This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For a more proactive approach and to gain further visibility, other SLOs focusing on performance can be implemented. However, it’s essential to exercise caution: Limit the quantity of SLOs while ensuring they are well-defined and aligned with business and functional objectives. In other words, where the application code resides.
A couple of years ago, my first few days on a new web performance project were always slow going. So many false starts, tedious workflows, and a complete lack of efficiency really made it difficult for me to find momentum. Of course, it’s a little more complex than that, but for this exercise it’s an incredibly reliable proxy.
Many companies combine second-generation application performance management (APM) solutions to collect and aggregate data with machine-learning-based AIOps tools that add analysis and execution. These teams need to know how services and software are performing, whether new features or functions are required, and if applications are secure.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. SLOs are a valuable tool for organizations to ensure the health and performance of their applications. This SLO enables a smooth and uninterrupted exercise-tracking experience.
As a company that’s ethos is based on a points-based system for health, by doing exercise and being rewarded with vouchers such as cinema tickets, the pandemic made both impossible tasks to do. Fermentation process: Steve Amos, IT Experience Manager at Vitality spoke about how the health and life insurance market is now busier than ever.
Analyzing user experience to ensure uniform performance after migration. Performanceefficiency. Some principles Microsoft provides across this area include: Choosing the right resources aligned with business goals that can handle the workload’s performance. PerformanceEfficiency. Reliability.
Hosted and moderated by Amazon, AWS GameDay is a hands-on, collaborative, gamified learning exercise for applying AWS services and cloud skills to real-world scenarios. It also ensures your team shares common fluency in cloud best practices, which improves collaboration and helps your company achieve a higher standard of performance.
The healthcare industry is embracing cloud technology to improve the efficiency, quality, and security of patient care, and this year’s HIMSS Conference in Orlando, Fla., These correlations help with troubleshooting issues or for optimizing performance, but in many cases, they don’t pinpoint the precise cause of the issue.
But outdated security practices pose a significant barrier even to the most efficient DevOps initiatives. Dynatrace is the leading Software Intelligence Platform, focused on web-scale cloud monitoring, delivering the richest, most complete data sets in the Application Performance Management market.
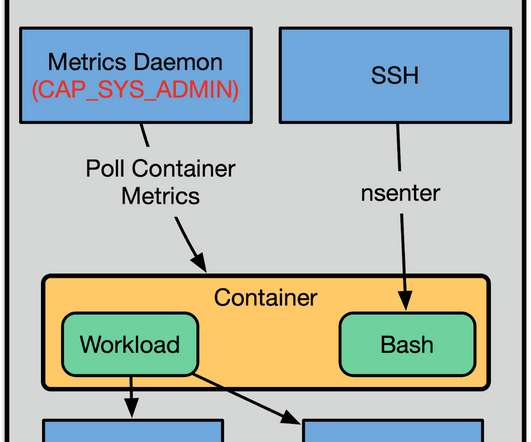
This abstraction allows the compute team to influence the reliability, efficiency, and operability of the fleet via the scheduler. We do this for reliability, scalability, and efficiency reasons. Various pieces of software used elevated capabilities for FUSE, low-level packet monitoring, and performance tracing amongst other use cases.
Who performed it? Dynatrace can efficiently rote the problem to the teams that can solve it without disturbing anyone else. Create a new VM for this exercise and install a Dynatrace OneAgent. On its own, Davis has an excellent picture of the technical environment (Kubernetes clusters, serverless functions, VMs, and so on).
This post was co-authored by Jean-Louis Lormeau, Digital Performance Architect at Dynatrace. . You’ll learn how to create production SLOs, to continuously improve the performance of services, and I’ll guide you on how to become a champion of your sport by: Creating calculated metrics with the help of multidimensional analysis.
Service level objectives (SLOs) provide a powerful framework for measuring and maintaining software performance, reliability, and user satisfaction. Teams can build on these SLO examples to improve application performance and reliability. This SLO enables a smooth and uninterrupted exercise-tracking experience.
We then used simple thought exercises based on flipping coins to build intuition around false positives and related concepts such as statistical significance, p-values, and confidence intervals. In this post, we’ll do the same for false negatives and the related concept of statistical power.
Finally, the device receives the message, and the action, such as “Show me Stranger Things on Netflix”, is performed. Where aws ends and the internet begins is an exercise left to the reader. With these clear benefits, we continued to build out this functionality for more devices, enabling the same efficiency wins.
Functional Testing Functional testing was the most straightforward of them all: a set of tests alongside each path exercised it against the old and new endpoints. Some of this increased latency was mitigated by better observability and more efficient batching of requests.
It can be a nightmare to work efficiently. This greatly reduces the number of bugs and improves the overall health and performance of every application that uses the design system. Hawkins is the namesake that established the basis for a design system used across the Netflix Studio ecosystem. This would allow for an easy migration.
The ability to run certain processes 24/7/365 created new efficiencies and risks alike. The efficiencies were double-edged: Automating one process might overwhelm downstream processes that were still done by hand. Managing the new risks required everyone to exercise new discipline.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Practitioners use APM to ensure system availability, optimize service performance and response times, and improve user experiences. Application performance management.
This incredible power is available for anyone to use in the usual pay-as-you-go model, removing the investment barrier that has kept many organizations from adopting GPUs for their workloads even though they knew there would be significant performance benefit. with a peak performance of 4.701 PetaFLOPS.
Efficiency, not human flourishing, is maximized. Governance is not a “once and done” exercise. There is no perfectly efficient algorithm that gets everything right. And much as Bostrom feared, we have given them an overriding command: to increase corporate profits and shareholder value. But there’s another factor too.
Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues. They reported a performance impact as low as 0.3% and finding over 1000 bugs, including security-critical ones.
From failure injection testing to regularly exercising our region evacuation abilities, Netflix engineers invest a lot in ensuring the services that comprise Netflix are robust and reliable. CORE is a team consisting of Site Reliability Engineers, Applied Resilience Engineers, and Performance Engineers.
I also love his efficient and eloquent writing style. It has excellent performance, and there’s quite a lot that you can learn from it. Evaluating earlier solutions, one of the important factors in getting good performance was the ability to employ batch processing. I love Paul White ’s work. Well, he did , and it’s fascinating!
The unstated assumption behind this discussion is that, if we don’t reduce the workforce as routine tasks get taken over by machines, we need to re-skill them so that they can move into other parts of the institution and perform a different set of tightly specified and highly standardized tasks. We all have muscles as humans.
This month, I'm going to start exploring the submitted solutions, roughly, going from the worse performing to the best performing ones. Why even bother with the bad performing ones? This article is dedicated to this poor performing approach. Despite the poor performance, working on the solution is an interesting exercise.
I haven’t had to optimize cppfront much yet because it’s been fast in all my uses, but Max Sagebaum exercised metafunctions heavily for @regex (covered below, in 0.7.2) and made me find another ~100x performance improvement (thanks Max!). Faster compile time when doing heavy reflection and code generation. Thanks, Max!
Teaching rigorous distributed systems with efficient model checking Michael et al., Enabling students to build running performant versions of all of those systems in the time available is one challenge. Consider the lab exercise to implement Paxos. EuroSys’19. 175 undergraduates a year currently go through this course.
Performance is one of the essential aspects of a database management system. Very little can be more annoying and frustrating for users than poor performance, meaning long-running queries and high response times at the front end. In PostgreSQL, there are different ways it can leverage the indexes to produce the most efficient plan.
Data viz solutions are consistent with its purpose; a good balance between efficiency and complexity; Color palette. Talking to users” is like exercising or eating healthy — everyone knows they should do more of it, but few actually do it. Red, for instance, is often associated with danger, failure, and poor performance.
Of course we can always throw more disk at a table, but I wanted to see if we could scale this more efficiently than the current linear trend. Note that I am not focusing on reporting workload or other read query performance at this time – I merely want to see what impact I can have on storage (and memory) footprint of this data.
Or worse yet, sometimes I get questions about regaining normal operations after a traffic increase caused performance destabilization. Unfortunately, this topic is more of an art than a science, given that there is really no foolproof algorithm or approach that can tell you exactly where you might hit a bottleneck with server performance.
but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise. The workflow orchestrator needs to perform a seemingly simple task: given a workflow or DAG definition, execute the tasks defined by the graph in order using the compute layer. Foundational Infrastructure Layers.
For each database that has pages in the buffer pool, there is a hash list of pages, in page ID order, that’s quickly searchable to determine whether a page is already in memory or whether a physical read has to be performed. Neither index is memory resident: the compiled plan take over 3.5 times longer.
Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? If I am analyzing (apparent) performance shortfalls, how can I distinguish between cause and effect ? The processor hardware available to support shared-memory transport.
Bandwidth, performance analysis has two recurring themes: How fast should this code (or “simple” variations on this code) run on this hardware? If I am analyzing (apparent) performance shortfalls, how can I distinguish between cause and effect ? The processor hardware available to support shared-memory transport.
On a humorous note, O(N) remains O(N) no matter how hard we try to make it efficient: MyAssert( std::is_sorted( std::execution::par, begin(s), end(s) ) ); // still O(N) arbitrarily expensive, but good try! What does the answer to Question 1 imply for assertion checking?
Site performance is potentially the most important metric. The better the performance, the better chance that users stay on a page, read content, make purchases, or just about whatever they need to do. With all of this in mind, I thought improving the speed of my own version of a slow site would be a fun exercise. Lighthouse.
The distribution operation was built on efficiencies: fill delivery trucks to a minimum of 80% capacity and deliver products to customers on routes optimized for time and energy consumption. Distribution is about efficiency, because efficiency translates into price.
A value-generative investment is a roll of the dice that, say, a new market opportunity can be developed or a cost efficiency can be made where none was possible before. A value-generative investment is an exercise in deploying risk capital through IT in the pursuit of extraordinary benefit that yields competitive advantage.
Otherwise, you’ll either get the implicitly generated move functions, or else requests to move will automatically just do a copy instead, since copy is always a valid implementation of move (it just doesn’t exercise the non- const option). Can a given type document that moving from an object always changes its state?
Large projects like browser engines also exercise governance through a hierarchy of "OWNER bits," which explicitly name engineers empowered to permit changes in a section of the codebase. But is HR cost efficiency for Apple the most important feature of a web engine? decoding="async" loading="lazy" />. " pantomime.
That is, does SQL Server perform a substitution process whereby it converts the original nested code into one query that goes directly against the base tables? Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. Figure 5: Plan for Query 5.
This post presents a few guiding principles to understand before undertaking a restructuring exercise. Tools can make good behaviours more efficient, but tools alone don’t introduce good behaviours in the first place. Culturally, make clear that an outstanding individual performance is a hollow (and dubious) victory in a failed team.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content