This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs).
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. This process can also be used to track the provenance of increments.
Business processes support virtually all aspects of an organizations operations. Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all? With over 2.5
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
A business process is a collection of related, usually structured tasks or steps, performed in sequence, that achieve a defined business goal. Tasks may be manual or automatic, and many business processes will include a combination of both. Make better decisions by providing managers with real-time data about the business.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
Adding Dynatrace runtime context to security findings allows smarter prioritization, helps reduce the noise from alerts, and focuses your DevSecOps teams on efficiently remedying the critical issues affecting your production environments and applications.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Static Threshold: This approach defines a fixed threshold suitable for well-known processes or when specific threshold values are critical.
That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines. By integrating Dynatrace with GitHub Actions, you can proactively monitor for potential issues or slowdowns in the deployment processes.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is RabbitMQ? What is Apache Kafka?
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
Costs and their origin are transparent, and teams are fully accountable for the efficient usage of cloud resources. Our comprehensive suite of tools ensures that you can extract maximum value from your billing data, efficiently turning insights into action. Figure 4: Set up an anomaly detector for peak cost events.
There are three high-level steps to set up the database business-event stream. Step-by-step: Set up a custom MySQL database extension Now we’ll show you step-by-step how to create a custom MySQL database extension for querying and pushing business data to the Dynatrace business events endpoint. Don’t rename the file.
Recent platform enhancements in the latest Dynatrace, including business events powered by Grail™, make accessing the goldmine of business data flowing through your IT systems easier than ever. Business events can come from many sources, including OneAgent®, external business systems, RUM sessions, or log files.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Check out the guide from last year’s event. These are just some of the topics being showcased at Perform 2023 in Las Vegas.
Consolidate real-user monitoring, synthetic monitoring, session replay, observability, and business process analytics tools into a unified platform. Real-time customer experience remediation identifies and informs the organization about any issues and prevents them in the experience process sooner.
The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs). These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system.
Getting the information and processes in place to ensure alerts like this example can be organizationally difficult. However, Dynatrace can often miss crucial pieces of the puzzle because humans haven’t told it about whole processes occurring on the “human” side of the environment. Offline processes.
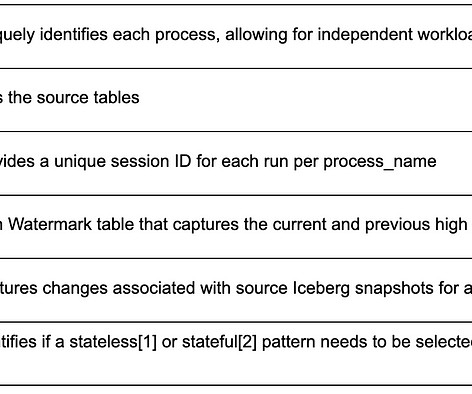
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions.
Unlike a traditional virtual machine-model where customers must build and manage an entire VM, serverless computing provides the ability to purchase only the CPU cycles and memory needed to support an application using an event-based pay-per-use model. The Serverless Process. Services scale to meet demand.
Among the spectrum of methodologies available for this task, batch processing is often considered an old guard, especially with the advent of real-time and event-based processing technologies. However, it would be a mistake to dismiss batch processing as an antiquated approach.
This leads to a more efficient and streamlined experience for users. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams.
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Understanding the context. Addressing security requirements.
The Dynatrace solution Dynatrace addresses these issues by providing unified security event ingest and analysis for security findings across tools and products. Harbor vulnerability findings and audit logs are fetched periodically and pushed to Dynatrace via a dedicated security event ingest endpoint.
Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards. This efficient method allows you to easily browse and identify the appropriate metrics; adding them to your notebooks and dashboards requires just a single click.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Proper setup involves creating a configuration process that accounts for hostname changes, which could prevent nodes from rejoining the cluster.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
As Netflix expanded globally and the volume of title launches skyrocketed, the operational challenges of maintaining this manual process became undeniable. This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient.
Many modern applications have a batch processing aspect to them and regularly run high-volume, repetitive data jobs. If you use the cloud and cloud-native technologies like Kubernetes, this area offers a great opportunity for cost optimization through approaches like event-driven autoscaling and spot instance automation.
In order to allow for this mimicking, many systems implement an event handling, where they convert our request into a call to the real service with properties enabled to log when titles are filtered out of their response and why. As a result, requests are uniformly handled, and responses are processed cohesively.
This approach improves operational efficiency and resilience, though its not without flaws. Additionally, predictions based on historical data are reactive, solely relying on past information to anticipate future events, and can’t prevent all new or emerging issues. These algorithms are not limited to monitoring IT environments.
We want to share how Dynatrace helped us identify and fix memory leaks in one of the most central and critical components within Keptn: our event broker. We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. It happened in June 2020. Houston, we have a problem!
One issue that often complicates this process is the "noisy neighbor" problem. Continuous instrumentation is critical to catching such matters as they emerge, and eBPF, with its hooks into the Linux scheduler with minimal overhead, enabled us to monitor run queue latency efficiently.
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. Managing incidents in corresponding tools. Identifying the root cause and proper countermeasures.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. To achieve these AIOps benefits, comprehensive AIOps tools incorporate four key stages of data processing: Collection. Aggregation. Enhanced automation.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Customers have had a positive response to our native syslog implementation, noting its easy setup and efficiency.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
This causal inference design involves a systematic framework we designed to measure game events that relies on synthetic control ( blogpost ). Each format has a different production process and different patterns of cash spend, called our Content Forecast. A sizable portion of our Content Forecast is represented by TBDSlots.
Process Improvements (50%) The allocation for process improvements is devoted to automation and continuous improvement SREs help to ensure that systems are scalable, reliable, and efficient. The Dynatrace integration leverages native features and events that pass through the pipeline.
Dynatrace does this by automatically creating a dependency map of your IT ecosystem, pinpointing the technologies in your stack and how they interact with each other, including servers, processes, application services, and web applications across data centers and multicloud environments. asc | fields `Host`, `Recently Restarted?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content