-source-of-truth iteration model is that it can take a long time.
To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
Therefore, dumps are needed to capture the full state of a source. There are several opensource CDC projects, often using the same underlying libraries, database APIs, and protocols. We want to support these systems as a source so that they can provide their data for further consumption.
Therefore, dumps are needed to capture the full state of a source. There are several opensource CDC projects, often using the same underlying libraries, database APIs, and protocols. We want to support these systems as a source so that they can provide their data for further consumption.
This separation aims to streamline transaction write logging, improving efficiency and consistency. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. Who can benefit from DLV? Get in touch
They can also bolster uptime and limit latency issues or potential downtimes. Choosing the Right Cloud Services Choosing the right cloud services is crucial in developing an efficient multi cloud strategy.
The results will help database administrators and decision-makers choose the right platform for their performance, scalability, and cost-efficiency needs. Network Latency : We ran both machines in the same region and conducted the tests from within the same box in that region.
Three years ago, as part of our AWS Fast Data journey we introduced Amazon ElastiCache for Redis , a fully managed in-memory data store that operates at sub-millisecond latency. All these capabilities are available to customers at no additional charge, and maintain open-source Redis compatibility.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. In the future we plan to decouple anomaly and changepoint logic from our test infrastructure and offer it as a standalone open-source library. and often before they are even committed to the codebase.
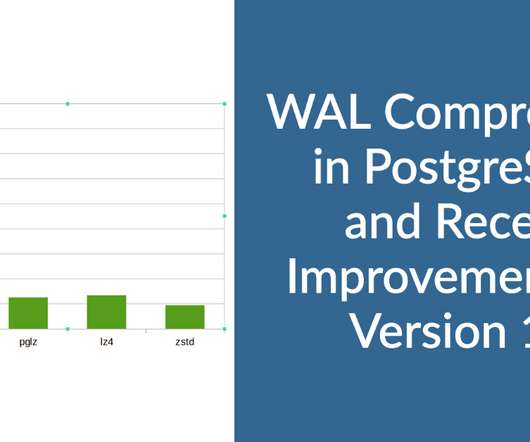
Individual processes generate WAL records, and latency is very crucial for transactions. Summary Some of the key points/takeaways I have from the discussion in the community and as well as in my simple tests: The compression method pglz available in the older version was not very efficient.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Ford, et al., “TCP
Efficient and apt test coverage covers all minute points & areas, that many times go neglected. Complete test coverage should include scenarios on latency, speed, security, and usability. Effective and Efficient Automation Testing requires good knowledge of the system and the creation of simple scripts.
RabbitMQ is an open-source message broker that simplifies inter-service communication by ensuring messages are effectively queued, delivered, and processed across diverse applications. RabbitMQ’s adherence to open standard protocols, support for various messaging protocols, and flexible message delivery mechanisms add to its appeal.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content